Article Directory
-
- 1. Machine learning strategies
- 2. Orthogonalization
- 3. Single number evaluation index
- 4. Meet and optimize indicators
- 5. Training/development/test set division
- 6. Size of development set and test set
- 7. When should I change the development/test set and metrics
- 8. Human performance level
- 9. Avoid deviations
- 10. Understand human performance
- 11. Outstanding performance
- 12. Improve the performance of your model
- Test assignment
Reference:
Wu Enda video class
deep learning notes
1. Machine learning strategies
How to improve the performance of the model
- Collect more data
- Training set diversity (eg, identifying cats, collecting cats in various poses, and counterexamples)
- Training time is longer
- Try different optimization algorithms (such as Adam optimization)
- Larger/smaller neural network
- Try DropOut regularization
- Try to add L2 regularization
- New network structure (modified activation function, number of hidden units)
You can try it, but what if it takes half a year and finally finds it wrong? Then cry!
Need to judge which ones are effective and which ones can be safely discarded .
2. Orthogonalization
There should be no coupling relationship between the various adjusted variables

Locate where the performance bottleneck of the model is, and use corresponding methods to improve
Early stopping is a less orthogonal method.
Stopping too early will affect the accuracy of the training set. At the same time, it can improve the accuracy of the development set.
It affects two things at the same time. Try to use other orthogonal control methods.
3. Single number evaluation index
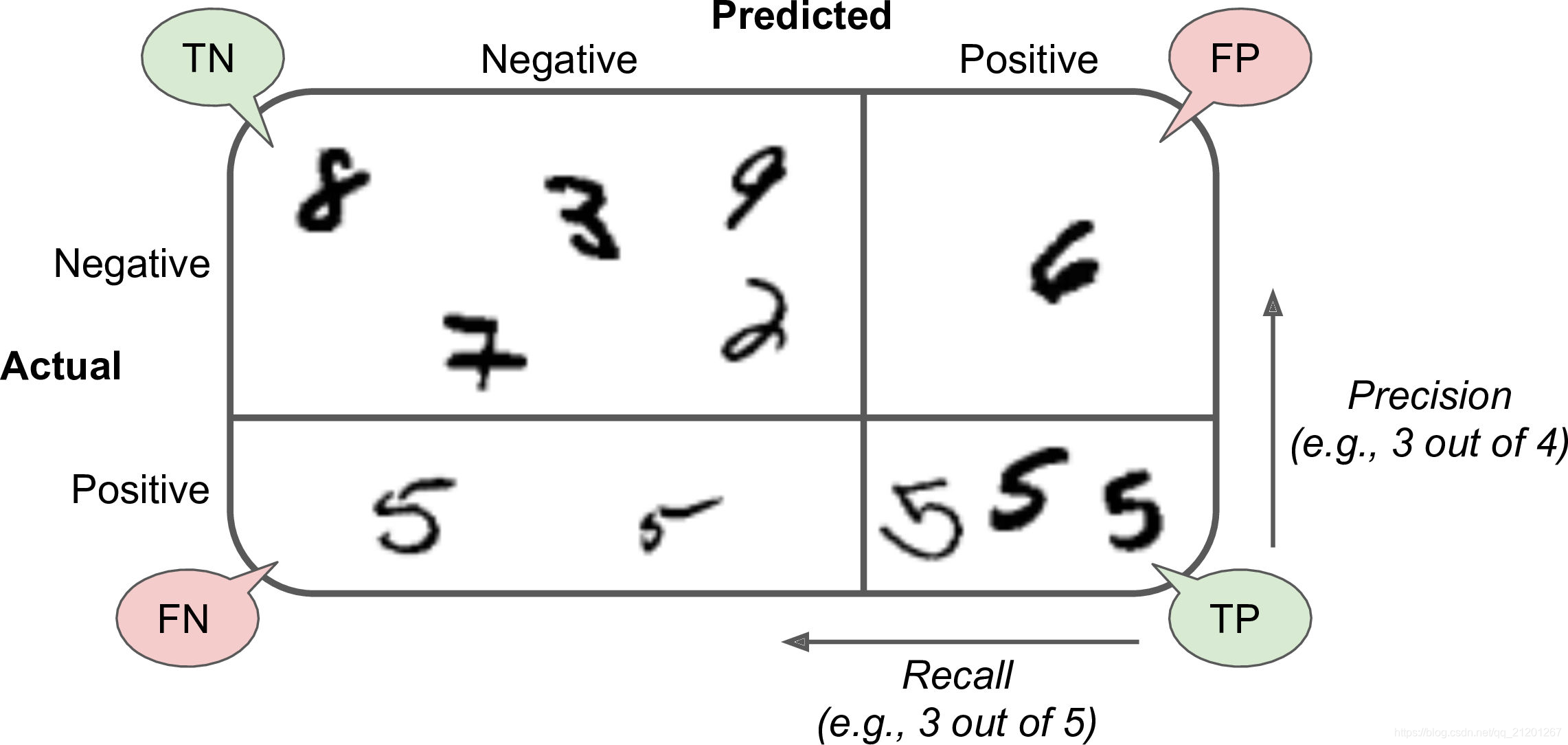
- Accuracy, recall, F1 value (average of the first two)
F 1 = 2 1 precision + 1 recall = 2 ∗ precison ∗ recall precison + recall = T P T P + F N + F P 2 F 1=\frac{2}{\frac{1}{\text {precision}}+\frac{1}{\text {recall}}}=2 * \frac{\text {precison } * \text {recall}}{\text {precison }+\text {recall}}=\frac{T P}{T P+\frac{F N+F P}{2}} F 1=precision1+recall12=2∗precison +recallprecison ∗recall=TP+2FN+FPTP

There is a single real number evaluation indicator that can improve your efficiency or the efficiency of making decisions
4. Meet and optimize indicators

Considering N indicators, sometimes it is reasonable to choose one of them as the optimization indicator .
Try to optimize that indicator, and then the remaining N-1 indicators are all satisfying , which means that as long as they reach a certain threshold, you no longer care about the size of the indicator within the threshold
5. Training/development/test set division

Example: The data of the first 4 areas are used as the development set, and the last 4 areas are used as the test set
- Very bad , they are likely from different distributions
- All data should be randomly shuffled and re-divided
6. Size of development set and test set


7. When should I change the development/test set and metrics

更改测试指标:
误 差 : 1 ∑ w ( i ) ∑ i = 1 m d e v w ( i ) L { ( y ^ ( i ) ≠ y ( i ) ) } 误差: \frac{1}{\sum w^{(i)}} \sum_{i=1}^{m_{d e v}} w^{(i)} \mathcal{L}\left\{\left(\hat{y}^{(i)} \neq y^{(i)}\right) \bigg\}\right. Error difference:∑w(i)1i=1∑mdevw(i)L{
(and^(i)=and(i))}
w (i) = {1 if x (i) is a non-pornographic picture 10 if x (i) is a pornographic picture w^{(i)}=\left\{\begin{array}{cl}1 & \text {if } x^{(i)} \text {is a non-pornographic image} \\ 10 & \text {if} x^{(i)} \text {is a pornographic image}\end{array}\right. w(i)={ 110 if x( i ) is a non-erotic picture if x( I ) is pornography
In the above method, you must go through the data yourself and mark the pornographic pictures
For example: your development/test set are all very clear professional pictures, and the application is finally launched for unprofessional pictures (blurred, bad angle, etc.)
Then change the development/test set and add unprofessional pictures as training data
8. Human performance level
It is natural to compare the level of machine learning with the level of humans. We want machines to do better than humans

For tasks that humans are good at, as long as the machine learning algorithm is worse than humans , you can let people tag the data for you, and there will be more data to feed the learning algorithm and improve the algorithm
9. Avoid deviations

10. Understand human performance


11. Outstanding performance

Case B: Over the 0.5% threshold (lower than the error of the best doctors), there are no clear options and directions to further optimize your machine learning problem
12. Improve the performance of your model
to sum up:
The above method is an improved idea of orthogonalization.

- The gap between the training set error and the Bayesian estimation error: avoidable bias
- The gap between the training set error and the development set error: variance
Improve deviation :
- Larger model
- Training longer, more iterations
- Better optimization algorithms (Momentum, RMSprop, Adam)
- Better new neural network structure
- Better hyperparameters
- Change the activation function, the number of network layers, and the number of hidden units
- Other models (cyclic NN, convolutional NN)
Improve variance :
- Collect more data to train
- Regularization (L2 regularization, dropout regularization, data enhancement)
- Better new neural network structure
- Better hyperparameters
Test assignment
Reference blog post link
My CSDN blog address https://michael.blog.csdn.net/
Long press or scan the QR code to follow my official account (Michael Amin), come on together, learn and make progress together!
