Big data offline analysis scenarios
Refers generally to mass data into the analysis and processing, the resultant data is formed, the next step for data applications. Offline processing of the processing is not time critical, but the large amount of data processing, computing occupy more storage resources, usually through the MR or Spark job or jobs SQL implementation. Offline analysis system architecture for the software to HDFS distributed storage data base engine is calculated based on the MapReduce Hive and based on the Spark SparkSQL.

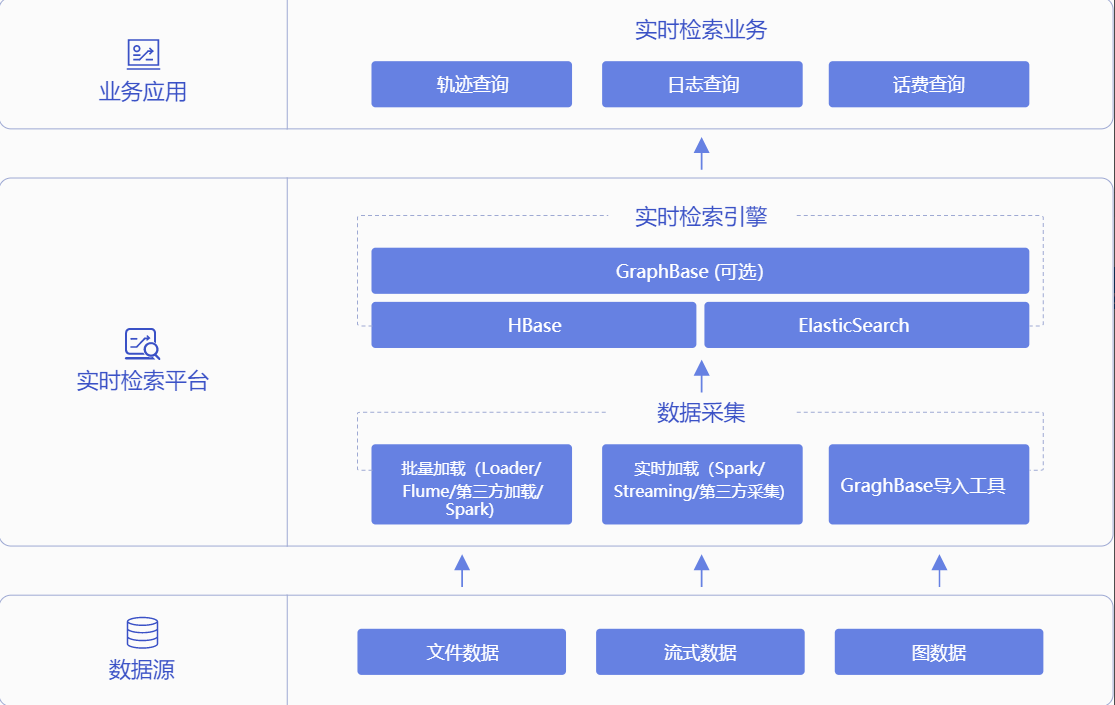
Large real-time data retrieval scene
It provides elastic expansion, low latency, high throughput, high-performance computing resources to support real-time analysis of the industry's mainstream business platform, combined with high-bandwidth, multi-protocol object storage services to enhance real-time analysis of business overall resource utilization.
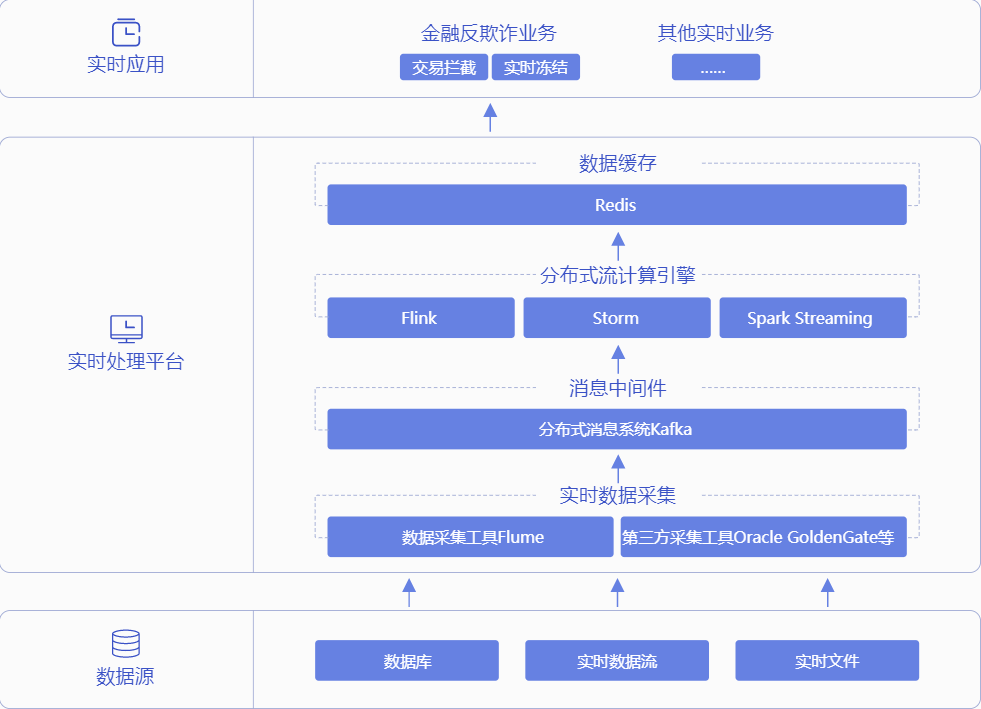
Real-time data stream processing large scene
Often refers to real-time data sources for rapid analysis, scene quickly trigger the next action. Real-time data analysis and processing speed for demanding, data processing huge scale, high CPU and memory requirements, but usually data does not fall, do not ask for storage. Real-time processing, usually by Storm, Spark Streaming or Flink task to achieve. Distributed message sent through the data acquisition system to a real-time distributed stream Kafka computing engine Flink, Storm, Spark Streaming data processing, the result is stored for the upper Redis provide caching services.
@ Huawei Kunpeng taken from [cloud]