测试环境:
主节点:81.69.247.195
从节点:124.71.182.20
linux:centos6.5
主:
1.
编辑 vim /etc/my.cnf
添加:log-bin = mysql-bin
添加 :server-id =1
添加:innodb-file-per-table =ON
添加:skip_name_resolve=ON
2.
重启mysql:service mysqld restart
3.进入mysql:mysql -u root -p
4.查看二进制信息:
show global variables like '%log%';
5.查看主节点二进制日志列表
show master logs;
6.查看主节点的server id
show global variables like '%server%';
7.在主节点上创建有复制权限的用户。REPLIACTION SLAVE ,REOPLIATION CLIENT
grant replication slave,replication client on *.* to 'admin'@'124.71.182.20' identified by '123456';
8.刷新
flush privileges;
从:
1.
编辑 vim /etc/my.cnf
添加:relay-log=relay-log
添加:relay-log-index=relay-log.index
添加:server-id=2
添加:innodb_file_per_table=ON
添加:skip_name_resolve=ON
2.重启mysql:service mysqld restart
3.进入mysql:mysql -u root -p
4.查看二进制信息是否开启:
show global variables like '%log%';
5.产看server 相关信息
show global variables like '%server%';
6.在从节点配置访问主节点的参数信息
添加 主节点主机,访问主节点的用户名及密码,主节点二进制文件信息。
注意:主节点的二进制文件一定要是二进制列表中的最后一个二进制文件。
CHANGE MASTER TO MASTER_HOST='81.69.247.195',MASTER_USER='admin',MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin.000009',MASTER_LOG_POS=430;
7.因为没有启动 从节点的复制线程,IO线程 和 SQL 线程都为NO.
show slave status\g;
启动:start slave;
测试:
在主上创建数据库并查看二进制信息:
create database test charset 'utf8';
show master status;
在从节点查找二进制日志信息,并查看mydb数据库是否复制成功
show slave status\G;
基本命令:
stop slave;
SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1; START SLAVE;
show slave status\GIssues that should be noted in the master-slave replication architecture:
The slave node must set certain restrictions so that it cannot perform write operations to ensure that the data in the replication is consistent.
1: Restrict the slave server to read-only
. Set on the slave server:
read_only = ON, but this restriction is invalid for users with SUPER privileges.
Block all users:
mysq>FLUSH TABLES WITH READ LOCK;
2: How to ensure the safety of things during master-slave replication?
1: Set the parameter
sync_binlog=1 on the master node : When Mysql opens the bin-log log and uses bin-log, by default, it is not synchronized with the hard disk every time a write is executed. This may cause bin-log when the server crashes. The last statement of log is lost. It can be adjusted by this parameter, sync_binlog=N, to synchronize with the hard disk after performing N writes. 1 is the safest, but also the slowest.
If the innode storage engine is used:
innodb_flush_logs_at_trx_commit=ON ( flush log: when the transaction is committed, the transaction-related data in the memory should be flushed to the transaction log immediately.)
innodb_support_xa=ON (distributed transaction: based on it Do two-stage submission function)
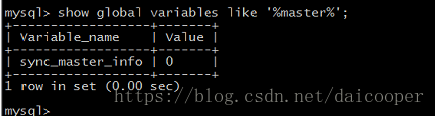
sync_master_info=1: Every time after dumping some event information to the slave node, the master info information of the master node will be synchronized to the disk immediately. Let the master_info in the slave server be updated in time.
2: On each slave node
skip_slave_start = ON (Skip the automatic start, use manual start.) The
relay_log will be cached in it first, and then synchronized to the relay_log, you can use the following parameters to make it synchronized immediately.
sync_relay_log =1, the default is 10000, that is, every 10000 sync_relay_log events will be flushed to the disk. If it is 0, it means no refresh, and it is controlled by the OS cache.
sync_relay_log_info = 1 How many transactions refresh relay-log.info every interval , if the table (innodb) setting is invalid, every transaction will be updated
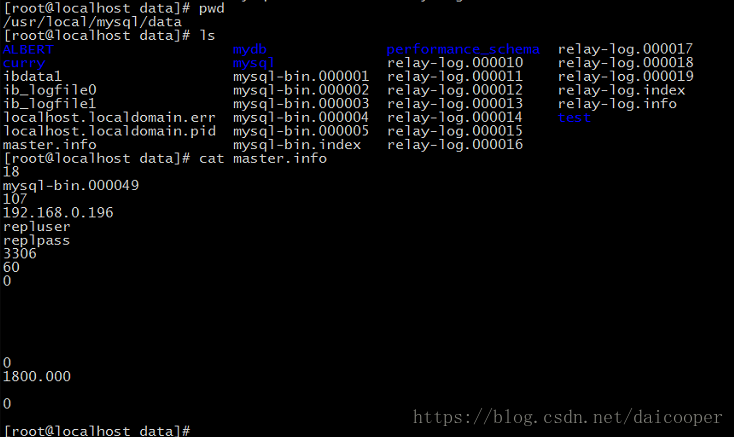
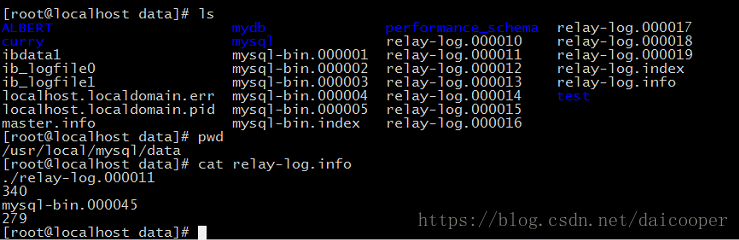
Note: In the slave node, master.info is a file recorded in the copy location of the master node.
relylog_info: Locally, in the future as to which binary file of the master node will position and which postion in which relay log to save the text. When the slave node is started, the local relay-log needs to be located according to relay-log.info.