Python gives the impression that it is very convenient to crawl webpages. This productivity is provided by the
two modules urllib and requests.
Urllib for network data collection
urllib library
official document address: https://docs.python.org/3/library/urllib.html
urllib library is Python's built-in HTTP request library, including the following modules:
(1) urllib.request: request module
(2 ) urllib.error: exception handling module
(3) urllib.parse: parsing module
(4) urllib.robotparser: robots.txt parsing module
urllib library: urlopen
urlopen makes simple website requests and does not support complex functions such as authentication, cookies and other advanced HTTP functions.
To support these functions, you must use the OpenerDirector object returned by the build_opener () function. 
urllib library: User-Agent requests a website after disguising
many websites. In order to prevent the program crawler from crawling the website into a website paralysis, it will need to carry some header header information to
access.
Requests library for network data collection
The
official URL of the requests library requests: https://requests.readthedocs.io/en/master/
Requests is an elegant and simple HTTP library for Python, built for human
beings.The
request method summarizes the 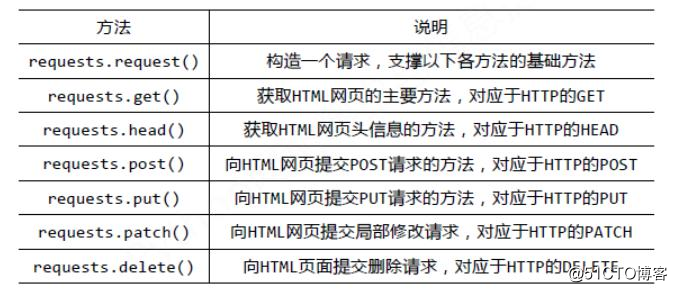
Response object contains all the information returned by the server, and also contains Request information. 
reqursts.py
from urllib.error import HTTPError
import requests
def get():
# get方法可以获取页面数据,也可以提交非敏感数据
#url = 'http://127.0.0.1:5000/'
#url = 'http://127.0.0.1:5000/?username=fentiao&page=1&per_page=5'
url = 'http://127.0.0.1:5000/'
try:
params = {
'username': 'fentiao',
'page': 1,
'per_page': 5
}
response = requests.get(url, params=params)
print(response.text, response.url)
#print(response)
#print(response.status_code)
#print(response.text)
#print(response.content)
#print(response.encoding)
except HTTPError as e:
print("爬虫爬取%s失败: %s" % (url, e.reason))
def post():
url = 'http://127.0.0.1:5000/post'
try:
data = {
'username': 'admin',
'password': 'westos12'
}
response = requests.post(url, data=data)
print(response.text)
except HTTPError as e:
print("爬虫爬取%s失败: %s" % (url, e.reason))
if __name__ == '__main__':
get()
#post()Advanced application one: add headers
Some websites must be accompanied by browser and other information. If headers are not passed in, errors will be reported.
headers = {'User-Agent': useragent}
response = requests.get (url, headers = headers)
UserAgent is a string of characters that recognizes the browser ,
Frequent replacement of UserAgent can avoid triggering the corresponding anti-climbing mechanism. Fake-useragent provides
good support for frequent replacement of UserAgent , which can be described as an anti-reverse tool.
user_agent = UserAgent (). random
import requests
from fake_useragent import UserAgent
def add_headers():
# headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0'}
#UserAgent实质上是从网络获取所有的用户代理, 再通过random随机选取一个用户代理。
#https://fake-useragent.herokuapp.com/browsers/0.1.11
ua = UserAgent()
#默认情况下, python爬虫的用户代理是python-requests/2.22.0。
response = requests.get('http://127.0.0.1:5000', headers={'User-Agent': ua.random})
print(response)
if __name__ == '__main__':
add_headers()Advanced application 2: IP proxy settings
When performing crawling reptile, reptiles are sometimes masked to the server, the method used at this time is decreased to access main
room, accessed through a proxy IP. IP can be grabbed from the Internet, or purchased by a treasure.
proxies = {"http": " http://127.0.0.1:9743 ", "https": " https://127.0.0.1:9743 ",}
response = requests.get (url, proxies = proxies)
Baidu's Keywords interface:
https://www.baidu.com/baidu?wd=xxx&tn=monline_4_dg
360Keyword interface: http://www.so.com/s?q=keyword
import requests
from fake_useragent import UserAgent
ua = UserAgent()
proxies = {
'http': 'http://222.95.144.65:3000',
'https': 'https://182.92.220.212:8080'
}
response = requests.get('http://47.92.255.98:8000',
headers={'User-Agent': ua.random},
proxies=proxies
)
print(response)
#这是因为服务器端会返回数据: get提交的数据和请求的客户端IP
#如何判断是否成功? 返回的客户端IP刚好是代理IP, 代表成功。
print(response.text)