The personal blog address https://nfreak-man.cn
has just been in contact with the Python crawler recently. It is just recently that pneumonia has spread throughout the country, so I plan to crawl real-time pneumonia data from the website and parse the data I want. The URL for obtaining json data is https://m.look.360.cn/events/feiyan
Crawl URL:
def main():
url='https://m.look.360.cn/events/feiyan'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 QIHU 360EE'}
parse_page(url)
Parse and save the json format file:
state = json.loads(response.content)
with open("feiyan.json", "w",encoding='utf-8') as f:
f.write(json.dumps(state,indent=2,ensure_ascii=False))
print("保存成功")
After obtaining the json file, it is found in a nested format. For the specific format, you can open the URL above to view:
{
"data":[
{
"data":{省份}
"citys":[
{城市}{}.....
]
}
{
"data":{省份}
"citys":[
{城市}{}.....
]
}
"country":[
{其他国家}
]
]
}

Analytical data
Because I only want to get the names of the cities, the number of infections, the number of cures and the number of deaths, I need a nested loop to get and output each one. code show as below:
Provincial data acquisition:
provincename = state['data'][i]['data']['provinceName']
confirmedCount = state['data'][i]['data']['confirmedCount']
curedCount = state['data'][i]['data']['curedCount']
deadCount = state['data'][i]['data']['deadCount']
City data acquisition:
cityName = state['data'][i]['cities'][j]['cityName']
diagnosed = state['data'][i]['cities'][j]['diagnosed']
cured = state['data'][i]['cities'][j]['cured']
died = state['data'][i]['cities'][j]['died']
Data acquisition in foreign cities:
countryname = state['country'][c]['provinceName']
diagnosed = state['country'][c]['diagnosed']
cured = state['country'][c]['cured']
died = state['country'][c]['died']
The above is the nested json parsing format.
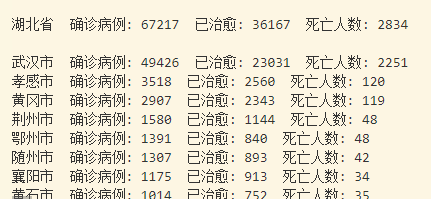
Output effect:
Source address: github
