In order to achieve data sharing between different application software, different platforms, and different operating systems, we need XML files for data storage and transmission.
The following is the content of an xml file, which defines a bookstore that contains information about two books
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book id="1">
<name>冰与火之歌</name>
<author>乔治马丁</author>
<year>2014</year>
<price>89</price>
</book>
<book id="2">
<name>安徒生童话</name>
<year>2004</year>
<price>77</price>
<language>English</language>
</book>
</bookstore>1. Parse the XML file
DOM parsing
DOM is a platform-independent analysis method provided by XML. DOM will read the XML document into memory and form a DOM tree structure at a time. When the XML document is too large, it will consume a lot of memory and the reading speed will be affected.
It is worth noting that the DOM not only treats a <tag> </ tag> as a Node node, but also the node attributes and line breaks are regarded as the Node type, so call childNode.getLength () on the first <book> node The method returns 9 child nodes, which includes four <tag> and 5 carriage return and line feed blanks, but the NodeType of the two is different, and two types of nodes can be distinguished according to the type.
Similarly, the text between <name> </ name> is also regarded as a node, so to get the text in it, you need to get the child nodes of the name node and then get the text value. You can also use the getText (Content) method to get the text content between name nodes, with the same effect.
import org.w3c.dom.*;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.IOException;
public class DOMParse {
public static void main(String[] args) throws ParserConfigurationException, IOException, SAXException {
// 1、创建DocumentBuilderFactory对象
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
// 2、创建DocumentBuilder对象
DocumentBuilder db=dbf.newDocumentBuilder();
// 3、加载xml文件为document对象
Document doc=db.parse("src/com/xml/books.xml");
// 获取所有book节点集合
NodeList bookList=doc.getElementsByTagName("book");
int num=bookList.getLength(); // 获取节点集合的长度
for (int i = 0; i < num; i++) {
Node book=bookList.item(i); // 获取集合中的一个节点
NamedNodeMap attrs=book.getAttributes(); // 获取节点的所有属性
for (int j = 0; j < attrs.getLength(); j++) { // 遍历节点的属性集
Node attr=attrs.item(j); // 获取属性集中的一个属性
System.out.println(attr.getNodeName()); // 输出属性名
System.out.println(attr.getNodeValue()); // 输出属性值
}
// 知道具体属性名时可直接通过属性名获取属性值
Element bookElement=(Element)book; // 此时属性类型从Node转换为Element
String s=bookElement.getAttribute("id");
System.out.println(s);
// 遍历book的所有子节点
NodeList childNodes=book.getChildNodes();
for (int j = 0; j < childNodes.getLength(); j++) {
Node childNode=childNodes.item(j);
// 根据Node类型区分元素节点和文本节点
if (childNode.getNodeType()==Node.ELEMENT_NODE){
System.out.println("节点名:"+ childNode.getNodeName());
// 通过取子节点得到文本值
System.out.println("值为:"+childNode.getFirstChild().getNodeValue());
// 直接获取文本值
System.out.println("文本为:"+ childNode.getTextContent());
}
}
}
}
}
2. SAX analysis
SAX is an event-driven XML parsing method provided by Java official. It is different from the way that DOM loads the entire xml document. SAX is parsing while loading the XML document, which consumes little memory. But compared with the DOM tree structure, SAX access data has no structure, which is not easy to understand and encode, and because its method is executed asynchronously, it is difficult to access different data at the same time.
The process of using SAX is as follows. First create a Factory instance, then create a parser instance through it, then create a handler object inherited from the DefaultHandler class, and then parse the document through parser.parse (), passing in two parameters, the first one Is the document path, the second is the handler.
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
// 1、获取SAXParserFactory实例
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2、获取Parser实例
SAXParser parser = factory.newSAXParser();
// 3、创建handler实例
SAXHandler saxHandler=new SAXHandler();
// 4、解析文档
parser.parse("src/com/xml/books.xml",saxHandler);
}The handler traverses from the document and calls the startDocument (), startElement (), characters (), endElement (), and endDocument () methods in turn.
The startElement () method is triggered when it encounters a start tag such as <book>, <author>, its parameter qName is the tag name, attributes is the tag's attribute array
The characters () method is triggered when a string between tags is encountered, you can define the operation on the string, these strings also include meaningless blank line breaks
The endELement () method is triggered when an end tag is encountered </ book>
If you need to share variables and parameters between the above methods, you can achieve it by defining global variables
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXHandler extends DefaultHandler {
@Override // 文档开始执行
public void startDocument() throws SAXException {
super.startDocument();
}
@Override // 开始标签执行
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
if (qName.equals("book")){ // 解析<book>节点的属性
System.out.println("======book解析开始======");
// 根据具体属性名id获取属性值
String value=attributes.getValue("id");
System.out.println("book的属性值:"+value);
// 未知属性值,遍历所有属性
int num=attributes.getLength();
for (int i = 0; i < num; i++) {
System.out.print(attributes.getQName(i)+" : "); // 获取属性名
System.out.print(attributes.getValue(i)+"---"); // 获取属性值
}
}else {
System.out.print(qName+" : ");
}
}
@Override // 遇到字符
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
String s=new String(ch,start,length);
if (!s.trim().equals("")){ // 排除换行字符串节点
System.out.print(s+" ");
}
}
@Override // 结束标签
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
if (qName.equals("book")) {
System.out.println();
System.out.println("======book解析结束======");
}
}
@Override // 文档结束执行
public void endDocument() throws SAXException {
super.endDocument();
}
}
The results are as follows:
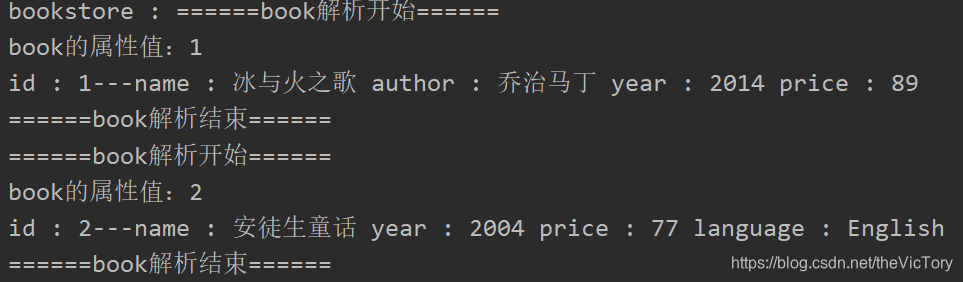
3 、 JDOM
Based on SAX, third-party open source organizations have written JDOM and DOM4J two parsing methods, so when using JDOM, you need to first download and import jar packages.
JDOM's getChildren () method can be used to easily obtain the label's child nodes and traverse
As shown below, the book content read from XML is saved to the Book object, and the object is stored in the ArrayList list
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import org.jdom2.Attribute;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;
import com.imooc.entity.Book; // 引入创建的Book对象
public class JDOMTest {
// 创建用于保存Book对象的列表
private static ArrayList<Book> booksList = new ArrayList<Book>();
public static void main(String[] args) {
// 进行对books.xml文件的JDOM解析
// 准备工作
// 1.创建一个SAXBuilder的对象
SAXBuilder saxBuilder = new SAXBuilder();
InputStream in;
try {
// 2.创建一个输入流,将xml文件加载到输入流中
in = new FileInputStream("src/res/books.xml");
InputStreamReader isr = new InputStreamReader(in, "UTF-8");
// 3.通过saxBuilder的build方法,将输入流加载到saxBuilder中
Document document = saxBuilder.build(isr);
// 4.通过document对象获取xml文件的根节点
Element rootElement = document.getRootElement();
// 5.获取根节点下的子节点的List集合,并进行遍历
List<Element> bookList = rootElement.getChildren();
for (Element book : bookList) {
Book bookEntity = new Book();
System.out.println("======开始解析第" + (bookList.indexOf(book) + 1)+ "书======");
// 解析book的属性集合
List<Attribute> attrList = book.getAttributes();
// //知道节点的属性名称时,获取节点值的方法
// book.getAttributeValue("id");
// 遍历attrList(针对不清楚book节点下属性的名字及数量)
for (Attribute attr : attrList) {
// 获取属性名
String attrName = attr.getName();
// 获取属性值
String attrValue = attr.getValue();
System.out.println("属性名:" + attrName + "----属性值:"+ attrValue);
if (attrName.equals("id")) {
bookEntity.setId(attrValue);
}
}
// 对book节点的子节点的节点名以及节点值的遍历,并将信息保存到Book对象
List<Element> bookChilds = book.getChildren();
for (Element child : bookChilds) {
System.out.println("节点名:" + child.getName() + "----节点值:" + child.getValue());
if (child.getName().equals("name")) {
bookEntity.setName(child.getValue());
}
else if (child.getName().equals("author")) {
bookEntity.setAuthor(child.getValue());
}
else if (child.getName().equals("year")) {
bookEntity.setYear(child.getValue());
}
else if (child.getName().equals("price")) {
bookEntity.setPrice(child.getValue());
}
else if (child.getName().equals("language")) {
bookEntity.setLanguage(child.getValue());
}
}
System.out.println("======结束解析第" + (bookList.indexOf(book) + 1)+ "书======");
booksList.add(bookEntity);
bookEntity = null;
System.out.println(booksList.size());
// 输出保存在列表中的第一个对象的id和name
System.out.println(booksList.get(0).getId());
system.out.println(booksList.get(0).getName());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
4 、 DOM4J
DOM4J is also a third-party open source toolkit, which has faster execution speed and flexibility than JDOM
You can get the child node iterator of the label through the elementIterator () method, so as to realize the traversal of the node, and its usage is as follows:
package com.imooc.dom4jtest;
import java.io.File;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class DOM4JTest {
public static void main(String[] args) {
// 创建SAXReader的对象reader
SAXReader reader = new SAXReader();
try {
// 通过reader对象的read方法加载books.xml文件,获取docuemnt对象。
Document document = reader.read(new File("src/res/books.xml"));
// 通过document对象获取根节点bookstore
Element bookStore = document.getRootElement();
// 通过element对象的elementIterator方法获取迭代器
Iterator it = bookStore.elementIterator();
// 遍历迭代器,获取根节点中的信息(书籍)
while (it.hasNext()) {
System.out.println("=====开始遍历某一本书=====");
Element book = (Element) it.next();
// 获取book的属性名以及 属性值
List<Attribute> bookAttrs = book.attributes();
for (Attribute attr : bookAttrs) {
System.out.println("属性名:" + attr.getName() + "--属性值:"
+ attr.getValue());
}
Iterator itt = book.elementIterator();
while (itt.hasNext()) {
Element bookChild = (Element) itt.next();
System.out.println("节点名:" + bookChild.getName() + "--节点值:" + bookChild.getStringValue());
}
System.out.println("=====结束遍历某一本书=====");
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
2. Generate XML
DOM generation
DOM will create a DOM tree in memory to temporarily store the node structure, so if you need to modify the DOM structure frequently, it is more appropriate to use DOM than SAX. Fast.
To use the DOM, you first need to generate a document object, then create a node from the document, and then use the parent node to add child nodes.
Finally, the XML file is generated by the transform () method of the Transformer object. Transform () requires two parameters, the first is the source document to be output, and the second is the output file stream
public static void main(String[] args) throws ParserConfigurationException, TransformerException {
// 通过嵌套定义创建一个DOM文档对象doc
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document doc=db.newDocument();
// 通过doc创建节点
Element bookstore=doc.createElement("bookstore");
Element book=doc.createElement("book");
book.setAttribute("id","1"); // 为节点添加属性
Element name=doc.createElement("name");
name.setTextContent("百年孤独"); // 添加节点之间的文本内容
// 将子节点添加到父节点
book.appendChild(name);
bookstore.appendChild(book);
doc.appendChild(bookstore);
// 通过Transformer对象输出xml文件
TransformerFactory tff=TransformerFactory.newInstance();
Transformer tf=tff.newTransformer();
tf.setOutputProperty(OutputKeys.INDENT,"yes"); // 设置输出xml文件换行
DOMSource domSource=new DOMSource(doc); // 要输出的文档对象
StreamResult streamResult=new StreamResult(new File("src/com/xml/DOMout.xml")); // 输出的目标文件
tf.transform(domSource,streamResult);
}SAX generation
The use of SAX generation also needs to first generate a handler and Transformer object through the nested definition, the output file can be set through the transformer, and the document can be operated through the handler. Before operating the document, you need to associate the handler with the output file stream.
After that, call the relevant method to edit the document through the handler. Like the tag tag, the startElement / endElement methods are used in pairs. Use the attr object to set and add tag attributes. Use the characters () method to add text content between tags.
public static void main(String[] args) throws TransformerConfigurationException, FileNotFoundException, SAXException {
// 生成SAX的Transformer对象
SAXTransformerFactory stf=(SAXTransformerFactory)SAXTransformerFactory.newInstance();
TransformerHandler handler=stf.newTransformerHandler();
Transformer transformer=handler.getTransformer();
transformer.setOutputProperty(OutputKeys.ENCODING,"UTF-8"); // 设置输出属性
// 创建Result对象并与handler关联
Result result=new StreamResult(new FileOutputStream(new File("src/com/xml/SAXout.xml")));
handler.setResult(result);
// 通过handler编辑xml文件
handler.startDocument();
AttributesImpl attr=new AttributesImpl(); // 创建用于编辑节点属性的attr对象
handler.startElement("","","bookstore",attr); // 结点开始
attr.clear(); // 每次新设置一个属性attr之前都需要清空之前的
attr.addAttribute("","","id","","1"); // 定义attr并添加到节点
handler.startElement("","","book",attr);
attr.clear();
handler.startElement("","","name",attr);
String s="平凡的世界";
handler.characters(s.toCharArray(),0,s.length()); // 向节点间添加文本
handler.endElement("","","name"); // 结束节点
handler.endElement("","","book");
handler.endElement("","","bookstore");
handler.endDocument();
}DOM4J generation
Although the creation speed of DOM4J is slower than SAX, it is faster than JDOM, and its code is relatively concise. It is a common analysis and generation method in development.
DOM4J can directly add nodes after creating the document object, and because it is a packaged library, the code call is very simple compared to the previous SAX and DOM methods. The creation of nodes and the addition of attributes require only one line of code. The document is output through XMLWriter, writer () accepts two parameters, the first is the document output stream, the second optional parameter is the format object, and the format can automatically set the output carriage return and line feed and other spaces.
package com.xml;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class DOM4jGenerator {
public static void main(String[] args) throws IOException {
// 创建DOM4J文档对象
Document document=DocumentHelper.createDocument();
// 从上到下创建节点
Element bookstore=document.addElement("bookstore"); // 创建并添加子节点
Element book=bookstore.addElement("book");
book.addAttribute("id","1"); // 添加节点属性
Element name=book.addElement("name");
name.setText("冰与火之歌"); // 设置标签之间的文本
OutputFormat format= OutputFormat.createPrettyPrint(); // 设置输出文档的格式
format.setEncoding("UTF-8");
// 将文档输出
FileOutputStream outputStream=new FileOutputStream(new File("src/com/xml/DOM4Jout.xml"));
XMLWriter writer=new XMLWriter(outputStream, format);
writer.write(document);
writer.close();
}
}
JDOM generation
Like DOM4J, JDOM is also a library, but it needs a new node first, and then add child nodes by calling addContent () from the parent node.
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.output.Format;
import org.jdom2.output.XMLOutputter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class JDOMGenerator {
public static void main(String[] args) throws IOException {
Element bookstore = new Element("bookstore"); //创建根节点
Document document = new Document(bookstore); // 将根节点添加到document对象
// 创建并添加子节点
Element book = new Element("book");
book.setAttribute("id", "1"); // 为节点添加属性
bookstore.addContent(book); // 父节点添加子节点
Element name = new Element("name");
name.setText("冰与火之歌");
book.addContent(name);
// 输出文档
Format format = Format.getPrettyFormat(); // 设置输出格式
format.setEncoding("GBK");
XMLOutputter outputter = new XMLOutputter(format); // 可以传入格式设置对象作为参数
FileOutputStream outputStream = new FileOutputStream(new File("src/com/xml/JDOMout.xml"));
outputter.output(document, outputStream);
}
}
