1. Gossip
Before going to bed every night, I would convince myself that everything that happened during the day was fake and has passed. Just like waking up every morning, I can't help but feel that everything that happened last night is also fake. In fact, if you think about it carefully, the things that can enter dreams in the real world are very limited. Similarly, things in dreams can flow into the real world is very limited. Then there should be something similar to a filter at the entrance and exit, blocking most of the things. At night, I lay there like a pile of sand, and when the morning sun shines in, I condensed and moved around in an adult manner. What I want to express here is not to say that this world is illusory, but to say that it is extremely real. The real world is colorful, full of all kinds of magical and beautiful things. Rules apply to things below the rules, and higher rules apply to higher things. Even if you want to break the sky despite your random thoughts, it will not be richer than the original style of this world.
2. Language model
How to understand the language model is equivalent to the way humans encode and decode information. In the human brain, in addition to a bunch of words, there are also things like style, temperament, tone, etc. If we think carefully, we will find that our expression is not like an essay question, but more like a multiple choice question. From the various language models in our memory, we choose the one we feel is the best, and in this way we will combine and encode vocabulary and output our own opinions. Many things that seem to be free and arbitrary, including our way of thinking and behavior, are essentially a process of choice. There may be more models to choose from these things, but they are also limited. Even if a person is talking nonsense, then he must be talking nonsense according to a certain model. The existence of these models realizes the encoding and decoding of information between people. The finiteness of models and symbols also determines the finiteness of human beings. The language model in the neural network is more describing the combination of words, using context to predict the current word.
3.N-gram
N-gram is a statistical language model, which is based on the Markov hypothesis that future events only depend on a limited history. This assumption is easy to understand. For example, I am hungry this afternoon. It depends on what I eat for lunch or breakfast; if it doesn’t work, it’s based on what I ate for dinner yesterday; but for the human digestive system Say, it will not depend on what I ate last year or earlier. This is just a hypothesis. I don't know if all events happen because of this time limitation. At least it seems that most things are like this. At most, it is just a matter of limited time. So this assumption should be usable.
Applying the Markov model to the language model is that the appearance of each word depends on the limited number of words before it. For example, this famous saying: "Survival or death, this is a question worth thinking about." If we assume that the number of finite words is 2, then the word "death" depends on "survival" and "or". For this finite number Different definitions of the number of words n constitute different gram models. For example, if n is 1, it is unigram, 2 is bigram, and 3 is trigram.
So how do we implement the above thoughts and apply them to our language model? We use the Bayes formula. The first half of the formula below is the Bayes formula. If you don’t want to know more about Bayes, you can click here ; the short answer is that the probability of B appearing under the condition of A = the joint probability of AB/A Probability of appearance. We see that the Bayesian formula is followed by count statistics, which means that in the case of a large number, the probability is very close to the ratio of the number of times they appear.
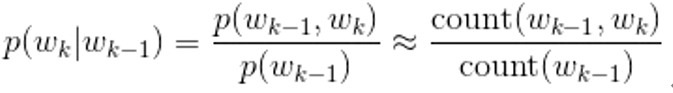
Based on the above formula, we expand the N-gram. The following formula explains: the probability of the overall sentence is equal to the product of the probability of each word in the sentence, and the probability of the word in the sentence is equivalent to the word in the first N Probability under the word condition. When N is 1, each word is equivalent to being independent, and the direct probability is multiplied, which is equivalent to using the maximum likelihood; when N is 2, the probability of the entire sentence is equivalent to each word under the condition of the previous word Multiplying the probability of, the same goes backwards.

Here is an example, the probability distribution table of the binary model. The probability of each word and another word can be obtained, where the probability is the number of occurrences of these two word combinations divided by the number of occurrences of all pairwise word combinations. Generally speaking, the ternary model is used more, but if the duality can be used, don't use the ternary.

related question:
1. The OOV problem, that is, if a word we did not have before. Then the probability of this word will be 0, resulting in the probability of the entire sentence being 0; the processing method is to set a threshold, and only the occurrences greater than a certain threshold will be included in the vocabulary, and other special characters will be used instead of UNK. It is equivalent to characters with too small threshold not participating in the calculation of total probability.
2. Smoothing: If the combination is not in our corpus, the count is 0, and the calculated probability is also zero at this time. In this case, we add 1 to each number and do a smoothing process.
2. Distinguishability and reliability: If N is too large, it will lead to too strong constraints on the current word, which will easily lead to overfitting. Then the distinguishability will be higher, and the reliability will be reduced accordingly. To be honest, the training set is more accurate with too many features, but it is easy to overfit.
Evaluation:
Advantages: Because it is based on a limited number of words, it is efficient;
Disadvantages: unable to associate earlier information, unable to reflect similarity, and there may be a situation where the probability is 0;
Summary: n-gram is a model based on Markov hypothesis and using statistics to express the distribution of words in the text. The distribution probability of the whole text can be represented by the multiplication of the conditional probability of each word. The advantage is that it is efficient based on a limited history; the disadvantage is that it cannot reflect text similarity and cannot associate earlier information.
4. N-gram neural network language model
The N-gram neural network language model is a network model that combines the ideas of N-gram with the neural network and predicts the current word based on context information. The statistics-based N-gram we mentioned earlier has some shortcomings and belongs to the category of machine learning. So what will a neural network based on deep learning look like?
Please look at the following network diagram. Simply put, it is to input the context information into the model to predict the probability of each word in the vocabulary, and the highest probability is our predicted value. This is a very simple four-layer neural network. Let's get to know some key points. Firstly, each word in the context is one-hot encoded, and then the word vector of the corresponding word is found through the word vector table (the word vector table is also obtained through training), and a projection layer is used to splice all the context vectors. Then through the hidden layer, use tanh nonlinear activation, and finally output as softmax multi-classification.
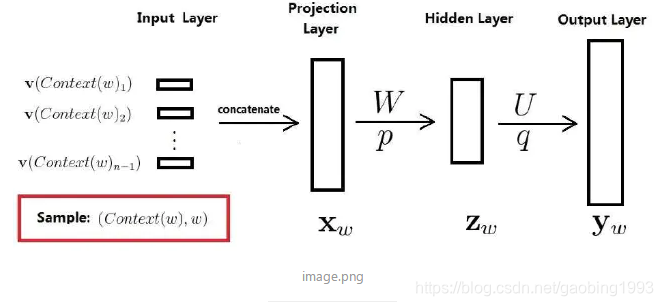
What the trained model can do is, given a context, it will predict what the current word is. Then you will get the byproduct of the model-the word vector table. Description of each parameter: the number of input layer V (context(W)) is consistent with the number of words in the context; the shape of the word vector table is (number of words in the word list * length of the word vector);
Summary: Above we introduced the N-gram neural network language model, which is mainly to apply the idea of N-gram to the neural network architecture, which is different from our statistical language model above. This model can calculate the similarity between words based on word vectors.
5. Summary
In this article, we describe the idea of N-gram and neural network language model. It is a language model based on Markov's assumption. It can be used to extract the relationship between implicit words in the text, and the predicted words will be given through the given context. It's like a kid who loves to pick up other people's words.
A hopeless future is not what I am looking forward to. Before the storm, I don’t need an umbrella to protect; I want to make myself an umbrella for my family through my continuous efforts. Because I was young, I had nothing to lose; also because of my youth, I told myself that I was not qualified to talk about the word fear. Because the proud flower is unwilling to hide in the flower bone forever to shelter from the wind and rain. In order to see the sun, it has long since been afraid of being crushed by the ruthless wind and rain to make dust. The flowers bloom for a while, and people live forever, overcoming obstacles and flying against the wind. Please enjoy the following timeless classic-Blue Bird.
[Naruto] Blue Bird-Live Singing