Disclaimer:
this blog readers learning purposes only reptiles knowledge, nothing to do with any illegal means for myself, welcome to learn, I have the final interpretation of the code, if readers need to use one of the codes, please indicate in the comment author: Yang Wenhao from this page Tks! ! .
This article deals pit I had met all the records
attached to the end the complete code
Article Directory
The first step in analyzing Login required
Parametric analysis
① First, check the login data of the local post
② by FD packet capture we got it to the http://zhjw.scu.edu.cn/j_spring_security_checkdata in this post URL, as shown below, and then we look at the parameters inside, j_usernameplain text, j_passwordit is encrypted content, in response to guess which files should be made on the page we need to answer
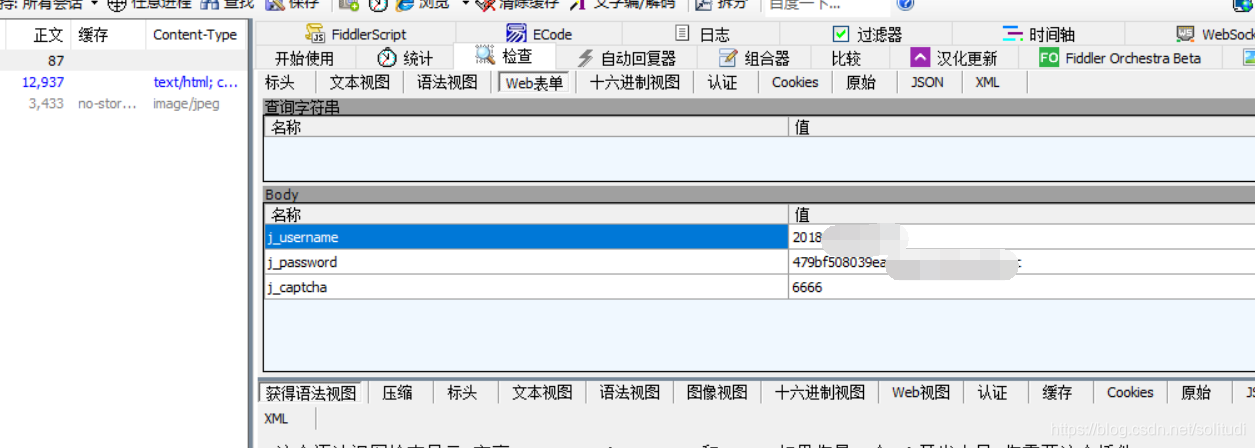
the following figure, we find that our password simply perform the md5 encryption, it is very simple, so the next task was to get the verification code

③ questions about verification code, in fact, there are two ways , first with selenium to simulate browser behavior, but this is too slow, not what we want, we want to get the answer you want by requests module
The second step verification codes
First we have to get the address verification code request to review the elements available /img/captcha.jpg

then we start writing code first, of course, to say the premise here when requesting a verification code must bring cookie, on behalf of this account is your sole criterion, or to when the request to the cookie useless, the pit was encountered! ! !
That being the case better to use the session to maintain session state
r = session.get('http://202.115.47.141/img/captcha.jpg', headers=headers_for_captcha)
with open('captcha.jpg','wb+') as f:
f.write(r.content)
Then we went to open the CAPTCHA image, found each run is not the same, okk, but if it is so that you can post it would be wrong, here is a pit , that you get verification codes is very unique , F12 take you to see the truth
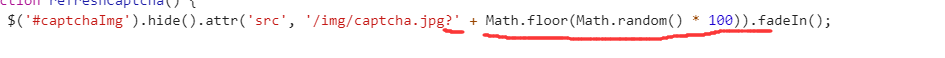
that did not, get back with requests also staged a random number, so now we just beat it
soup = BeautifulSoup(r.text, 'lxml')
captcha_url = soup.find("img", id="captchaImg")['src']
# 链接来自url中算法
url_captcha = 'http://202.115.47.141' + captcha_url + '?' + str(random.randint(1, 100))
The third step: Log
So no problem hee hee, next only you need a combination of parameters, of course, manually open each time code is particularly troublesome, we are using PILit
data = {
'j_username': username,
'j_password': password,
'j_captcha': captcha
}
r = session.post(url_login, headers=headers_for_captcha, data=data)
return r.request.headers['Cookie']
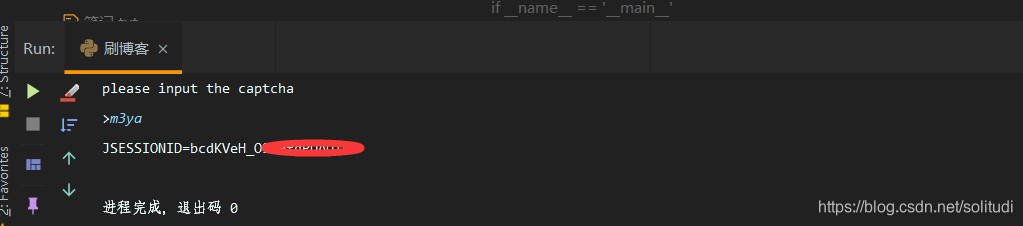
Such a program is running again, the success of the right, then came to an end!
Appendix: The complete code
import requests
import hashlib
import random
from PIL import Image
from bs4 import BeautifulSoup
def captcha_get():
username = '学号'
password = hashlib.md5(b'密码').hexdigest()
url = 'http://202.115.47.141'
url_login = 'http://zhjw.scu.edu.cn/j_spring_security_check'
session = requests.session()
headers_for_captcha = {
'Host': '202.115.47.141',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3754.400 QQBrowser/10.5.4034.400',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Referer': 'http://202.115.47.141/login?errorCode=badCaptcha',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
r = session.get(url, headers=headers_for_captcha)
soup = BeautifulSoup(r.text, 'lxml')
captcha_url = soup.find("img", id="captchaImg")['src']
# 链接来自url中算法
url_captcha = 'http://202.115.47.141' + captcha_url + '?' + str(random.randint(1, 100))
r = session.get(url_captcha, headers=headers_for_captcha)
print(r.url)
with open('captcha.jpg', 'wb+') as f:
f.write(r.content)
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
print(u'请到 根目录找到captcha.jpg 手动输入')
captcha = input("please input the captcha\n>")
data = {
'j_username': username,
'j_password': password,
'j_captcha': captcha
}
r = session.post(url_login, headers=headers_for_captcha, data=data)
return r.request.headers['Cookie']
if __name__ == '__main__':
print(captcha_get())
