This section describes the working mechanism of Hadoop MapReduce are introduced, mainly described from MapReduce job execution processes and process aspects Shuffle. By better understanding of the working mechanism of MapReduce, developers can make the program more rational use MapReduce to solve practical problems.
Hadoop MapReduce job execution process
Hadoop MapReduce entire job execution process shown in Figure 1, is divided into 10 steps.
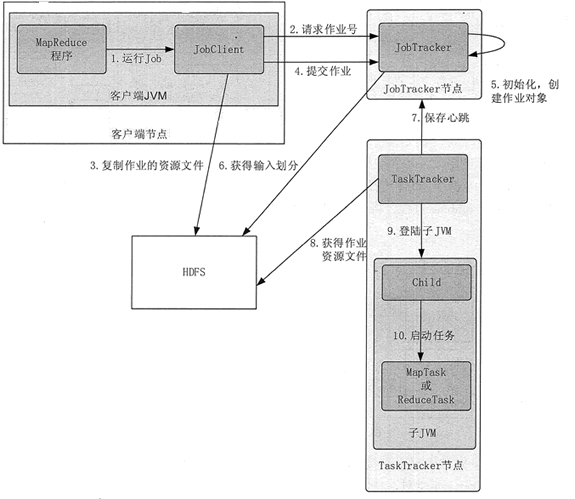
1 Hadoop MapReduce job execution process of FIG.
1. Submit job
The client submit a job to JobTracker. First, you need to configure all the parameters to be configured according to the needs. After the job is submitted, it will enter the automated execution. In this process, the user can only monitor the implementation of the program of work and forced to interrupt, but not the execution of the job of any intervention. The basic process is as follows submit jobs.
1) the client through Runjob () method to start the job submission process.
2) The client requests a new job ID by the JobTracker getNewJobId ().
3) Output Description Client inspection operation input slice peer computing operations, if there are problems, throwing an exception, if the normal, will run the resource (e.g., job Jar file, the configuration file required for the job, the calculated slicing of the input, etc.) to be copied to a directory named job ID.
4) () method tells the job is ready to execute by calling the JobTracker submitjob.
2. Initialize the job
JobTracker at the end JobTracker start initialization work, including the establishment of a series of data structures in its memory, to record the operation of this Job.
1) After receiving the calls to its JobTracker submitJob () method, the call will be put into an internal queue, the job scheduler schedules referred to. Initialization main target is to create a means running the job, in order to track the status and progress of the task.
2) In order to create a task run list, the job scheduler first acquires JobClient calculated from the HDFS good slicing of the input information, and then creates a MapTask for each slice, and creates ReduceTask.
3. Assign tasks
JobTracker will ask the HDFS file inside NameNode which relevant data in these files are scattered in which nodes inside. JobTracker need to assign tasks in accordance with the principle of "the nearest run."
TaskTracker regularly communicates with JobTracker through the "heartbeat", mainly to inform themselves whether JobTracker still alive, and whether a new task is ready to run and so on.
After JobTracker receive a heartbeat message, if the task to be dispensed, it will be assigned a task TaskTracker, and returns to the return heartbeat communication TaskTracker value allocation information package.
For the Map task, JobTracker usually choose a slice from its recent TaskTracker input for the Reduce tasks, JobTracker can not be considered a localized data.
4. Perform the task
1) After TaskTracker assigned to a task, copy files via HDFS Jar TaskTracker jobs to the file system where, at the same time, TaskTracker all the documents required for the application are copied from a distributed cache to the local disk. TaskTracker task to create a new local working directory, and the contents of the Jar file extracted to this folder.
2) TaskTracker start a new JVM to run each task (including Map tasks and Reduce tasks), so, JobClient of MapReduce does not affect TaskTracker daemon. Child process tasks every few seconds will inform the parent process its progress until the task is completed.
5. process update and status
And a job that has a status of each task, including operating state of progress of a job or task, Map and Reduce tasks task, counter values, status message, or description. Task at run time, keep track of their progress.
These messages to the aggregation TaskTracker ChildJVM, and then again converged by JobTracker certain time intervals. JobTracker produce a show that will run a global view of all jobs and their job status, user can be viewed through Web UI. JobClient to get the latest status inquiry JobTracker per second, and output to the console.
6. complete the job
When the last task JobTracker received this assignment has been completed, it will Job status changed to "successful". When JobClient get to the status of a job, you know the job has been completed successfully, and then inform the user information JobClient print job has ended successfully, the last () method returns from Runjob.
HadoopMapReduce the stage Shuffle
Shuffle stage Hadoop MapReduce means starts output from the Map, comprising performing sorting system, and transmitting outputs to Reduce Map as the process inputs.
Refers to the process of sorting phase is ended output Key Map sort. Different Map may output the same Key, Key must be sent to the same Reduce the same end treatment. Shuffle stage can be divided into stages Shuffle Shuffle phase and Reduce end of the end of the Map. Shuffle stage working process, as shown in FIG.
1. Map of the end stage Shuffle
1) each input slice Map make a task to process, by default, a size of a block of HDFS (default is 64MB) of a slice. Map function produces an output when the start, not simply write the data to disk, because of frequent disk operations will result in severe performance degradation. It processes the data is first written to a memory buffer and do some pre-sorted, in order to improve efficiency.
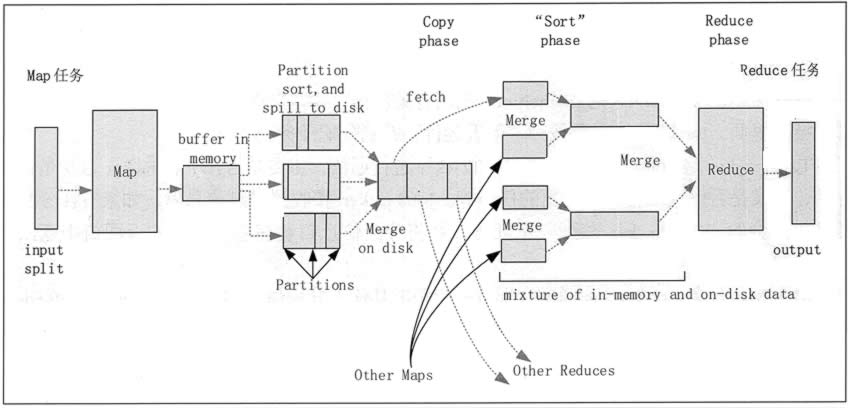
FIG 2 Hadoop MapReduce stage of Shuffle
2) Each task has a Map for writing output data of the circular buffer memory (default size is 100MB), when the amount of data in the buffer reaches a specific threshold value (default is 80%), the system will start a background thread, the contents of the buffer is written to disk (ie Spill stage). In the process of writing to disk, Map output continues to be written to the buffer, but in the meantime if the buffer is filled, the Map task will be blocked until the process is completed writing to the disk.
3) before writing to disk, according to the data first thread eventually be passed to the task Reduce the data into the appropriate partition (Partition). In each district, a background thread to sort by Key, if there is a Combiner, will run on the output sorted.
4) Once the memory buffer overflow write threshold reached, it will create an overflow write files, so after Map completes its task last output record, there will be multiple overflow write file. Map before the task is completed, the overflow write files are combined into one index and data files (multiple merge sort) (Sort stage).
5) After the spill write file merge is complete, the Map task will delete all temporary files overflow write and tell TaskTracker tasks have been completed, as long as a Map task is completed, Reduce task will begin copying its output (Copy stage).
6)Map 任务的输出文件放置在运行 Map 任务的 TaskTracker 的本地磁盘上,它是运行 Reduce 任务的 TaskTracker 所需要的输入数据。
2. Reduce 端的 Shuffle 阶段
1)Reduce 进程启动一些数据复制线程,请求 Map 任务所在的 TaskTracker 以获取输出文件(Copy 阶段)。
2)将 Map 端复制过来的数据先放入内存缓冲区中,Merge 有 3 种形式,分别是内存到内存,内存到磁盘,磁盘到磁盘。默认情况下,第一种形式不启用,第二种形式一直在运行(Spill 阶段),直到结束,第三种形式生成最终的文件(Merge 阶段)。
3)最终文件可能存在于磁盘中,也可能存在于内存中,但是默认情况下是位于磁盘中的。当 Reduce 的输入文件已定,整个 Shuffle 阶段就结束了,然后就是 Reduce 执行,把结果放到 HDFS 中(Reduce 阶段)。
Hadoop MapReduce的主要特点
MapReduce 在设计上具有的主要技术特点如下。
1. 向“外”横向扩展,而非向“上”纵向扩展
MapReduce 集群的构建完全选用价格便宜、易于扩展的低端商用服务器,而非价格昂贵、不易扩展的高端服务器。
对于大规模数据处理,由于有大量数据存储的需要,因此,基于低端服务器的集群远比基于高端服务器的集群优越,这就是 MapReduce 并行计算集群会基于低端服务器实现的原因。
2. 失效被认为是常态
MapReduce 集群中使用大量的低端服务器,因此,结点硬件失效和软件出错是常态,因而一个设计良好、具有高容错性的并行计算系统不能因为结点失效而影响计算服务的质量。
任何结点失效都不应当导致结果的不一致或不确定性,任何一个结点失效时,其他结点要能够无缝接管失效结点的计算任务,当失效结点恢复后应能自动无缝加入集群,而不需要管理员人工进行系统配置。
MapReduce 并行计算软件框架使用了多种有效的错误检测和恢复机制,如结点自动重启技术,使集群和计算框架具有对付结点失效的健壮性,能有效处理失效结点的检测和恢复。
3. 把处理向数据迁移
传统高性能计算系统通常有很多处理器结点与一些外存储器结点相连,如用存储区域网络连接的磁盘阵列,因此,大规模数据处理时,外存文件数据 I/O 访问会成为一个制约系统性能的瓶颈。
为了减少大规模数据并行计算系统中的数据通信开销,不应把数据传送到处理结点,而应当考虑将处理向数据靠拢和迁移。MapReduce 采用了数据/代码互定位的技术方法,计算结点将首先尽量负责计算其本地存储的数据,以发挥数据本地化特点,仅当结点无法处理本地数据时,再采用就近原则寻找其他可用计算结点,并把数据传送到该可用计算结点。
4. 顺序处理数据,避免随机访问数据
大规模数据处理的特点决定了大量的数据记录难以全部存放在内存中,而通常只能放在外存中进行处理。由于磁盘的顺序访问要远比随机访问快得多,因此 MapReduce 主要设计为面向顺序式大规模数据的磁盘访问处理。
为了实现高吞吐量的并行处理,MapReduce 可以利用集群中的大量数据存储结点同时访问数据,以此利用分布集群中大量结点上的磁盘集合提供高带宽的数据访问和传输。
5. 为应用幵发者隐藏系统层细节
专业程序员之所以写程序困难,是因为程序员需要记住太多的编程细节,这对大脑记忆是一个巨大的认知负担,需要高度集中注意力,而并行程序编写有更多困难。
例如,需要考虑多线程中诸如同步等复杂繁琐的细节。由于并发执行中的不可预测性,程序的调试查错也十分困难,而且,大规模数据处理时程序员需要考虑诸如数据分布存储管理、数据分发、数据通信和同步、计算结果收集等诸多细节问题。
MapReduce provides an abstraction mechanism, the system programmer layer may isolate the details, calculate what the programmer need only be described, and specifically referred to on how to calculate the system to perform a frame process, so that the system programmer from layer details of liberation, algorithm design and is committed to its own application computing problems.
6. A smooth and seamless scalability
Here that scalability including the expansion of the two senses: data scalability and size of the system scalability.
Ideal software algorithms should be able to scale with the expansion of data while continuing to show effectiveness, the degree of decline in performance should expand the scale of multiple data rather, on the cluster size, the requirements should be able to calculate the performance of the algorithm with the number of nodes maintaining near-linear increase in the degree of growth.
The vast majority of existing stand-alone algorithms are lower than the above ideal requirements, the intermediate results data maintained in memory single algorithm will soon fail when large-scale data processing, computing from from single to large clusters based on parallel fundamentally requires a completely different algorithm design.
However, in many cases MapReduce or more is achieved over the expansion characteristics for many calculation, based on the calculated performance MapReduce may increase with the number of nodes increased approximately linearly held.
. Hadoop MapReduce workflow
. MapReduce Case Study: word count
. Hadoop MapReduce mechanism