Article Directory
This article is completely based on "Statistical Learning Method 2nd Edition" by Teacher Li Hang
Preface
First introduce HMM hidden Markov mainly solves three basic problems:
1. Probability calculation problem (known model parameters, the probability of the observation sequence appearing):
- Direct calculation method, complexity is O (TNT) O (TN^T)O ( T NT ), not practical
- Forward algorithm, the complexity is O (TN 2) O(TN^2)O ( T N2)
- Backward Algorithm
2. Learning problem (known observation sequence, estimated model parameters)
- Supervised learning method: simple calculation, but requires a lot of manual annotation
- Unsupervised learning method (Baum-Welch algorithm)
3. Prediction problem (known observation sequence, estimated state sequence)
- Approximate algorithm: Greedy algorithm, to obtain the state of the maximum probability at each time t, but only considers the local optimum, it is difficult to obtain the global optimum
- Viterbi Algorithm
Viterbi Algorithm
The Viterbi algorithm is a dynamic programming algorithm, essentially filling in a form. Considering that the length of the time series is T and the possible state is N, the process of the algorithm is actually to fill a table of size N*T. Let's combine examples and fill out this form together.
Consider the following questions:

A is the state transition matrix, B is the matrix observed from the state, and Π is the initial state vector. Therefore, there are 3 states (N=3), and the length of the observation sequence is 3 (T=3), so we have to fill in a 3*3 form.
Step 1: initialization
At time 1,
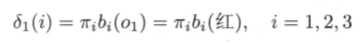
fill in the table according to the following formulas to obtain the respective probabilities of the three states (deemed as optimal) :
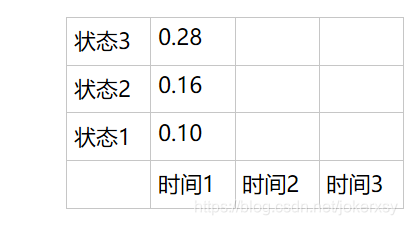
Step 2: Recursion downward
At time 2, there are three possible states. Consider the combination of the three situations at time 1 and the current time to obtain the maximum probability of the three states at time 2, the formula is as follows:
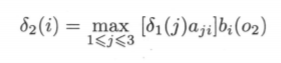
Among them, the current time, the selected state is 1. The probability of is calculated as follows:
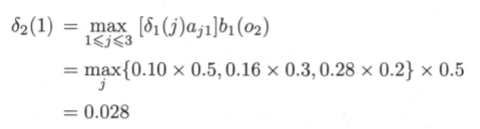 That is to say, when the last time state is 3, the current state is 1 most likely.
That is to say, when the last time state is 3, the current state is 1 most likely.
Fill in all the results in the form: at
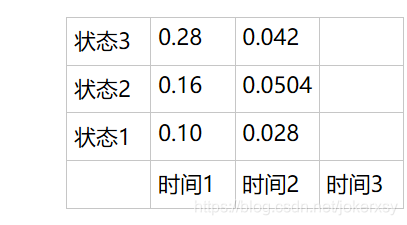
time 3, also according to the three situations at time 2, consider the combination of the three situations and the three states of the current time to get the maximum probability (the formula remains unchanged):
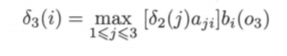
fill in the form
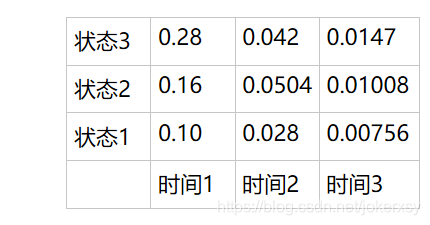
Step 3: Get the probability and end point of the optimal path
Obviously, the probability of the optimal path is 0.0147, and the end point is state 3.
Step 4: Reverse to get the complete state sequence
In fact, the complete path we get is as follows:
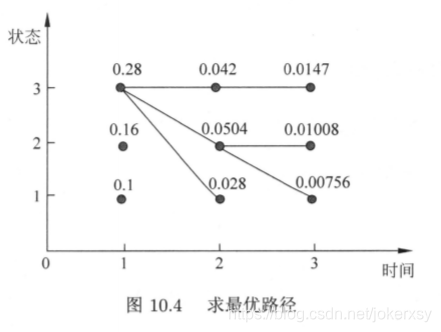
That is to say, at time 1, the three initialization probabilities are 0.28, 0.16, and 0.1 respectively; then, the maximum probability of the three states at time 2 is based on time 1 being state 3; The maximum probability of the three states at time 3 is 0.0147, which is based on time 2 as state 3.
In the process of filling out the form, we also need to record this information. It is very simple. At the same time, we can maintain an array D:
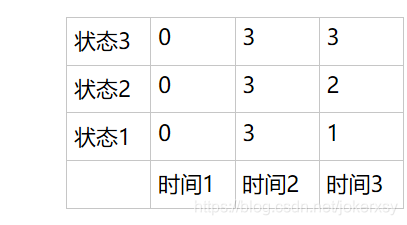
Explanation: When initializing in the first step, fill in all 0, and in the second step of recursion, fill in the rest.
We have obtained in the third step that the state of the end point (t=3) is 3, the state when t=2 is D(3,3) = 3, and the state when t=1 is D(2,3)=3 .
So the final state sequence is: [3,3,3].
postscript
It is completely a dynamic programming, and the optimal solution is reconstructed.
Both HMM and CRF can be used for sequence labeling problems. Among them, the input word sequence is the observation sequence; the output label sequence is the state sequence. Since the state sequence is not only related to the observation sequence, according to the Markov property, there is also a certain correlation between the two states, so a certain performance can be increased.
These models can accurately consider the dependence between tags, which is not possible with neural networks such as RNN and CNN. But neural networks can be infinitely deep and can extract features well, so we can integrate them:
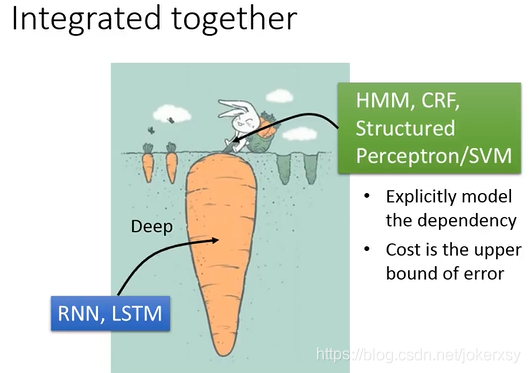
The neural network only considers the relationship between the observation sequence and the state sequence, and puts its output into HMM, CRF, etc., and further considers the relationship between the state and the state.