Background :
I’ve always wanted to share the things about the java virtual machine. I have been working on it for a long time. It’s too theoretical, and I can’t write too many special things. I see that some friends have shared it very well, and it has been organized into a system, so I will reprint it. , I hope it is useful to friends, welcome to pay attention to Pharaoh's official account [Software Pharaoh], and pay attention to not getting lost.
The garbage collection algorithm can be divided from different angles:
According to the basic recycling strategy
Reference Counting:
Older recycling algorithm. The principle is that this object has a reference, that is, a count is increased, and a reference is deleted to decrease a count. During garbage collection, only objects with a count of 0 are collected. The most fatal thing about this algorithm is that it cannot handle circular references.
Mark-Sweep:
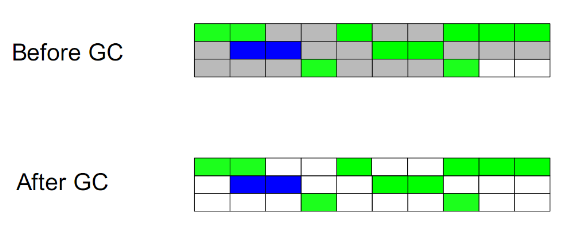
This algorithm is executed in two stages. The first stage starts with the reference root node and marks all referenced objects. The second stage traverses the entire heap and clears unmarked objects. This algorithm needs to suspend the entire application, and at the same time, it will generate memory fragmentation.
Copying:
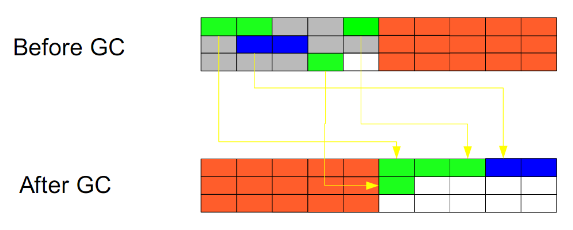
This algorithm divides the memory space into two equal areas and only uses one of them at a time. During garbage collection, it traverses the area currently in use and copies the objects in use to another area. This algorithm only processes the objects that are in use each time, so the cost of copying is relatively small. At the same time, the corresponding memory can be organized after copying, and there will be no "fragmentation" problem. Of course, the disadvantage of this algorithm is also obvious, that is, it needs twice the memory space.
Mark-Compact:
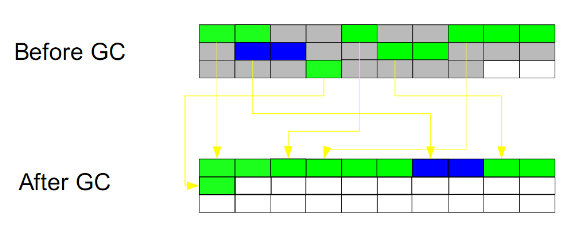
This algorithm combines the advantages of the two algorithms "mark-clear" and "copy". It is also divided into two stages. The first stage starts from the root node and marks all referenced objects. The second stage traverses the entire heap, clears unmarked objects and "compresses" the live objects into one of the heaps, and discharges them in order. This algorithm avoids the "mark-and-clear" fragmentation problem, and also avoids the space problem of the "copy" algorithm.
According to the division of treatment
Incremental Collecting: Real-time garbage collection algorithm, that is, garbage collection is performed while the application is in progress. I don't know why the collector in JDK5.0 did not use this algorithm.
Generational Collection (Generational Collecting): Based on the garbage collection algorithm derived from the object life cycle analysis. The objects are divided into young generation, old generation, and permanent generation, and different algorithms (one of the above methods) are used to recycle objects of different life cycles. The current garbage collector (from J2SE1.2) all use this algorithm.
By system thread
Serial collection : Serial collection uses a single thread to process all garbage collection work, because there is no need for multi-threaded interaction, it is easy to implement and more efficient. However, its limitations are also obvious, that is, the advantages of multiple processors cannot be used, so this collection is suitable for single-processor machines. Of course, this collector can also be used on multi-processor machines with small data volumes (about 100M).
Parallel collection : Parallel collection uses multiple threads to process garbage collection, so it is fast and efficient. And theoretically, the more CPUs, the better the advantages of parallel collectors can be realized.
Concurrent collection : Compared with serial collection and parallel collection, the first two need to suspend the entire operating environment during garbage collection, and only the garbage collection program is running. Therefore, the system will have an obvious pause during garbage collection. , And the pause time will be longer because of the larger the heap.
For more knowledge, please pay attention to the public account: "Software Pharaoh" , pay attention to not getting lost, Software Pharaoh and his IT friends, share some of their technical insights and life stories.
