Classic depth classification network

AlexNet
- Wherein
for the mountains, using ReLU, LRN, Dropout, Overlapping pooling (stride <kernel) - Chart

VGG
- feature
- cov3x3 pad = stride = 1 does not alter the character size in FIG.
- + = conv5x5 conv3x3 con3x3
con3x3 conv3x3 + + = conv7x7 conv3x3
reduce computation - Made deeper (level ++)> wider (channels ++)
- Chart

vgg16(D) vgg19(E)

Inception v1
- feature:
- Multiscale feature also calculated (a)
- 1x1 conv reduce the number of channel (b)
- middle level classification insert a separate layer (deep supervision?)
- Inception module architecture

- GoogleNet architecture


serious
-
Wherein:
the residual alignment network channels: 1x1 conv residual Learning -
bottleneck architecture (channel narrowing -> expansion)

- Example alignment expansion (by 1x1 conv)

- resnet network parameters

References:
Resnet
Inception v2
- feature:
- Reduce the amount of parameters:
- 5x5 = 3x3 + 3x3 7x7 = 3x3 + 3x3 + 3x3
- 3x3 = 3x1 + 1x3
- Reducing feature map while expanding Channel:
CONV parallel Pooling +
- Alchemy Dafa is good:
- A large proportion of compression (pooling) with caution, resulting in rapid reduction feature map
- channel ++ favor convergence
- 1x1 conv compression channel low-loss compression
- The depth and number of channel width and depth geometric balance
- Network Architecture:


Inception v3
- 特征:middle level classifier +BN/Dropout 层 for regularization
- Architecture:

Inception v4
More elaborate complex structures, in order to verify resnet only accelerated training proposed

Inception-Resnet v1&v2
- Wherein:
the name suggests, Inception + residual module
to module output Inception-resnet scaling const 0.1-0.3

DenseNet
- Wherein: the input feature map for the block in front of all layers of
the Dense Layer
B. N-> Relu-> Bottleneck (Channel-> * K. 4) -> CONV (Channel-> K) -> Dropout
Transition Layer + BN + RELU 1x1conv (available channel -) + pooling (feature map -)
Why bottleneck? Dense block, if each layer function K are generated feature map, then the first layer there l characteristic map as an input, where k0 represents the number of channels in the input layer. Number of input channels too much mess
- Architecture:


densenet that the specific reasons for slow resnet, densenet of featuremap much larger than resnet, resulting in many large computing convolution process than resnet, in a nutshell is flops bigger, bigger memory usage, and memory visits to a lot more memory access is very slow
ResNeXt
- Wherein: in the form of increasing the branch group
- Architecture:
proposed aggregrated transformations, the same blocks in a stacked parallel block topology instead of the original three convolution ResNet enhance the accuracy of the model parameters in the case of significantly increasing order, and because the same topology , hyperparameters also reduced, facilitating transplant model.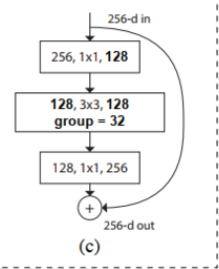

Resnet V2
- Wherein: the bn-relu before moving to ensure Identity mapping conv
- Architecture:

Why should ensure the distribution of identity branches?

