Article Directory
- 3.1 Challenges of big data and big models
- 3.2 The basic process of distributed machine learning
- 3.3 Data and model division module
- 3.4 Single machine optimization module
- 3.5 Communication module
- 3.6 Data and model aggregation module
- 3.7 Distributed machine learning theory
- 3.8 Distributed Machine Learning System
3.1 Challenges of big data and big models
3.2 The basic process of distributed machine learning
-
Q: What is the main research of parallelization and distributed machine learning technology?
- 1. How to divide the training data
- 2. Assign training tasks
- 3. Allocate computing resources
- 4. Integrate distributed training results
- The goal is to achieve the perfect balance of training speed and training accuracy
-
Q: What are the three situations where distributed machine learning needs to be used?
- 1. Too much calculation
- 2. Too much training data
- 3. The model scale is too large
-
Q: For distributed machine learning solutions when the amount of calculation is too large:
- Multi-threaded or multi-machine parallel computing based on shared memory (or virtual memory)
-
Q: For distributed machine learning solutions when there is too much training data:
- The data is divided and distributed to multiple nodes for training. After each working node trains a sub-model based on local data, it communicates with other working nodes according to certain rules (mainly sub-model parameters or parameter updates) to ensure Finally, the results of each work node are effectively integrated and a global machine learning model is obtained
-
Q: For distributed machine learning solutions when the model scale is too large:
- Divide the model, because the dependence between the sub-models under the model parallel framework is very strong, so the communication requirements are extremely high
-
Q: What are the main contradictions in the field of distributed machine learning?
- Due to the slow training speed caused by the excessive amount of training data, data parallelism is the most common situation
-
Q: What are the four main components of distributed machine learning?
- 1. Data and model division module
- 2. Stand-alone optimization module
- 3. Communication module
- 4. Data and model aggregation module
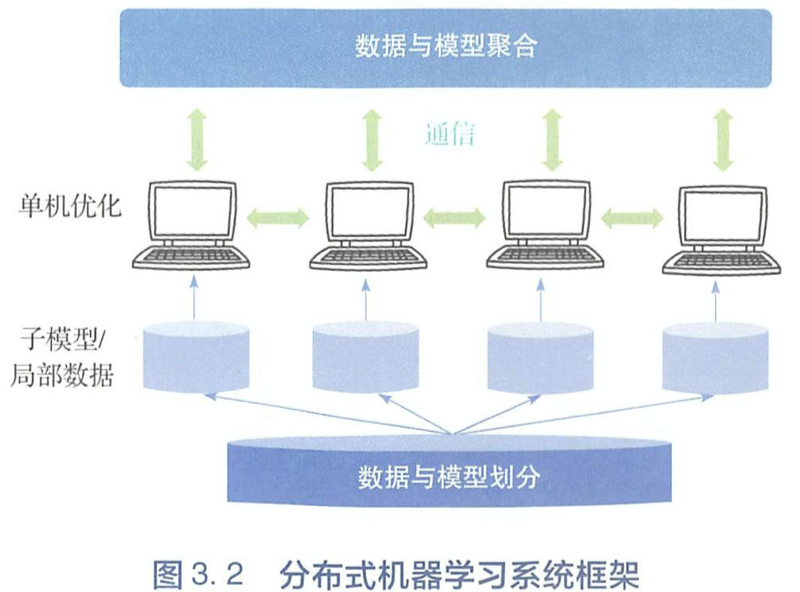
3.3 Data and model division module
-
Q: What are the two operational perspectives of data partitioning in distributed machine learning?
- 1. Divide the training sample
- 2. Divide the feature dimension of each sample
-
Q: In the data division of distributed machine learning, what are the two methods of dividing training samples?
- 1. Based on random sampling
- 2. Segmentation based on scrambling
-
Q: In the data division of distributed machine learning, how is the random sampling method of dividing training samples done?
- Take the original training set as the sampled data source, perform random sampling with replacement, and then allocate a corresponding number of training samples to each working node according to the capacity of it
-
Q: In the data division of distributed machine learning, what is the purpose of the random sampling method of dividing training samples?
- It can ensure that the local training data on each machine is independent and identically distributed with the original data, and the training effect is theoretically guaranteed
-
Q: In the data division of distributed machine learning, what are the two drawbacks of the random sampling method of dividing training samples?
- 1. The amount of training data is large, resulting in a relatively high cost for global adoption
- 2. Low-frequency training samples are difficult to be selected, and the sample data is not fully utilized
-
Q: In the data division of distributed machine learning, how is the scrambling segmentation method for dividing training samples done?
- Shuffle the training data
- Then divide the scrambled data into corresponding small parts according to the number of working nodes, and then distribute these small parts of data to each working node
- In the process of model training, each working node only uses the local data assigned to itself, and periodically (such as completing a complete training cycle) scrambles the local data again
- At a certain stage, it may be necessary to scramble and redistribute global data
-
Q: In the data division of distributed machine learning, what is the purpose of the scrambling segmentation method for dividing training samples?
- Let the training samples on each working node be more independent and have a more consistent distribution, so as to meet the assumption of independent and identical distribution of training data by machine learning algorithms
- Of course, even if local and global out-of-order operations are performed regularly, data scrambling is equivalent or close to random sampling without replacement, and the assumption of independent and identical distribution implies random sampling with replacement
-
Q: In the data division of distributed machine learning, what is the division of feature dimensions?
- Assuming that the training data is given in the form of a d-dimensional vector, the d-dimensional feature is sequentially divided into K parts, and then the sub-data set corresponding to each feature is assigned to K working nodes
- Note that this method needs to be used in conjunction with specific optimization methods (such as coordinate descent method), otherwise if the optimization algorithm needs to use multiple dimensions assigned to different working nodes at the same time, it will bring a great communication cost
-
Q: What is the model division method of distributed machine learning?
- Divide the machine learning model into several sub-models (part of the model parameters correspond to one sub-model), and then put each sub-model on a working node for calculation
- There will be a certain dependency relationship between the sub-models divided in this way, and different sub-model division methods will affect the dependency relationship and communication strength between each working node
-
Q: What are the structural characteristics of distributed machine learning to divide linear models?
- When dividing the linear model, you can directly divide it into different feature dimensions, and cooperate with the data division based on dimensions.
-
Q: What are the three ways to model deep neural networks in distributed machine learning?
- 1. Horizontal division layer by layer
- 2. Vertical division across layers
- 3. Random model partition
-
Q: What are the advantages and disadvantages of distributed machine learning for horizontal model division of deep neural networks?
- Advantages: clear interface and simple implementation
- Disadvantages: limited by the number of layers, the degree of parallelism is not high enough, and in extreme cases, the model parameters of a single layer may have exceeded the capacity of a working node
-
Q: What are the advantages and disadvantages of distributed machine learning for longitudinal model division of deep neural networks?
- Advantages: the model can be divided into more parts
- Disadvantages: the dependency between the sub-models will be more complicated, more difficult to implement, and higher communication costs
-
Q: What is the skeleton network in the neural network?
- Neural networks have a certain degree of redundancy. Given a neural network, there is often a smaller network that can achieve a similar function fitting effect. This small network is calledSkeleton network
-
Q: How does distributed machine learning perform random model division of deep neural networks?
- That is, the skeleton network is stored in each working node. In addition, when each working node communicates with each other, some neuron parameters belonging to the non-skeleton network will be randomly transmitted, thus playing the role of exploring the global topology of the original network
- The selection of the skeleton network can be updated periodically, and the exploration of the global topology is also dynamic and random. This can significantly reduce the communication cost of model parallelism, and theoretically guarantee the effect of model parallelism.
3.4 Single machine optimization module
- Q: What is the role of the single-machine optimization module of distributed machine learning?
- After completing data or model partitioning, each working node only needs to be trained based on the local training data and sub-models assigned to it
3.5 Communication module
-
Q: What is the role of the communication module of distributed machine learning?
- When the single-machine optimization module uses the local data to obtain the update of the local model, it will involve the problem of multi-machine and multi-thread cooperation, because only information sharing can organically combine the various working nodes. To achieve multi-machine collaboration, communication is required
-
Q: What are the three communication contents of the communication module of distributed machine learning?
- 1. Update of sub-model or sub-model (such as gradient)
- 2. Important samples (such as support vectors in support vector machines)
- 3. The intermediate result of the calculation (the output of a certain sub-model is the input of another model)
-
Q: What are the three communication topologies of the communication module of distributed machine learning?
- 1. Communication topology based on iterative MapReduce
- 2. Communication topology based on parameter server
- 3. Communication topology based on data flow
-
Q: What is the role of Map and Reduce in MapReduce?
- Map: complete data distribution and parallel processing
- Reduce: complete global synchronization and aggregation of data
-
Q: What are the implementation methods and advantages of iterative MapReduce?
- 1. It is completely based on memory, which greatly reduces the I/O cost in the calculation process
- 2. Introduce permanent storage to adapt to multiple iterations of data in machine learning tasks
- 3. The topology and programming mode of the classic MapReduce are still retained, and the existing system can be used to complete distributed machine learning tasks simply and efficiently
-
Q: What are the two drawbacks of iterative MapReduce?
- 1. The computing node and the model storage node are not well logically separated, and only support the synchronous communication mode: that is, the Reduce process can only be entered after all Mappers have completed their tasks, and vice versa
- 2. Need to make major changes to the existing single-machine optimization algorithm to fully comply with the programming interface of Map and Reduce
-
Q: Which 3 iterative MapReduce systems are currently widely used?
- 1.Spark MLlib
- 2.Vowpal Wabbit
- 3.Cloudera
-
Q: What is the communication topology based on the parameter server?
- The structure of parameter server logically separates the working node and the model storage node, so it can support various communication modes more flexibly
- Each working node is responsible for processing local training data, and communicates with the parameter server through the client API of the parameter server, thereby obtaining the latest model parameters from the parameter server, or sending model updates generated by local training to the parameter server
-
Q: What are the two advantages of the communication topology based on the parameter server?
- 1. The parameter server isolates the interaction process between each working node, and replaces it with the interaction between the working node and the parameter server. Therefore, nodes with fast calculations do not need to wait for nodes with slow calculations, thereby achieving higher speedups
- 2. Multiple parameter servers can be used to jointly maintain a larger model. Model parameters will be divided into multiple parameter servers for storage, and worker nodes' access to global parameters will be split and submitted to different parameter servers. Can balance load and improve communication efficiency
-
Q: What are the three most influential parameter server systems?
- 1. CMU's Parameter Server and Pltuum
- 2. Google's DistBelief
- 3. Microsoft's Multiverso
-
Q: What is the communication topology based on data flow?
- In the data flow system, calculation is described as a directed acyclic graph. Each node in the graph performs data processing or calculation, and each edge in the graph represents the flow of data. When two nodes are on two different machines, they will communicate.
-
Q: In the data flow system in the data flow-based communication topology, which two communication channels does each node have?
- 1. Control the message flow
- 2. Calculate data flow
-
Q: What is the role of computational flow in a data flow system in a data flow-based communication topology?
- It is mainly responsible for receiving the data and model parameters required for model training, and then through the internal computing unit of the working node to generate output data (the data here can be intermediate calculation results or parameter updates), and provide them to downstream Working node.
-
Q: What is the role of controlling message flow in a data flow system in a data flow-based communication topology?
- It determines what data the working node should receive, whether the received data is complete, whether the calculations to be done by oneself are completed, whether downstream nodes can continue to calculate, etc.
- When defining a working node, it is necessary to specify the state transition process of the working node, so as to generate some information when needed, and notify subsequent nodes to prepare to enter the state of message receiving and calculation through the control message flow.
-
Q: What is the most influential data stream-based system?
- Google's Tensorflow
-
Q: What is the reason for the popularity of synchronous communication?
- 1. Influenced by early iterative MapReduce
- 2. The way of synchronization is logically clear and theoretically guaranteed
- 3. Early distributed machine learning is generally not large in scale, and there are rarely thousands of nodes working at the same time, so the waiting time caused by synchronization is not unacceptable
-
Q: What are the algorithms based on synchronous communication?
- 1. Stochastic gradient descent method based on BSP (BSP-SGD)
- 2. Model averaging method
- 3.ADMM
- 4. Elastic average stochastic gradient descent method (EA-SGD)
-
Q: What are the two limitations of synchronous communication in the pace of communication?
- 1. When the computing performance of each working node is significantly different, the overall computing speed will be dragged down by the slower nodes
- 2. When some working nodes cannot work normally (such as system crash), the calculation of the entire cluster will not be completed, which will lead to the failure of the final distributed learning task
-
Q: How is asynchronous communication done in the pace of communication?
- Each worker node does not need to wait for other nodes after completing a certain amount of local model training, but directly pushes its own phased training results (such as local model or model update) to the parameter server, and then continues local model training ( When needed, the latest global model will be retrieved from the parameter server as the starting point for local training)
- The parameter server logically isolates each working node, so that even if individual working nodes are slow or fail, it will not have much impact on the overall learning process
-
Q: What is asynchronous communication with locks?
- Means that although each working node can perform local learning asynchronously, when they write local information into the global model, they will lock to ensure the integrity of data writing, but this may limit the system's throughput in parameter updates
-
Q: What is lock-free asynchronous communication like?
- When working nodes speak local information and write them into the global model, data integrity is not guaranteed in exchange for higher data throughput
-
Q: What are the current algorithms based on asynchronous communication?
- 1. Asynchronous Stochastic Gradient Descent (ASGD)
- 2.HogWild!
- 3.Cyclades
-
Q: What are the "delay" manifestations and reasons of asynchronous communication?
- Reason: The working nodes are not synchronized, and their pace may vary greatly.
- Performance: For example, a node is trained for 100 rounds on the basis of the global model quickly, and another node is only trained for 1 round. At this time, the latter may seriously affect the global model when the model or updates are written into the global model. convergence speed
-
Q: What are the solutions to the delay problem of asynchronous communication?
- 1. Asynchronous communication methods that are not sensitive to delay: AdaptiveRevision and AdaDelay
- 2. Asynchronous communication methods that essentially compensate for delays, such as asynchronous stochastic gradient descent with delay compensation (DC-ASGD)
-
Q: What is the basic idea of semi-synchronous (SSP)?
- When the difference (delay) between the fastest and slowest working nodes is not too large, the working nodes will train asynchronously; and when the system detects that the delay is too large, the fastest working node will be asked to stop. Edge work waits for the slower node until the delay is less than a certain threshold before allowing the fastest node to continue working
-
Q: What is the hybrid synchronization method?
- The working nodes are grouped according to a certain criterion, the nodes in the group adopt a synchronous communication mode, and the group adopts an asynchronous communication mode
-
Q: What are the methods to minimize the amount of data to be sent under the current parameter space?
- 1. Model compression, such as low-rank decomposition of the model matrix
- 2. Model quantization, such as low-precision quantization of model parameters (such as one-bit quantization), or random dropout of model parameters (weighted dropout)
3.6 Data and model aggregation module
-
Q: What are the two methods for the data and model aggregation module to obtain the global model?
- 1. The global model can be obtained by simply averaging the model parameters, or it can be obtained by solving a consistent optimization problem (such as ADMM, BMUF)
- 2. Get the global model through model integration (ensemble)
-
Q: Do all sub-models need to be aggregated during model aggregation? What is the reason?
- Not needed
- 1. Starting from the accuracy of the global model, if some local models (or their updates) have significant delays, then aggregating such models may affect the final quality of the global model.
- 2. Starting from the efficiency of distributed machine learning, if some working nodes are slow, waiting for their sub-models may slow down the entire learning process, but skip them and only respond to the children of those working nodes that respond faster. Models are aggregated. Such as synchronous stochastic gradient descent method with backup worker nodes and asynchronous ADMM
-
Q: When the parameter server pushes the aggregated global model back to each worker node, what are the two methods of the worker node?
- 1. Unconditionally trust the global model, and use local data to iterate on it
- 2. Partially trust the global model, and only use the global model to update the local model with a certain probability. Such as: Elastic Average Stochastic Gradient Descent (EA-SGD)
3.7 Distributed machine learning theory
3.8 Distributed Machine Learning System
-
Q: Comparison of the flexibility of three typical distributed machine learning systems: Spark MLlib of iterative MapReduce, Multiverso of parameter server, Tensorflow of data flow
- 1. MapReduce has the lowest flexibility and needs to follow the special execution process of the system, namely the Map+Reduce step
- 2. The parameter server has the highest flexibility, because it only provides a global storage server and an API to access the global storage, and has no requirements for the flow of the distributed program itself and the specific calculations.
- 3. The flexibility of the data flow system is in the middle. Because the task needs to be described in the form of DAG, it is still more flexible than MapReduce
-
Q: Comparison of operating efficiency of three typical distributed machine learning systems: Spark MLlib of iterative MapReduce, Multiverso of parameter server, Tensorflow of data flow
- 1. MapReduce based on synchronization logic is inefficient
- 2. A parameter server or data stream system based on asynchronous communication logic will be better
- The system's implementation method, programming language, network communication library and architecture are also determining system efficiency.
-
Q: Comparison of tasks processed by three typical distributed machine learning systems: Spark MLlib of iterative MapReduce, Multiverso of parameter server, Tensorflow of data flow
- 1. The machine learning methods supported by Spark MLLib generally use relatively shallow models, such as logistic regression, LDA, matrix decomposition, etc.
- 2. TensorFlow provides a lot of operators and optimizers for matrix operations, allowing users to freely build more complex calculation models such as deep learning
- 3. Multiverso has no restrictions on the single-machine learning process and can support all types of learning tasks. Of course, users need to implement machine learning algorithms by themselves
-
Q: Comparison of users of three typical distributed machine learning systems: Spark MLlib of iterative MapReduce, Multiverso of parameter server, Tensorflow of data flow
- 1. Spark MLlib and Tensorflow are relatively complete, and the supporting upstream and downstream tools are relatively rich, such as data IO, execution engine, data prediction, etc.
- 2. Multiverso is bound by python and has good support for different algorithms, but due to the relatively weak ecosystem, users need to build other supporting functions by themselves