1. Understand XPath
1.1 What is XPath?
XPath is a language for finding information in XML and HTML documents. It can be used to traverse elements and attributes in XML and HTML documents.
1.2 XPath development tools
chrome plugin XPath Helper
Firefox plugin Try XPath
1.3 XPath node
There are seven types of nodes: element, attribute, text, namespace, processing instruction, comment, and document (root) node.
XML documents are treated as a tree of nodes. The root of the tree is called the document node or root node.
2. XPath syntax
2.1 Path expression
Use path expressions to select nodes or node sets in the XML document.
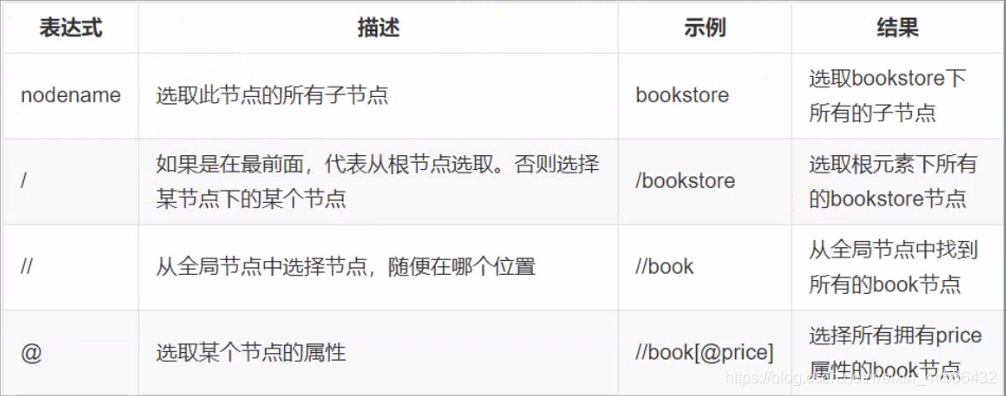
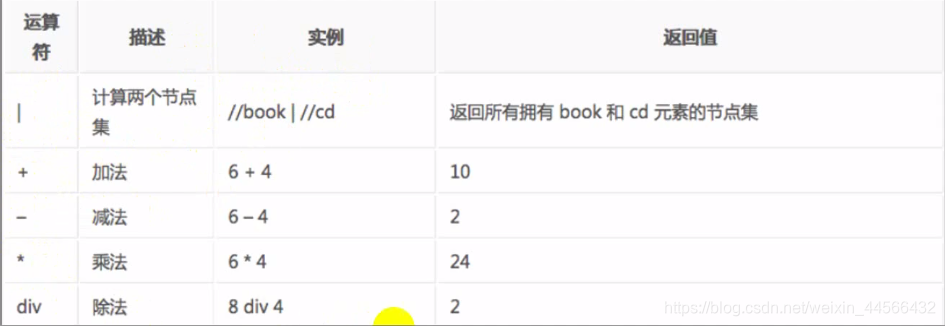
Select multiple paths with | operator
2.2 Predicate
The predicate is used to find a specific node or a node containing a specified value. It is embedded in square brackets [] . Note that the sequence number in [] starts from 1.
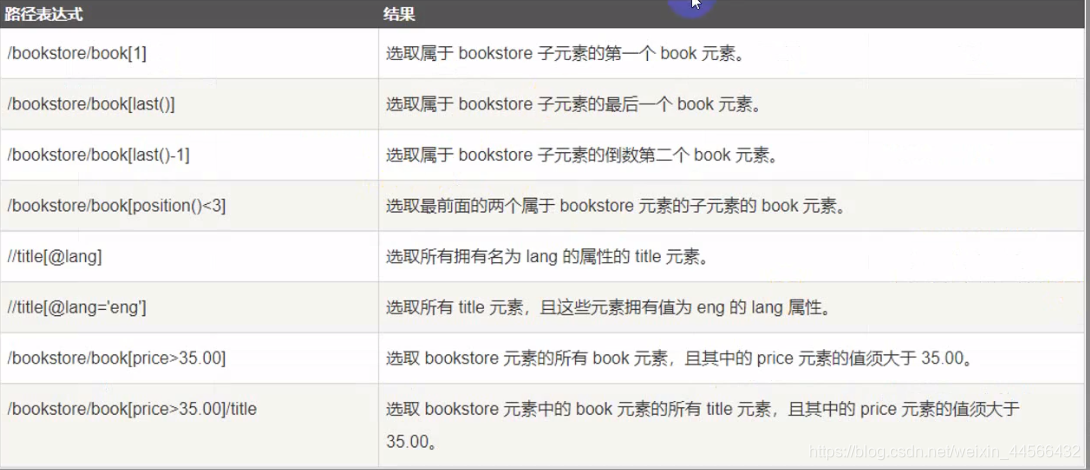
2.3 Wildcard
* Means wildcard
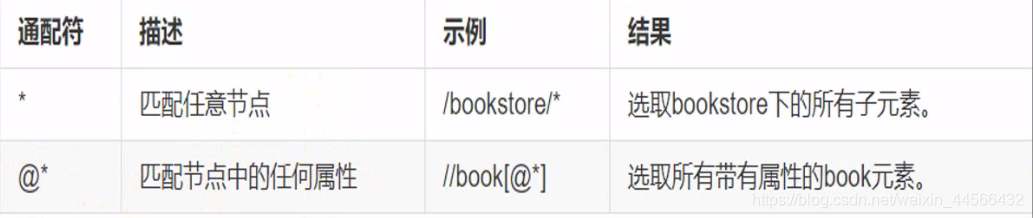
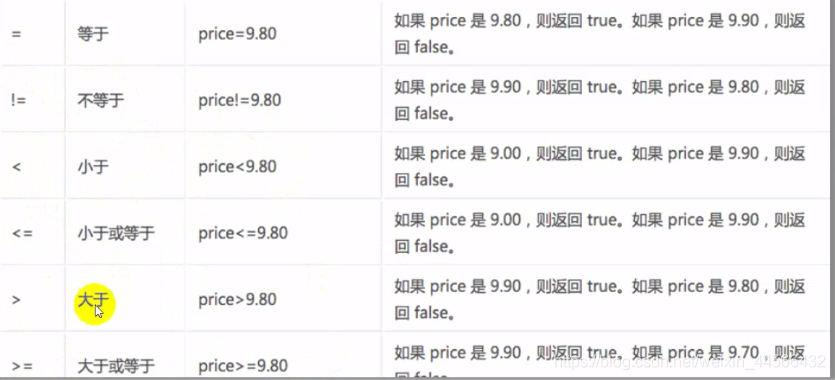
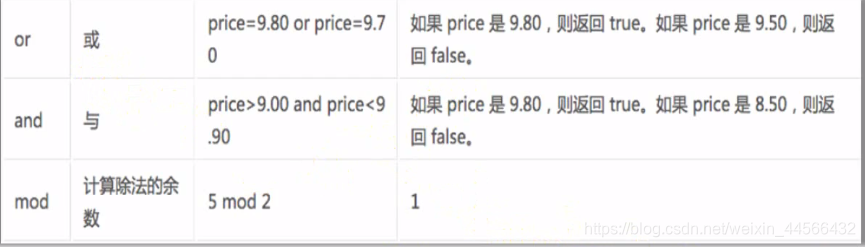
2.4 Operator
3. LXML library
lxml is an HTML/XML parser. Its main function is how to parse and extract HTML/XML data.
3.1 Basic usage
3.1.1 Parse the code
from lxml import etree
text = '''
<div>
<ul>
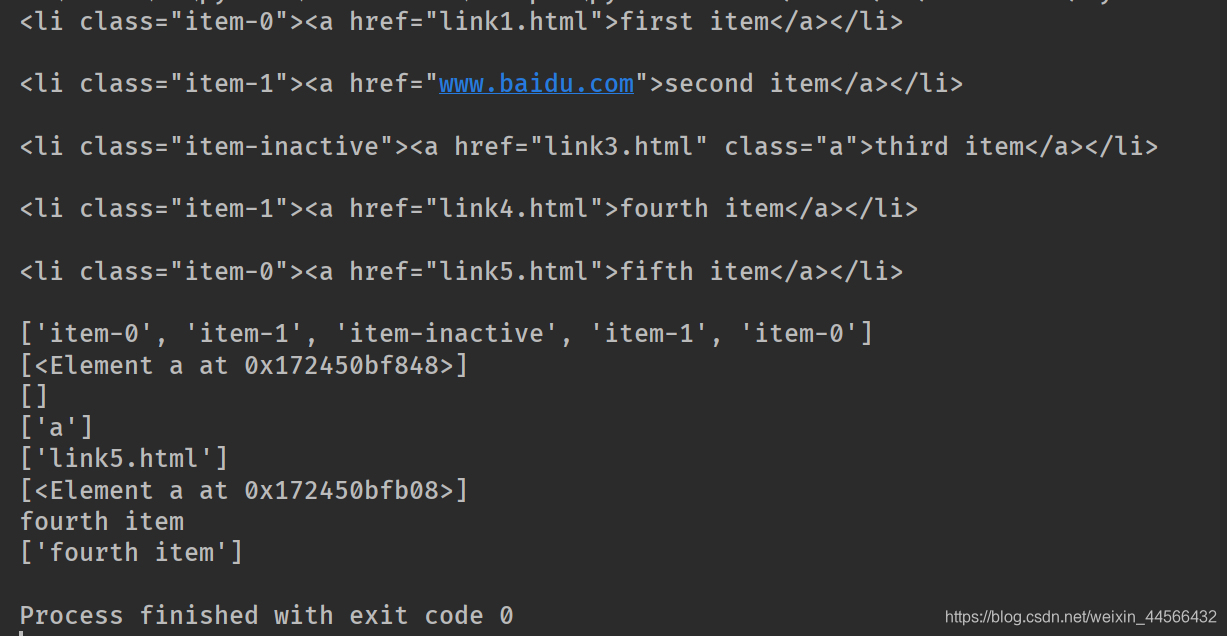
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
#将字符串解析未html文档
html = etree.HTML(text)
print(html)
#字符串序列化html
result = etree.tostring(html).decode('utf-8')
print(result)
3.1.2 Read HTML code from the file:
from lxml import etree
#读取
html2 = etree.parse('text.html')
result2 = etree.tostring(html2).decode('utf-8')
print(result2)When using parse to read HTML files, pay attention to the integrity of the tags in the html file, otherwise an error will be reported.
3.2 Use XPath syntax in lxml
from lxml import etree
html = etree.parse('text.html')
#获取所有li
result1 = html.xpath('//li')
# print(result)
for i in result1:
print(etree.tostring(i).decode('utf-8'))
# 获取所有li元素下所有class 属性值
result2 = html.xpath('//li/@class')
print(result2)
# 获取所有li元素下href = "www.baidu.com"的a
result3 = html.xpath('//li/a[@href="www.baidu.com"]')
print(result3)
# 获取所有li元素下span标签 用//
result4 = html.xpath('//li//span')
print(result4)
# 获取所有li元素下a标签的所有class
result5 = html.xpath('//li/a//@class')
print(result5)
# 获取最后一个li元素下a标签的href对应的值
result6 = html.xpath('//li[last()]/a/@href')
print(result6)
# 获取最后二个li元素下内容
result7 = html.xpath('//li[last()-1]/a')
print(result7)
print(result7[0].text)
# 获取最后二个li元素下内容 第二种方式
result7 = html.xpath('//li[last()-1]/a/text()')
print(result7)
# print(result7[0].text)