1. Definition of Random Forest
Random forest belongs to ensemble learning. The idea of ensemble is to solve the inherent shortcomings of a single model or a model with a set of parameters, so as to integrate more models and learn from each other. Random forest is the product of ensemble learning thinking. There are many decision trees in the forest, and there is no correlation between each decision tree in the random forest. After getting the forest, when a new input sample enters, let each decision tree in the forest make a judgment separately to see which category the sample belongs to (for the classification algorithm), and then see which The one that is selected the most, predict which category the sample belongs to.
In the process of building each decision tree, there are two points to pay attention to-sampling and complete splitting. First, there are two random sampling processes. Random forest samples the input data in rows and columns. For row sampling, a replacement method is adopted , that is, there may be duplicate samples in the sample set obtained by sampling. Assuming that there are N input samples, there are also N samples sampled. In this way, during training, the input samples of each tick tree are not all samples, making it relatively difficult to overfit. Then perform column sampling, select m from M features (m << M), and then use a completely split method to build a decision tree on the sampled data, so that a certain leaf node of the decision tree cannot continue to split Yes, or all the samples in it refer to the same category. Generally, many decision tree algorithms have an important step: pruning, but random forests do not do that. Because the previous two random sampling processes ensure randomness, even if pruning is not performed, there will be no overfitting. .
Why is there replacement sampling?
If it is not sampling with replacement, then the training samples of each tree are different, and there is no intersection, so that each tree is "biased", that is to say, the model trained by each tree is The final classification of random forest depends on the voting of multiple trees (weak classifiers). This kind of voting should be “seeking the same”, so a completely different training set is used to train each tree so that the final The result is not helpful, which is tantamount to "blind people touching the elephant."
2. Principles of Random Forest Algorithm
Random forest is a derivative of Bagging algorithm in ensemble learning. In ensemble learning, it is mainly divided into bagging algorithm and boosting algorithm. Let us first look at the characteristics and differences between these two methods.
2.1 Bagging
The basic idea of Bagging algorithm
The basic idea of Bagging is to extract training examples with replacement of the training set, so as to construct a training set equal to but different from the training set for each basic classifier, thereby training different base classifiers. Finally, the base classifiers are fused to obtain the final classifier.
Bagging algorithm process
1) Randomly extract n training samples from the original sample set using the sampling method with replacement, and perform k rounds of sampling to obtain k
Training sets (k training sets are independent of each other, elements can be repeated)
2) For k training sets, we train k models
3) For the classification problem: the final result is voted by k models to produce the classification result; for the regression problem, the mean value of the prediction results of the k models is used as the final result
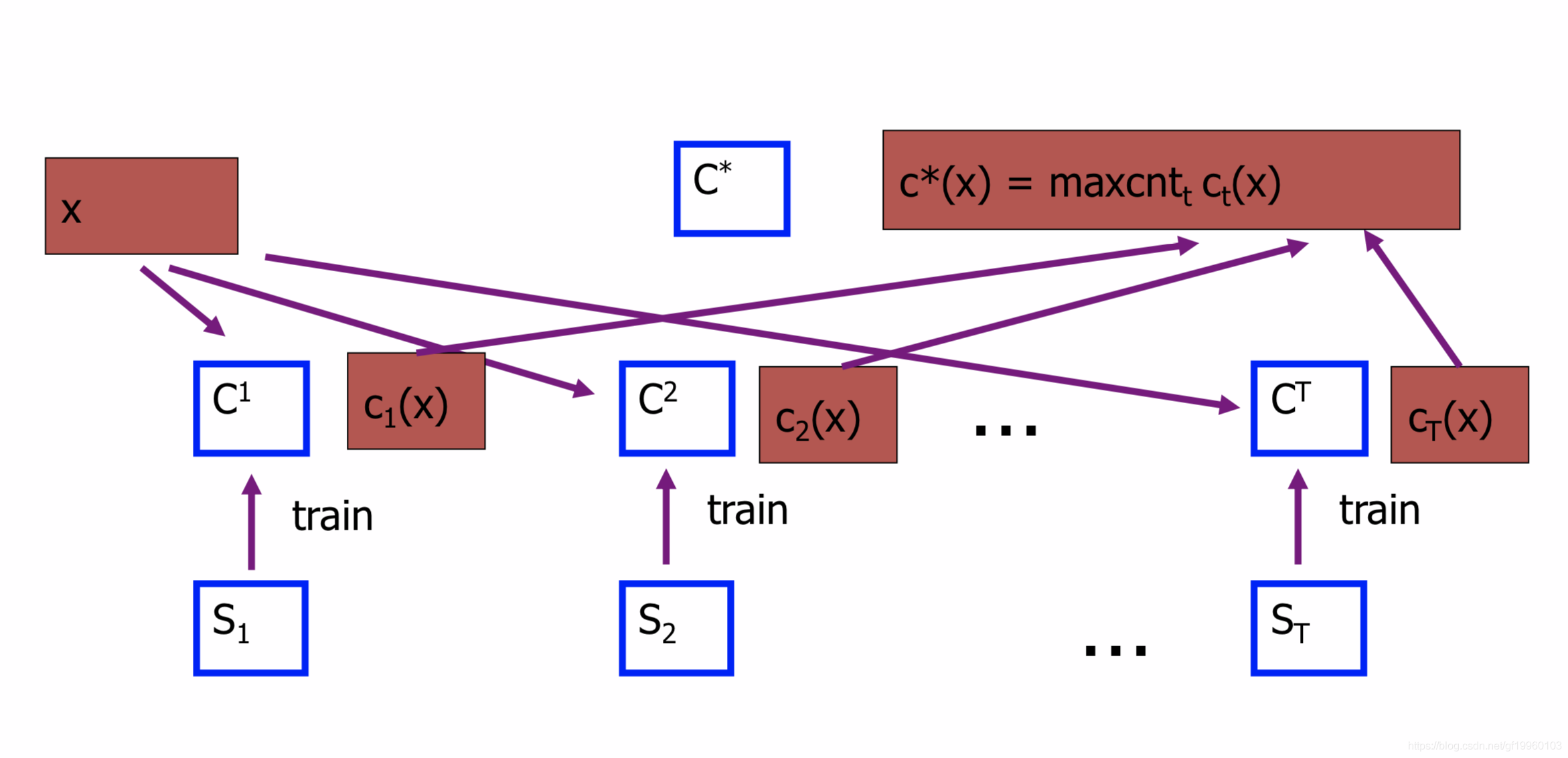
As shown in the figure above, the original data is divided into S1 to ST training sets by sampling with replacement, and T training sets are used to train T models C1(X) to CT(X), and these T The model is fused into the final model maxcont(X). When a new piece of data comes in, it will go through the comprehensive judgment of T models to get the final result.
2.2 Boosting
The basic idea of Boosting algorithm
The basic idea of Boosting is a sequential execution process, and each subsequent model will try to correct the errors of the previous model. The subsequent models all depend on the previous model.
Boosting algorithm process
1) Establish a weight wi for each sample in the training set, which represents the weight of each sample. The key is that the weight of the sample that is incorrectly classified will get a larger weight in the next round of classification (the sample that is incorrectly classified) Increased weight).
2) At the same time, increase the weight of the weak classifier with a small probability of classification error to make it play a greater role in voting, and reduce the weight of the weak classifier with a large classification error rate to make it play a role in voting. Lesser role. Each iteration gets a weak classifier, which needs to be combined using a certain strategy to make the final model.
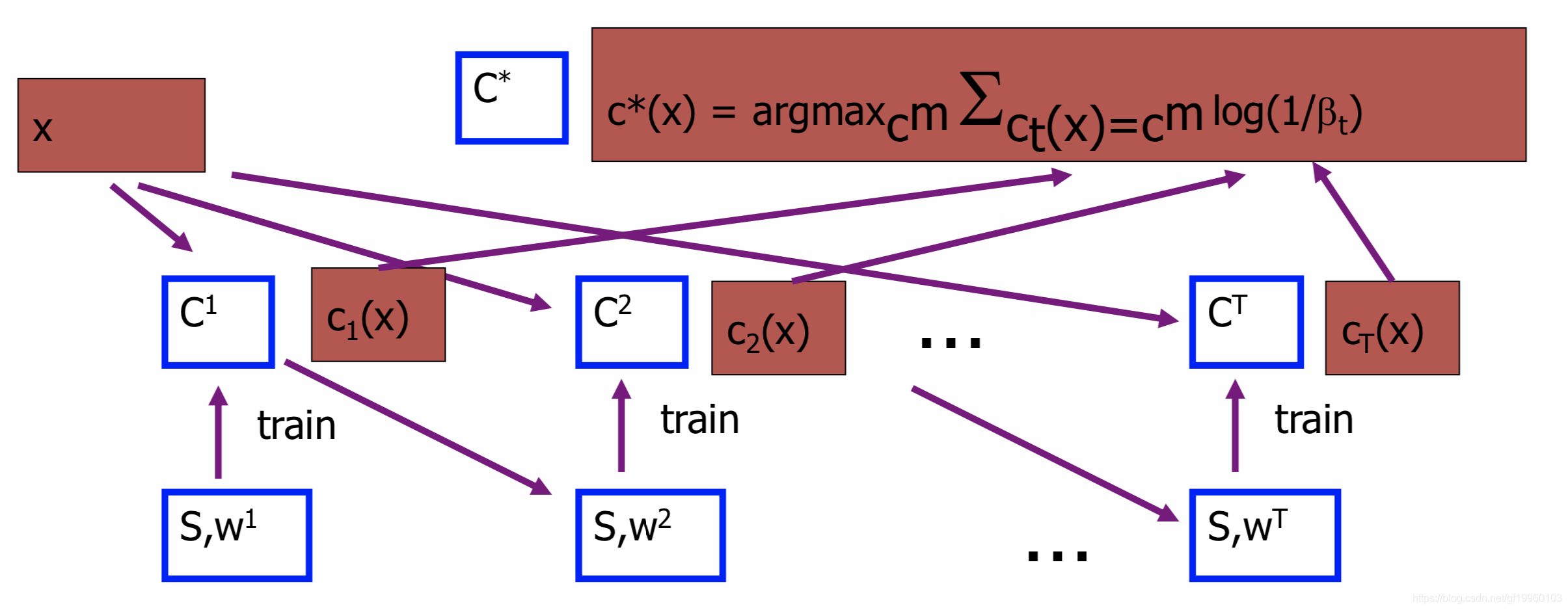
As shown in the figure above, construct a subset S from the original data set, assign the initial weight W1, train model C1 with S and W1, get weight W2, train W2 and S to get model C2, and so on, and finally all models are weighted and summed Get the final model. When a new piece of data X comes in, it will be substituted into T models, and finally weighted and summed to get the final result.
Note: Each Boosting sampling is sampling without replacement, that is, the original data distribution is not changed. The above figure S refers to the subset obtained by sampling without replacement from the original data set in each iteration.
2.3 Random Forest
Random Forest (RF) is a type of Bagging algorithm. In fact, after introducing the Bagging algorithm, Random Forest is almost ready to emerge. Compared with Bagging, RF only makes its own regulations and designs on some of the details.
[Weak classifier] First, RF uses CART decision tree as a weak learner. In other words, in fact, we just call the Bagging method that uses CART decision trees as weak classifiers as random forests.
[Randomness] At the same time, when each tree is generated, the selected features of each tree are only a few randomly selected features, and generally the root of the total number of features m is taken by default. The general CART tree will select all features for modeling. Therefore, the random selection of rows and columns of RF makes RF less prone to overfitting.
[Sample size] Compared with the general Bagging algorithm, RF will collect the same number of samples as the training set sample number N.
[Features] Due to the randomness, it is very effective in reducing the variance of the model, so random forests generally do not need additional pruning, that is, it can obtain better generalization ability and anti-overfitting ability.
3. Advantages of Random Forest
- Due to the integrated algorithm, its accuracy is better than most single algorithms
- It performs well on the test set. Due to the introduction of two randomnesses, the random forest is not easy to fall into overfitting (random samples, random features)
- In industry, due to the introduction of two randomness, random forest has certain anti-noise ability, which has certain advantages compared with other algorithms
- Due to the combination of trees, random forest can process nonlinear data, which is a nonlinear classification (fitting) model.
- It can handle data with very high dimensions (many features), and does not require feature selection. It has strong adaptability to data sets: it can handle both discrete data and continuous data, and the data set does not need to be standardized
- Fast training speed and can be used on large-scale data sets
- Can handle the default value (as a separate category) without additional processing
- Due to the out-of-bag data (OOB), an unbiased estimate of the true error can be obtained during the model generation process without losing the amount of training data
- In the training process, the mutual influence between features can be detected, and the importance of features can be derived, which has certain reference significance
- Since each tree can be generated independently and at the same time, it is easy to make a parallel method
- Due to its simple implementation, high accuracy, and strong resistance to over-fitting, it is suitable as a reference model when faced with nonlinear data
4. scikit-learnAPI parameter meaning
from sklearn.ensemble import RandomForestClassifierCommon parameters of the model:
n_estimator: the number of base classifiers, the default value is 10
criterion: the criterion for measuring attribute splitting, optional "gini" and "entropy". (For classification problems)
max_depth: The maximum depth of the tree. integer or None. If it is None, the node expands until all leaves are pure or the number of samples contained in all leaf nodes is less than min_samples_split . Default is None
min_samples_split: The minimum number of samples required for internal node division. The default is 2
min_samples_leaf: The minimum number of samples that should be on the leaf node, the default is 1
max_feature: the number of attributes considered when searching for the best split point, default "auto"
oob_score: Whether to judge model accuracy by out-of-bag samples, the default is False
n_jobs : Set the number of tasks executed in parallel in the fit and predict phases. If set to -1, the number of tasks executed in parallel is equal to the number of computing-level cores; [integer, optional (default=1)]
Common attributes of the model:
feature_importances_: returns the weight of each attribute
oob_score_: Use out-of-bag samples to evaluate the score of the model