Foreword
In this chapter, we will explain the queue in the high concurrency solution. Message queuing has gradually become the core means of internal communication in enterprise IT systems. It has a series of functions such as low coupling, reliable delivery, broadcast, flow control, and final consistency, and has become one of the main means of asynchronous RPC.
Subject Summary
- Basic introduction of high concurrent message queue
- Message queue features
Main content
1. Basic introduction of high concurrency message queue
1. Examples
After placing an order in the shopping mall, I hope that the buyer can receive SMS or email notification. There is a way to call the API for sending SMS after the logic of placing an order. If the server is slow to respond, the SMS client has problems, and many other reasons, the buyer cannot receive the SMS normally, then continue to retry or give up directly. What about sending? No matter which one you choose, it will become complicated in implementation.
How is the message queue solved? It can be said that the process of sending short messages is encapsulated into a message and sent to the message queue. The message queue processes the messages in the queue in a certain order, and at a certain moment, the message sent by the short message will be processed. The message queue will notify a service to send the short message. If it is successful, the message will be processed as soon as it is put in the queue. If something goes wrong, you can put the message in the message queue again and wait for processing. If you use the message queue in the above example, the advantage is to decouple the process of sending text messages from other functions. When sending text messages, you only need to ensure that this message is sent to the message queue, and then you can handle other things after sending the text message. Secondly, the system design has become simple, without having to think too much about sending short messages in the scenario of placing an order, but handed over to the message queue to handle this matter. And can guarantee that the message will be sent out, as long as the message is not sent successfully, it will continue to be added to the message queue. If there is a problem with the SMS service, wait until the service is restored and the message queue can be sent out, but it is not so timely.
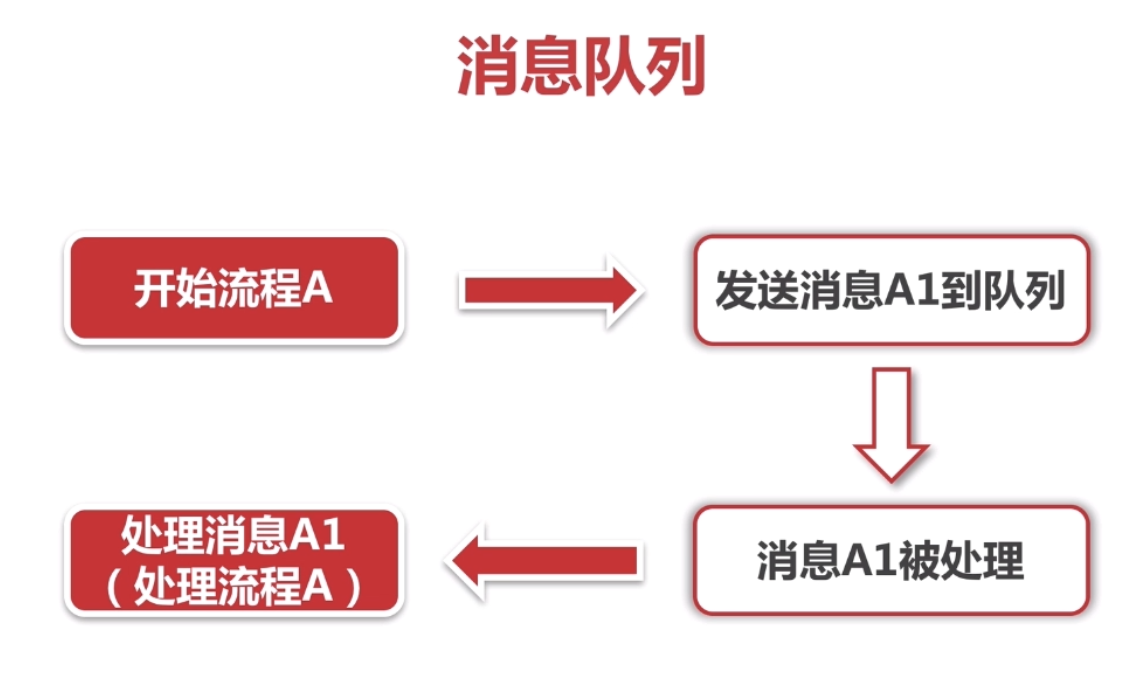
As a final point, let's assume that after sending the SMS, the email will be sent. With the message queue, we do not have to wait synchronously. We can directly process in parallel. The core process of placing an order can be completed faster. This can increase the asynchronous processing capacity of the application, reduce or even impossible to appear and find the phenomenon. Recall that when we enter the mobile phone number to send the verification code on the website, we can't receive the text message for a long time, and the time of the SMS interface has expired. Something went wrong when the SMS was sent, or the server network opened a small gap, and there might be too many messages in the message queue for a certain period of time to be processed.
2. Benefits
1. Successfully completed an asynchronous decoupling process. When sending SMS, just make sure to put it in the message queue, and then do the following things. A transaction only cares about the essential process and needs to depend on other things, but when it is not so important, it can be notified without waiting for the result. Each member does not have to be influenced by other members, but can be more independent and can only be contacted through a simple container.
For our order system, after the final payment of the order is successful, you may need to send SMS points to the user, but this is not the core process of our system. If the speed of the external system is slow (for example, the speed of the SMS gateway is not good), the time of the main process will be much longer. The user certainly does not want to click to pay for several minutes before seeing the result. Then we only need to inform the SMS system that "we have successfully paid", and we don't have to wait for it to finish processing.
3. Application scenarios
There are many scenarios where message queues can be used
The main feature is asynchronous processing, and the main purpose is to reduce request response time and decoupling. Therefore, the main usage scenario is to put operations that are time-consuming and do not require immediate (synchronous) return results as messages into the message queue.
In the usage scenario, for example:
suppose the user registers in your software, and the server will do these operations after receiving the user's registration request:
- Verify the user name and other information, if no problem will add a user record in the database
- If registering by email, a successful registration email will be sent to you, and mobile phone registration will send an SMS
- Analyze the user's personal information to recommend some like-minded people to him in the future, or recommend him to those people
- Send users a system notification with instructions
and many more……
But for the user, the registration function actually only needs the first step, as long as the server stores his account information in the database, he can log in to do what he wants to do. As for other things, do I have to complete them all in this request? Is it worth the user to waste time waiting for you to deal with these things that are not important to him? Therefore, after the first step is completed, the server can put other operations into the corresponding message queue and then immediately return the user results, and the message queue performs these operations asynchronously.
Or there is a case where there are a large number of users registering your software at the same time, no matter how high the concurrency is, the registration request starts to have some problems, such as the mail interface cannot bear, or the large amount of calculations when analyzing the information makes the CPU full, which will appear Although user data records were quickly added to the database, it was stuck when sending emails or analyzing information, resulting in a significant increase in the response time of the request, and even a timeout, which was a bit uneconomical. Faced with this situation, these operations are generally put into the message queue (producer consumer model), the message queue is processed slowly, and the registration request can be completed quickly, without affecting the user's use of other functions.
Second, the characteristics of the message queue
1. Four characteristics
- Unrelated to business: only do message distribution
- FIFO (First In First Out): first delivery first arrival
- Disaster tolerance: dynamic addition and deletion of nodes and persistence of messages
- Performance: Increased throughput and improved system internal communication efficiency
2. Why do you need a message queue?
- The speed or stability of [production] and [consumption] are inconsistent.
3. Benefits of Message Queuing
-
Business decoupling : It is the most essential problem solved by the message queue. The so-called decoupling is a process that cares about the core of a thing and needs to rely on other systems, but it is not so important. It can be notified without waiting for the result. In other words, the message-based model is concerned with notification rather than processing. For example, there is a product center inside a travel platform. The product center is connected to multiple data sources such as the main station, mobile background, and tourism supply chain. The downstream is connected to the display system such as recommendation system and API system. When the upstream data changes, At the time, if you do not use message queues, you will inevitably need to call the interface to update the data. This depends on the stability and processing power of the interface of the product center. However, as a product center for tourism, perhaps only for the self-built supply of tourism The success of the update of the chain product center is their concern. For external systems such as group purchases, the success of the update of the product center is not the responsibility of failure. They only need to ensure that they are notified when the information changes. For the downstream, there may be a series of requirements such as updating the index and updating the cache. For the product center, these are not the responsibilities. To put it bluntly, if they pull data regularly, they can also ensure that the data is updated, but the real-time is not so strong, but if the interface method is used to update the data, it is obviously too heavy for the product center, and only one needs to be released at this time. The notification of product ID change is more reasonable to be processed by the downstream system. Let's take another example: For the order system, after the final payment of the order is successful, we may have to send a text message notification to the user, but in fact this is no longer the core process of the system. If the speed of the external system is slow, such as the speed of the SMS gateway is not good , Then the time of the main process will be much longer, the user certainly does not want to click to see the result after a few minutes, then we only need to notify the SMS system that we have paid successfully, you just send a SMS notification, it does n’t have to be Wait for it to finish processing before ending.
-
Final consistency : Final consistency refers to the state of the two systems remaining consistent, either succeeding or failing. Of course there is a time limit, the faster the better in theory, but in fact, under various abnormal conditions, there may be a certain delay to reach the final consistent state, but the state of the last two systems is the same.
There are some message queues in the industry for "ultimate consistency", such as Notify (Ali) and QMQ (Where to go), etc. The original intention of the design is for highly reliable notifications in the transaction system.
To understand the final consistency with a bank's transfer process, the need for transfer is simple. If the system A successfully deducts money, the system B must add money successfully. Otherwise, roll back together as if nothing happened.
However, there are many possible accidents in this process:(1) A deducts money successfully, and fails to call the B plus money interface.
(2) A successfully deducted money. Although the call to the B plus money interface was successful, the network exception caused a timeout when obtaining the final result.
(3) A deducts money successfully, B fails to add money, A wants to roll back the deducted money, but A machine is down.
It can be seen that it is really not so easy to really make this seemingly simple thing. From a technical point of view, all common cross-JVM consistency issues are:
(1) Strong consistency, distributed transactions, but the landing is too difficult and the cost is too high, no more specific introduction here, I want to know Baidu.
(2) The final consistency is mainly by means of "recording" and "compensation". Before doing all the uncertain things, first record the things and then do the uncertain things. The result may be: success, failure or uncertainty. "Uncertain" (such as timeout) can be equivalent to failure . If you succeed, you can clear out the recorded things. For failures and uncertainties, you can rely on timed tasks and other methods to re-engage all failed things until you succeed.
Going back to the previous example, when the system successfully deducts money from A, the system records the "notification" to B in the library (in order to ensure the highest reliability, the system can notify the B system to add money and deduct money successfully Things are maintained in a local transaction). If the notification is successful, the record is deleted. If the notification fails or is uncertain, we rely on a scheduled task to inform us compensatively until we update the status to the correct one. It should be noted that the design of message queues such as Kafka has the possibility of losing messages at the design level. For example, regular flashing may cause the loss of messages. Even if it only loses one thousandth of the message, the business uses other Means must also ensure that the results are correct. -
Broadcast : One of the basic functions of the message queue is to broadcast. If there is no message queue, whenever a new business party accesses, we have to jointly debug the new interface. With the message queue, we only need to care about whether the message is delivered to the queue. As for who wants to subscribe, it is a downstream matter, which undoubtedly greatly reduces the workload of development and joint debugging.
-
Speed-up : Suppose we still need to send mail. With the message queue, we do n’t need to wait synchronously. We can directly process in parallel, and the core tasks can be completed faster. Enhance the asynchronous processing capability of the business system. It is almost impossible to appear and discover elephants.
-
Peak shaving and flow control : For requests that do not require real-time processing, when the amount of concurrency is particularly large, you can first cache in the message queue and then send them to the corresponding service for processing. Imagine that upstream and downstream have different processing capabilities for things. For example, it is not a magical thing for the Web front end to withstand tens of millions of requests per second, just add a little more machines, and then build some LVS load balancing equipment and Nginx. However, the processing power of the database is very limited. Even with the use of SSD plus sub-database and sub-table, the processing power of a single machine is still at 10,000 levels. Due to cost considerations, we cannot expect the number of database machines to catch up with the front end. This problem also exists between the system and the system. For example, due to the short board effect, the speed of the short message system is stuck on the gateway (hundreds of requests per second), and the concurrency with the front end is not an order of magnitude. However, if the user receives the text message about half a minute in the evening, there is generally no problem. If there is no message queue, complex schemes such as negotiation and sliding windows between the two systems are not impossible. However, the exponential growth of system complexity will inevitably store it upstream or downstream, and it will deal with a series of problems such as timing and congestion. And whenever there is a gap in processing power, a separate set of logic needs to be developed to maintain this set of logic. Therefore, it is a relatively common way to use the intermediate system to dump the communication content of the two systems and process these messages when the downstream system has the ability to process these messages. All in all, the message queue is not a panacea. For those that require strong transaction guarantees and are delay-sensitive, RPC is superior to message queues. For things that are irrelevant or very important to others but not so concerned about yourself, you can use the message queue to do it. Message queues that support eventual consistency can be used to handle "distributed transaction" scenarios where latency is not so sensitive, and may be a better way of processing than bulky distributed transactions. When there is a gap in the processing capabilities of upstream and downstream systems, use message queues as a general "funnel." When the downstream is capable of processing, distribute it again. If there are many downstream systems concerned about the notifications sent by your system, use the message queue decisively.
4. Message queue example
(1) Here we only target Kafka and RabbitMQ as examples
- Kafka
- RabbitMQ
...
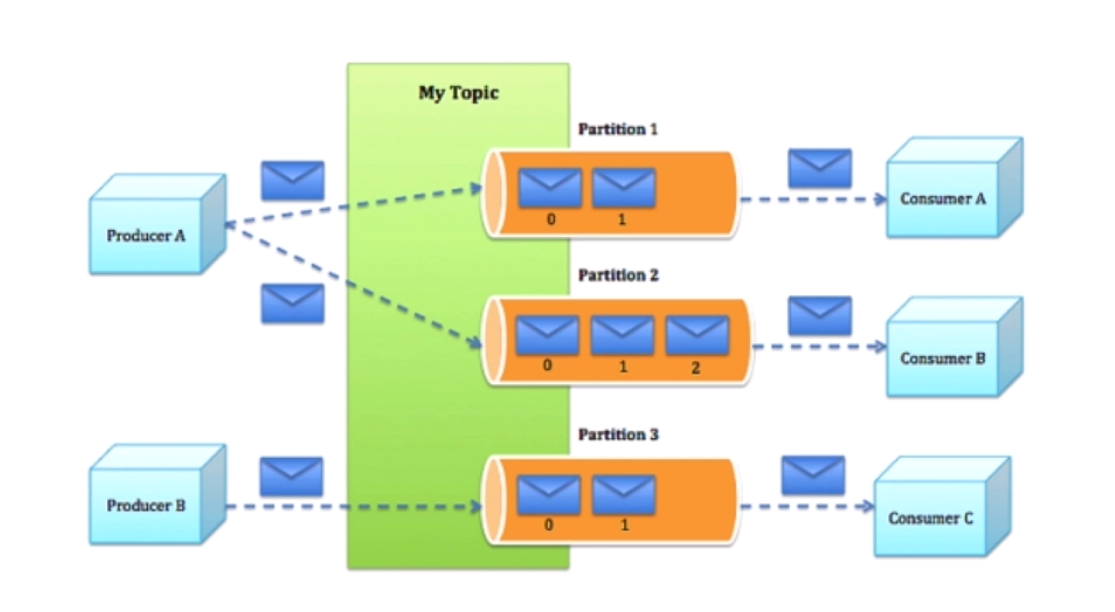
(2) Kafka is an Apache project, a high-performance, cross-language, distributed publish and subscribe message queue system.
Structure diagram
characteristic
- Fast lasting. The message persistence capability is provided in a manner with a time complexity of O (1), and the access performance of constant time complexity can be guaranteed even for data above the terabyte level.
- High throughput. Even on very cheap commercial machines, it can achieve the transmission of more than 100K messages per second in a single machine. It is a completely distributed system. Its Broker, Producer, and Consumer (refer to basic terminology) are all native, automatically support distributed and automatic load balancing, and it supports parallel loading of Hadoop data.
- Support message partitioning between Kafka Servers and distributed consumption, while ensuring the sequential transmission of messages within each Partition.
- It also supports offline data processing and real-time data processing.
- Scale out: Support online horizontal expansion.
Basic terminology
- Broker: The Kafka cluster contains one or more servers. Such servers are called brokers.
- Topic: Every message published to the Kafka cluster has a category, which is called Topic. (Physically, the messages of different topics are stored separately. Although logically, the messages of one topic are stored on one or more brokers, but users only need to specify the topic of the message to produce or consume data without having to care where the data is stored)
- Partition: Partition is a physical concept, each Topic contains one or more Partitions.
- Producer: responsible for publishing messages to Kafka broker.
- Consumer: A message consumer, a client that reads messages from Kafka broker.
- Consumer Group: Each Consumer belongs to a specific Consumer Group (you can specify the group name for each Consumer, if you do not specify the group name, it belongs to the default group).
(3) Next, let's take a look at RabbitMQ.
Structure diagram
Basic definition in RabbitMQ
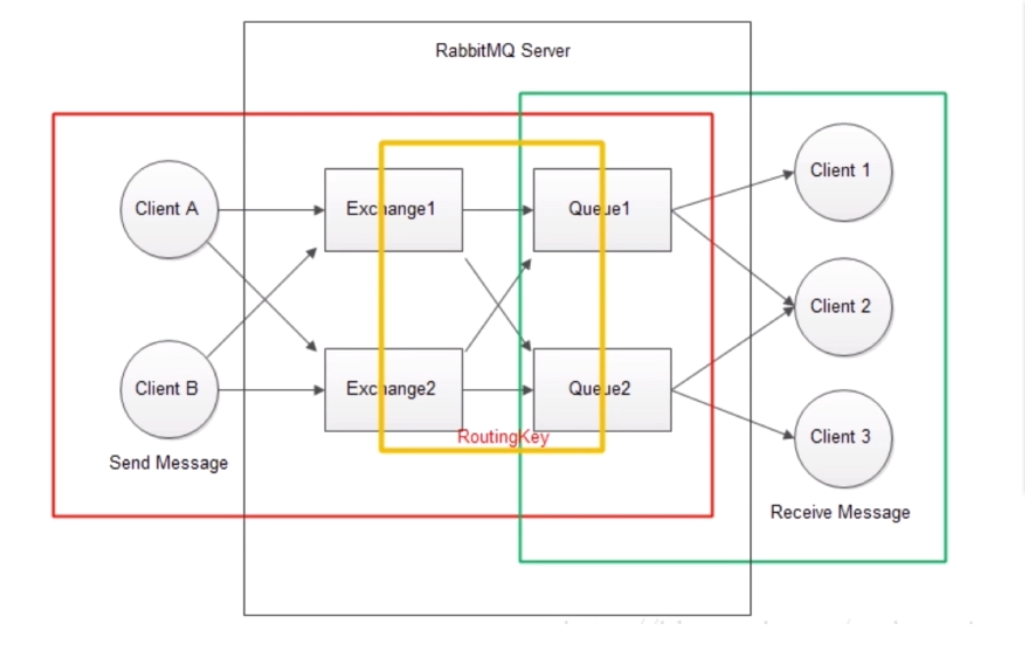
RabbitMQ Server : Provides a message processing from Producer to Consumer.
Exchange : Push messages to the queue while receiving messages from the publisher.
Producers can only send messages to exchange. The exchange is responsible for sending messages to queues. Procuder Publish's Message enters exchange. Exchange will process the received message according to the routingKey, determine whether the message should be pushed to the specified queue or multiple queues, or simply ignore the message. These rules are defined by the exchange type (exchange type). The main types are direct, topic, headers, and fanout. Use different types for different scenarios.
The queue is also bound by the routing keys. The switch will accurately match the binding key and routing key to determine which queue the message should be distributed to.
Queue : Message queue. Receive the message from the exchange, and then take it out by the consumer. Exchange and queue can be one-to-one or one-to-many, and their relationship is bound by routingKey.
Producer : Client A & B, producer, the source of the message, the message must be sent to the exchange. Instead of directly to the queue
Consumer : Client 1, 2, 3 consumers, get messages directly from the queue for consumption, rather than get messages from the exchange for consumption.
(4) Kafka and rabbitmq use springboot as an example. To simplify the content, the two run the test at the same time.
For the installation of kafka under windows, please refer to: https://www.jianshu.com/p/d64798e81f3b
Package architecture

KafkaReceiver.java
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* 接收端
*/
@Component
@Slf4j
public class KafkaReceiver {
@KafkaListener(topics={TopicConstants.TEST})
public void receive(ConsumerRecord<?,?> record){
log.info("record:{}",record);
}
}
KafkaSender.java
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.practice.mq.Message;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.Date;
/**
* 发送端
*/
@Component
@Slf4j
public class KafkaSender {
@Resource
private KafkaTemplate<String,String> kafkaTemplate;
private Gson gson = new GsonBuilder().create();
public void send(String msg) {
Message message = new Message();
message.setId(System.currentTimeMillis());
message.setMsg(msg);
message.setSendTime(new Date());
log.info("send Message:{}",message);
kafkaTemplate.send(TopicConstants.TEST,gson.toJson(message));
}
}
TopicConstants.java
public interface TopicConstants {
//定义一下我们需要使用Topic的字符串
String TEST = "test";
String MESSAGE = "message";
}
QueuesContants.java
public interface QueuesConstants {
String TEST="test";
String MESSAGE="message";
}
RabbitMQClient.java
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
@Component
public class RabbitMQClient {
@Resource
private RabbitTemplate rabbitTemplate;
public void send(String message){
//发送到指定队列
rabbitTemplate.convertAndSend(QueuesConstants.TEST,message);
}
}
RabbitMQServer.java
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitMQConfig {
@Bean
public Queue queue(){
//定义好要发送的队列
return new Queue(QueuesConstants.TEST);
}
}
Message.java
import lombok.Data;
import java.util.Date;
@Data
public class Message {
private Long id;
private String msg;
private Date sendTime;
}
MQController.java
import com.practice.mq.kafka.KafkaSender;
import com.practice.mq.rabbitmq.RabbitMQClient;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.annotation.Resource;
@Controller
@RequestMapping("/mq")
public class MQController {
@Resource
private RabbitMQClient rabbitMQClient;
@Resource
private KafkaSender kafkaSender;
@RequestMapping("/send")
@ResponseBody
public String send(){
String message = "message";
rabbitMQClient.send(message);
kafkaSender.send(message);
return "success";
}
}
Maven dependencies used (here combined with springboot)
<!--kafka-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!--Gson-->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.7</version>
</dependency>
<!-- rabbitmq依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
application.properties configuration
#============== kafka ===================
# 指定kafka server的地址,集群配多个,中间,逗号隔开
spring.kafka.bootstrap-servers=127.0.0.1:9092
spring.kafka.consumer.group-id=test
#=============== provider =======================
# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
spring.kafka.producer.retries=0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
spring.kafka.producer.batch-size=16384
# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
spring.kafka.producer.buffer-memory=33554432
#procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:
#acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。
#acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。
#acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。
#可以设置的值为:all, -1, 0, 1
spring.kafka.producer.acks=1
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
Browser runs " http://127.0.0.1:8090/mq/send"
console to print
rabbitmq:
...
2020-04-19 02:09:12.040 INFO 31676 --- [nio-8090-exec-1] com.practice.mq.kafka.KafkaSender : send Message:Message(id=1587233352040, msg=message, sendTime=Sun Apr 19 02:09:12 GMT+08:00 2020)
2020-04-19 02:09:12.048 INFO 31676 --- [cTaskExecutor-1] com.practice.mq.rabbitmq.RabbitMQServer : message:message
2020-04-19 02:09:12.054 INFO 31676 --- [nio-8090-exec-1] o.a.k.clients.producer.ProducerConfig : ProducerConfig values:
kafka:
...
2020-04-19 02:09:12.070 INFO 31676 --- [nio-8090-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka version : 2.0.0
2020-04-19 02:09:12.070 INFO 31676 --- [nio-8090-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka commitId : 3402a8361b734732
2020-04-19 02:09:12.076 INFO 31676 --- [ad | producer-1] org.apache.kafka.clients.Metadata : Cluster ID: i1-NXUmvQRyaT-E27LPozQ
2020-04-19 02:09:12.106 INFO 31676 --- [ntainer#0-0-C-1] com.practice.mq.kafka.KafkaReceiver : record:ConsumerRecord(topic = test, partition = 0, offset = 5, CreateTime = 1587233352082, serialized key size = -1, serialized value size = 73, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = {"id":1587233352040,"msg":"message","sendTime":"Apr 19, 2020 2:09:12 AM"})
OK, then the simple example of these two queues is over!