This article reprinted from: https://zhuanlan.zhihu.com/p/58163299
I recently learned NLP, NLP I believe we all know that the first step is to credit the words, but the word ≠ natural language processing. Now segmentation tools and how to use the Internet a lot. I would like to share is that stuttering word core, along with exploring the nature of the word.
(1) Based on the prefix word dictionary FIG efficient scanning, generating all possible characters into words in the case of a sentence constituted directed acyclic graph
What is the DAG (directed acyclic graph)?
For example, the sentence "Peking to play" DAG corresponding to {0: [0], 1: [2,4], 2: [2] 3: [3,4], 4: [4], 5: [5]}. DAG {0: [0]} 0 represents a position corresponding to the word, that is 0~0, i.e., "out" in the word of Dict (dictionary database, which records the frequency of each word) are terms. DAG in {1: [2,4]}, is expressed from a starting position, the 2,4 position is the word that is 1 to 1,1 to 2,1 to 4 i.e. "North" " Beijing "" Peking University "this is three words appear in the Dict. Sentence "to Peking University to play," the DAG, after all, can be a relatively short glance out, now comes another sentence, "there are often differences of opinion" and how to get it DAG it? This time it has to be achieved through the code.
Dict = { "often": 0.1 "by": 0.05, "Yes": 0.1 "normal": 0.001, "have opinions": 0.1 "discrimination": 0.001, "Opinion": 0.2 "differences": 0.2, "see": 0.05 "meaning": 0.05 "see differences": 0.05, "minute": 0.1}
def day (sentence):
DAG = {} #DAG empty dictionary, used to construct the directed acyclic graph DAG
N = len (sentence)
for k in range(N):
tmplist = []
i = k
frag = sentence[k]
while i < N:
if frag in Dict:
tmplist.append(i)
i += 1
frag = sentence[k:i + 1]
if not tmplist:
tmplist.append(k)
DAY [k] = tmplist
Return DAY
print (DAG ( "There are often differences of opinion"))
Output:
{0: [0, 1], 1: [1], 2: [2, 4], 3: [3, 4], 4: [4, 6], 5: [5, 6], 6: [6]}
The probability of occurrence of each word dict and can get all possible paths (word), the following figure:
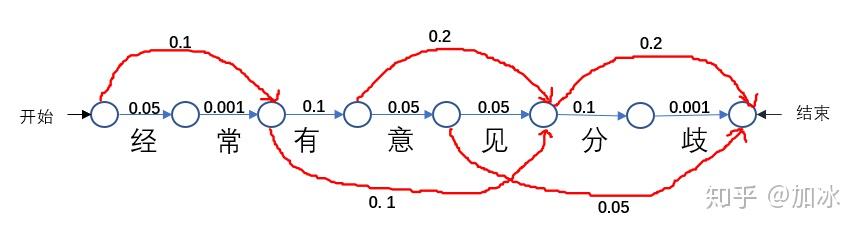
The figure shows DAG
As long as the word appears, it can be divided, as DAG "often" the word does not appear, it can not be separated as a single word, by running the code, we can get "often have differences of opinion," the
{0: [0, 1], 1: [1], 2: [2, 4], 3: [3, 4], 4: [4, 6], 5: [5, 6], 6: [6]}
Easy and intuitive understanding of DAG, we have the problem into looking for the path of the process, it is above figure shows, from start to finish, such as I took the path the top red line to walk, you can get [always | have | comments | divided] the word case If the probability of each step of the value they add up to score the path of S = 0.1 + 0.1 + 0.2 + 0.2 = 0.6, the same way I take the other path [by | often | have comments | divided], its score is S = 0.05 + .0.001 + 0.1 + 0.2 = 0.351. This is our first step through the code to construct a sentence of DAG.
(2) the use of dynamic programming to find the maximum probability path to find the segmentation based on maximum combination of word frequency.
By the first step, get the DAG, you can also get score S of each path, find the maximum score, which is the maximum value of the probability of the situation, we are looking for word situation. If all paths traverse, then find each path and then find each S, remove the largest S, of course, you can get what we want, but more brute force. We can try to use dynamic programming ideas, the Viterbi algorithm , directly on the map
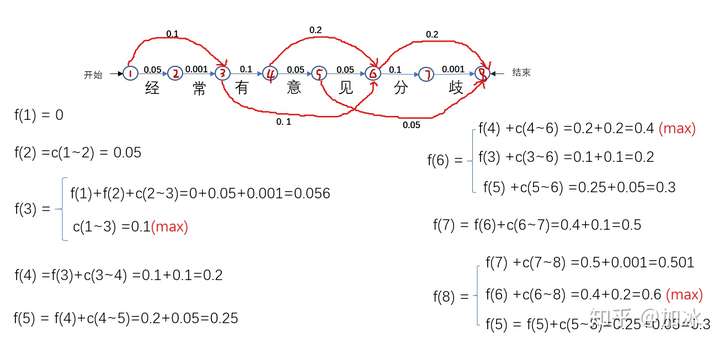 Order solution Viterbi algorithm
Order solution Viterbi algorithm
给每个节点编号1~8,开始到结束,f(a)代表该节点的所有得分值,每一步单个的箭头都有其对应的概率值,c(a~b)代表的是a节点到b节点的值,如c(1~3)是“经常”的概率值,为什么有的节点如f(6)有三个值?那是因为6这个节点有三个箭头指向它,也就是说有多少个箭头指向该节点,该节点就有多少个得分值,如分f(3)有2个值、f(4)有一个值......。按1~8的顺序,计算出每个节点的所有得分值,计算后面节点的时候要用到前面节点得分值都取(max)最大的,以保证最后计算到f(8)时是全局的最大值,例如计算f(4)中f(3)取的就是0.1。算到最后,我们知道f(8)=f(6) +c(6~8) =0.4+0.2=0.6 (max),接着把f(6)展开,f(8)=f(4) +c(4~6) +c(6~8) ,同理,把所有的f()换成c(),f(8)=c(1~3) +c(3~4) +c(4~6) +c(6~8) 。直到等式右边没有f(),c(1~3)、c(3~4)、c(4~6)、c(6~8)分别代表啥各位看图去吧。
回到开始,假如用蛮力一个一个列出所有路径,不累死也得列的头晕,用动态规划的思想可以把一个大问题拆分到每一步的小问题,下一步的小问题只需要在之前的小问题上再进一步,动态规划的思想就像是小问题站巨人肩膀上,然后大问题莫名其妙就解决了。刚说的是从开始到结束的顺序解法,要是从8节点到1节点逆序解法怎么解?
 维特比算法的逆序解法
维特比算法的逆序解法
发现没,最后最大都是0.6=f(1)=c(1~3) +c(3~4) +c(4~6) +c(6~8),而且直接都是看出来了,再一次说明了最大的路径就是这条路径。说了这么多,上代码
sentence ="经常有意见分歧"
N=len(sentence)
route={}
route[N] = (0, 0)
DAG={0: [0, 1], 1: [1], 2: [2, 4], 3: [3, 4], 4: [4, 6], 5: [5, 6], 6: [6]}
for idx in range(N - 1, -1, -1):
distance = (((Dict.get(sentence[idx:x + 1]) or 0) + route[x + 1][0], x) for x in DAG[idx])
route[idx] = max(distance)
# 列表推倒求最大概率对数路径
# route[idx] = max([ (概率值,词语末字位置) for x in DAG[idx] ])
# 以idx:(概率最大值,词语末字位置)键值对形式保存在route中)
# route[x+1][0] 表示 词路径[x+1,N-1]的最大概率值,
# [x+1][0]即表示取句子x+1位置对应元组(概率对数,词语末字位置)的概率对数
print(route)
输出结果:
{7: (0, 0), 6: (0.001, 6), 5: (0.2, 6), 4: (0.25, 4), 3: (0.4, 4), 2: (0.5, 2), 1: (0.501, 1), 0: (0.6, 1)}
这是一个自底向上的动态规划(逆序的解法),从sentence的最后一个字开始倒序遍历每个分词方式的得分。然后将得分最高的情况以(概率得分值,词语最后一个字的位置)这样的tuple保存在route中。看route的0: (0.6, 1)中的0.6,不就是我们求到的f(1)的max, 1: (0.501, 1)中的0.501不就是f(2)......后面大家对着看图找规律吧。最后小操作一波,就可以把我们要的分词结果打印出来了,结果和手推的是一样的c(1~3) +c(3~4) +c(4~6) +c(6~8)。
x = 0
segs = []
while x < N:
y = route[x][1] + 1
word = sentence[x:y]
segs.append(word)
x = y
print(segs)
#输出结果:['经常', '有', '意见', '分歧']
上面只是一些核心的思路,好多地方可以继续优化的,比如把概率值转换成-log(概率值),目的是为了防止下溢问题,只是我举例的概率值比较大,如果是一个超大的Dict,为了保证所有词的概率之和约等于1,那每个词对应的概率值会特别小。
(3)中文分词以后得攻克的难点
1、分词的规范,词的定义还不明确,没有一个公认的、权威的标准。
2、歧义词的切分。这也从侧面证实了中华文化博大精深。
3、未登录的新词。就是咱们的Dict里没有的词,对于3这个比2对分词的影响大多了,目前结巴分词对此采取的方法是:基于汉字成词能力的HMM模型,使用维特比算法。
参考:
1、贪心学院nlp
2、自然语言处理理论与实战 唐聃