After the Map method, the data processing process before the Reduce method is called Shuffle. This article mainly introduces the related content of Shuffle. Follow the column "Broken Cocoon and Become a Butterfly-Hadoop" to view related series of articles~
table of Contents
2.2.2 Writing a partition class
Three, WritableComparable sort
3.2 Custom WritableComparable sorting to achieve full sorting
3.2.2 Write Bean class and implement WritableComparable class
3.3 Custom WritableComparable sorting to achieve regional sorting
Five, GroupingComparator grouping
One, Shuffle process
Detailed explanation of the specific Shuffle process: (1) MapTask collects the kv pairs output by our map() method and puts them in the memory buffer. (2) The local disk file is continuously overflowed from the memory buffer, and multiple files may be overflowed. (3) Multiple overflow files will be merged into a large overflow file. (4) During the overflow process and the merge process, Partitioner must be called to partition and sort keys. (5) ReduceTask according to its own partition number, go to each MapTask machine to get the corresponding result partition data. (6) ReduceTask will fetch the result files from different MapTasks in the same partition, and ReduceTask will merge these files again (merge and sort). (7) After merging into a large file, the Shuffle process is over, and then it enters the logical operation process of ReduceTask (take out a key-value pair Group from the file and call the user-defined reduce() method).
The size of the buffer in Shuffle will affect the execution efficiency of the MapReduce program. In principle, the larger the buffer, the fewer the number of disk io and the faster the execution speed. The size of the buffer can be adjusted by parameters. The parameter: io.sort.mb is 100M by default.
Two, partition
2.1 Introduction to Partition
You can use partitions to output different statistical results of data to different partitions. It should be noted here: (1) If the number of ReduceTasks is greater than the number of partitions, several empty output files will be generated, namely part-r-000xx; (2) If the number of ReduceTasks is less than the number of partitions (the number of ReduceTasks is greater than One), there will be a part of the partition data that is nowhere to be output, and an exception will be reported at this time; (3) If the number of ReduceTask is one, no matter how many partition files are output by the MapTask side, the final result will be given to this ReduceTask, and finally A part-r-00000 file will also be formed; (4) The partition number must start from zero and accumulate one by one.
2.2 Partition case
2.2.1 Requirements and data
The data is the data of the example in "X. Hadoop Serialization" , that is, the log data of Nginx. The requirements are: the first two digits of the ip address are 10, 60, 22, and 11, respectively, placed in different partitions, and the others are placed separately In one partition.
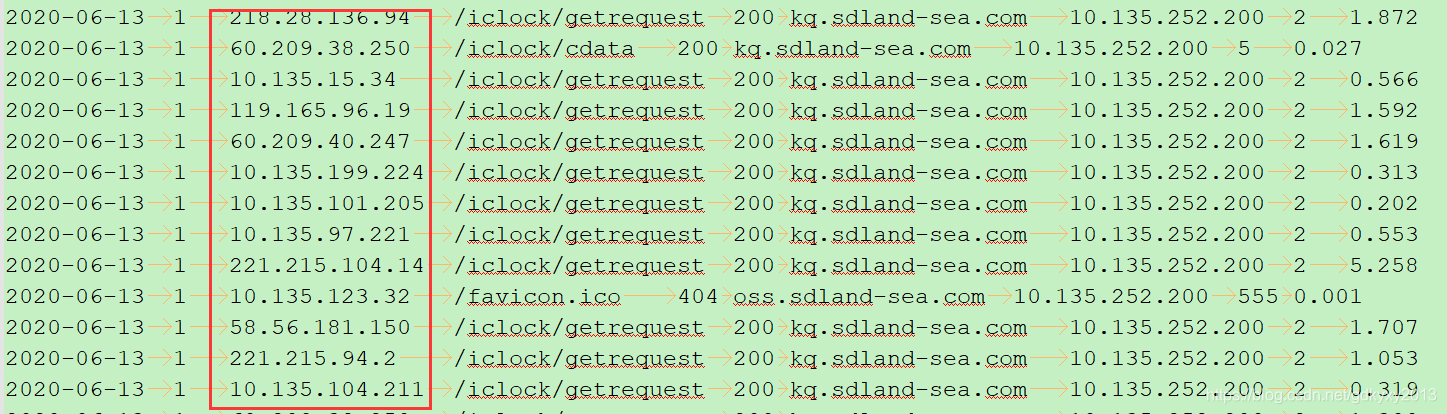
2.2.2 Writing a partition class
The partition at this time only needs to add a partition class to the example in "X. Hadoop Serialization" , as shown below:
package com.xzw.hadoop.mapreduce.nginx;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author: xzw
* @create_date: 2020/8/8 14:26
* @desc: ip地址前两位10/60/22/11分别放在一个分区中,其他的放在另外一个分区中
* @modifier:
* @modified_date:
* @desc:
*/
public class NginxPartitioner extends Partitioner<Text, NginxBean> {
public int getPartition(Text key, NginxBean value, int numPartitions) {
//1、获取ip地址前两位
String ip = key.toString().substring(0, 2);
//2、判断,进行分区
if ("10".equals(ip)) {
return 0;
} else if ("60".equals(ip)) {
return 1;
} else if ("22".equals(ip)) {
return 2;
} else if ("11".equals(ip)) {
return 3;
}
return 4;
}
}
2.2.3 Change the driver class
Add the following content to the Driver driver class of the previous example:
//添加分区相关设置
job.setPartitionerClass(NginxPartitioner.class);
//指定响应数量的reduce task
job.setNumReduceTasks(5);2.2.4 Test
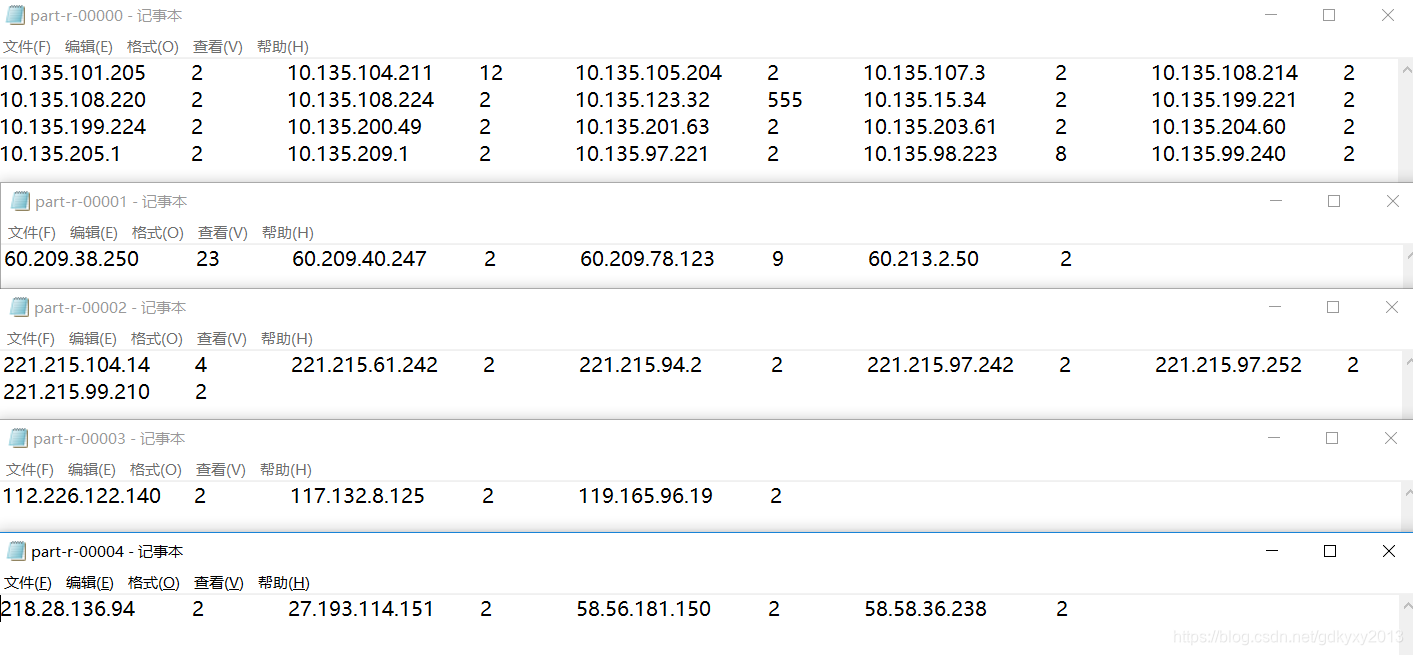
First, let's take a look at the result when no partition is added, and expect to output a part-r-00000.


Next, is the result after adding the partition:

Three, WritableComparable sort
3.1 Overview of sorting
Sorting is one of the most important operations in the MapReduce framework. Both MapTask and ReduceTask sort the data according to Key. This operation belongs to the default behavior of Hadoop. The data in any application will be sorted, regardless of whether it is logically necessary. The default sort is lexicographically sorted and the method to achieve this sort is quick sort.
For MapTask, it temporarily puts the processed results in the ring buffer. When the usage of the ring buffer reaches a certain threshold, it quickly sorts the data in the buffer and overflows the ordered data to the disk. , And when the data is processed, it will merge and sort all the files on the disk. For ReduceTask, it obtains the corresponding data file from each MapTask. If the file size exceeds a certain threshold, it will overflow to the disk, otherwise it will be stored in the memory. If the number of files on the disk reaches a certain threshold, a merge sort is performed to generate a larger file. If the size or number of files in the memory exceeds a certain threshold, the data will be overwritten to the disk after a merge. When all the data is copied, ReduceTask will merge and sort all the data in the memory and disk.
3.2 Custom WritableComparable sorting to achieve full sorting
3.2.1 Requirements and data
Requirements: Sort the total size in descending order according to the results of the example in "Ten. Hadoop Serialization" :
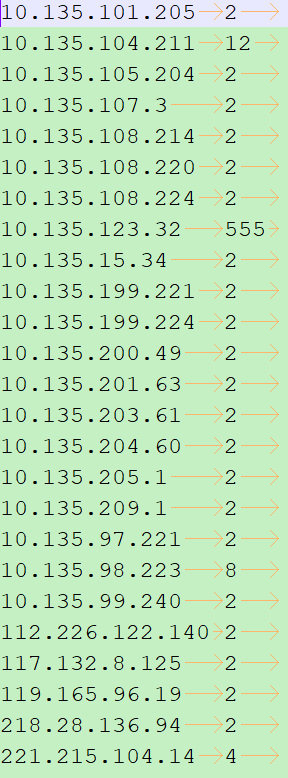
3.2.2 Write Bean class and implement WritableComparable class
package com.xzw.hadoop.mapreduce.writablecomparable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/7/28 10:01
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class NginxBean implements WritableComparable<NginxBean> {
private long size;//size
//反序列化时,需要反射调用空参构造器,所以必须有空参构造器
public NginxBean() {
}
public void set(long size) {
this.size = size;
}
public long getSize() {
return size;
}
public void setSize(long size) {
this.size = size;
}
/**
* 序列化方法
* @param dataOutput
* @throws IOException
*/
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(size);
}
/**
* 反序列化方法:反序列化方法读取顺序必须跟序列化方法写顺序一致
* @param dataInput
* @throws IOException
*/
public void readFields(DataInput dataInput) throws IOException {
this.size = dataInput.readLong();
}
/**
* 编写toString方法,方便后续打印到文本
* @return
*/
@Override
public String toString() {
return size + "\t";
}
public int compareTo(NginxBean o) {
return Long.compare(o.size, this.size);
}
}
3.2.3 Write Mapper Class
package com.xzw.hadoop.mapreduce.writablecomparable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/8 15:18
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class NginxSortMapper extends Mapper<LongWritable, Text, NginxBean, Text> {
NginxBean k = new NginxBean();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String ip = fields[0];
long size = Long.parseLong(fields[1]);
k.set(size);
v.set(ip);
context.write(k, v);
}
}
3.2.4 Write the Reducer class
package com.xzw.hadoop.mapreduce.writablecomparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/8 15:19
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class NginxSortReducer extends Reducer<NginxBean, Text, Text, NginxBean> {
@Override
protected void reduce(NginxBean key, Iterable<Text> values, Context context) throws IOException,
InterruptedException {
for (Text value: values) {
context.write(value, key);
}
}
}
3.2.5 Write Driver class
package com.xzw.hadoop.mapreduce.writablecomparable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/8 15:19
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class NginxSortDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"e:/output", "e:/output1"};
Job job = Job.getInstance(new Configuration());
job.setJarByClass(NginxSortDriver.class);
job.setMapperClass(NginxSortMapper.class);
job.setReducerClass(NginxSortReducer.class);
job.setMapOutputKeyClass(NginxBean.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NginxBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
3.2.6 Test
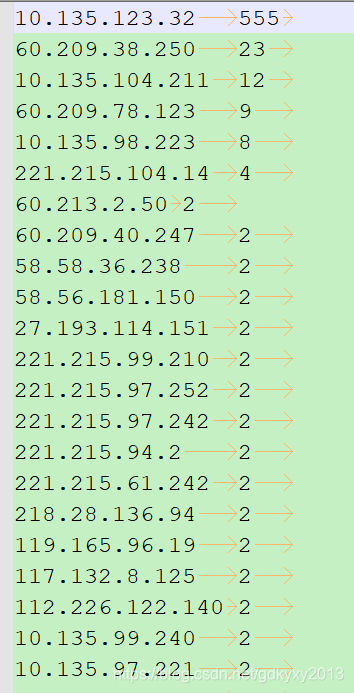
3.3 Custom WritableComparable sorting to achieve regional sorting
Based on 3.2, you only need to add the Partitioner class at this time, as shown below:
package com.xzw.hadoop.mapreduce.writablecomparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author: xzw
* @create_date: 2020/8/8 14:26
* @desc: ip地址前两位10/60/22/11分别放在一个分区中,其他的放在另外一个分区中
* @modifier:
* @modified_date:
* @desc:
*/
public class NginxSortPartitioner extends Partitioner<NginxBean, Text> {
@Override
public int getPartition(NginxBean key, Text value, int numPartitions) {
//1、获取ip地址前两位
String ip = value.toString().substring(0, 2);
//2、判断,进行分区
if ("10".equals(ip)) {
return 0;
} else if ("60".equals(ip)) {
return 1;
} else if ("22".equals(ip)) {
return 2;
} else if ("11".equals(ip)) {
return 3;
}
return 4;
}
}
Add the following content in the Driver class:
job.setPartitionerClass(NginxSortPartitioner.class);
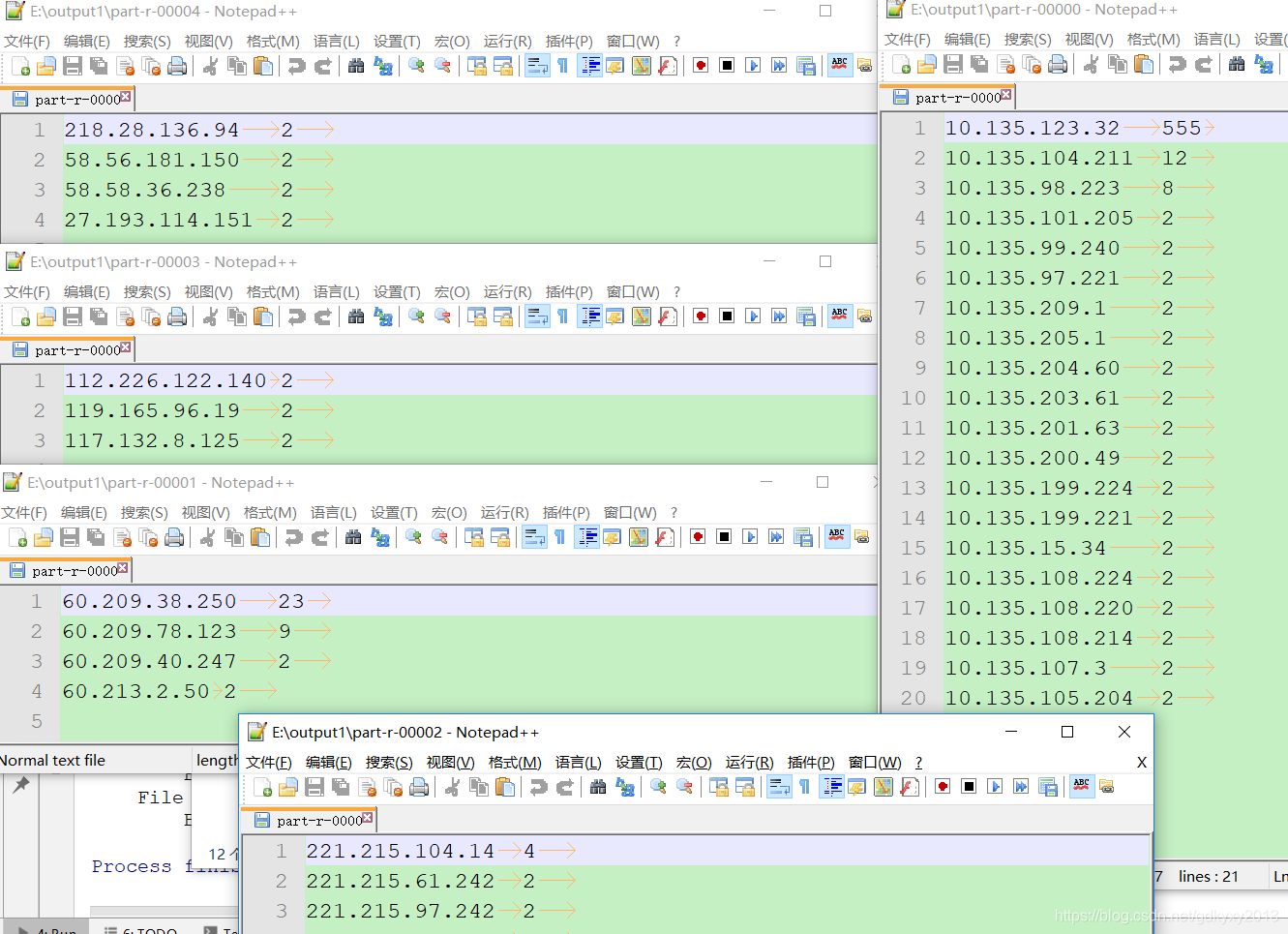
job.setNumReduceTasks(5);Test again, the results are as follows:
Four, Combiner merger
4.1 Introduction to Combiner
Combiner is a component of MapReduce program except Mapper and Reducer. Its parent class is Reducer, and the difference between it and Reducer is where it runs. Combiner runs on the node where each MapTask is located, and Reducer receives the output results of all Mappers globally. The meaning of Combiner is to locally summarize the output of each MapTask to reduce the amount of network transmission. The premise that Combiner can be applied is that it cannot affect the final business logic, and the output KV of Combiner should correspond to the input KV type of Reducer.
4.2 Combiner example
4.2.1 Requirements and data
To achieve the WordCount of data, the ultimate goal is to reduce the amount of network transmission. The data is as follows (for relevant code, please refer to the WordCount example in "Nine, Hadoop Core Components of MapReduce" ):
4.2.2 Test
First run the program when the Combiner is not set, and check the network transmission volume as follows:

Add the following code to the Driver class and test again:
job.setCombinerClass(WcReducer.class);
Five, GroupingComparator grouping
The significance of this grouping is to group the data in the Reducer stage according to one or several fields. Let's describe it with an example.
5.1 Requirements
The following data is available, the three columns are: order id, product id and transaction amount.

Currently, we need to request the most expensive item in each order.
Analysis: Group each order, output in descending order, and then take the first data.
5.2 Writing Bean Class
package com.xzw.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/8 16:41
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderBean implements WritableComparable<OrderBean> {
private String orderId;
private String productId;
private double price;
@Override
public String toString() {
return orderId + "\t" + productId + "\t" + price;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getProductId() {
return productId;
}
public void setProductId(String productId) {
this.productId = productId;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public int compareTo(OrderBean o) {//二次排序
int compare = this.orderId.compareTo(o.orderId);
if (compare == 0) {
return Double.compare(o.price, this.price);
} else {
return compare;
}
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(productId);
out.writeDouble(price);
}
@Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.productId = in.readUTF();
this.price = in.readDouble();
}
}
5.3 Writing Mapper Class
package com.xzw.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/8 16:47
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
private OrderBean orderBean = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
orderBean.setOrderId(fields[0]);
orderBean.setProductId(fields[1]);
orderBean.setPrice(Double.parseDouble(fields[2]));
context.write(orderBean, NullWritable.get());
}
}
5.4 Writing Comparator
package com.xzw.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* @author: xzw
* @create_date: 2020/8/8 16:48
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderComparator extends WritableComparator {
public OrderComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean oa = (OrderBean) a;
OrderBean ob = (OrderBean) b;
return oa.getOrderId().compareTo(ob.getOrderId());
}
}
5.5 Write Reducer
package com.xzw.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/8 16:47
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException,
InterruptedException {
context.write(key, NullWritable.get());
}
}
5.6 Write Driver
package com.xzw.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/8 16:47
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//设置输入输出路径(便于测试)
args = new String[]{"e:/input/orders.txt", "e:/output"};
Job job = Job.getInstance(new Configuration());
job.setJarByClass(OrderDriver.class);
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setGroupingComparatorClass(OrderComparator.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
5.7 Test

At this point, this article is over. What problems did you encounter in this process, welcome to leave a message, let me see what problems you encountered~