I. Background
Thread-safe HashMap
Because multiple environments, for use HashMap put operation may cause cycle, resulting in close to 100% CPU utilization, can not be used in the HashMap concurrency.
Inefficient container HashTable
HashTable container using synchronized to ensure thread safety, but in the highly-threaded competition HashTable efficiency very, very bottom, because when synchronization method one thread to access the HashTable, you may enter the blocked state, such as thread 1 using put add elements, thread 2 will not be able to add elements put to use, and can not use the get method to get the elements, so the more competition, the more inefficient.
Lock Segmentation
HashTable container manifested in a highly competitive environment complicated by underlying cause of efficiency, because all access HashTable threads must compete for the same lock, if it locks the container how each part of the data for the container, then when multiple threads access the container, there is no inter-thread lock competition. Which can effectively improve the access efficiency, which is ConCurrentHashMap lock segmentation techniques, the first data segments by storing, for each piece of data and with a lock, when a thread holding the lock wherein the data access, the other data segments can also be accessed by other threads, some methods need cross-section, such as size () and ContainsValue (), they may lock the entire table, rather than just a segment lock, lock all segments need to order, after the operation is completed, and the order release locks on all segments. Here is very important in order, or is likely to deadlock inside ConcurrentHashMap, is the final segment of the data set, and is actually the final member variable, however, is only the final statement of the array does not guarantee data members is final, which is to ensure that the need to achieve, which ensures that no deadlock, because the order to get the lock fixed.
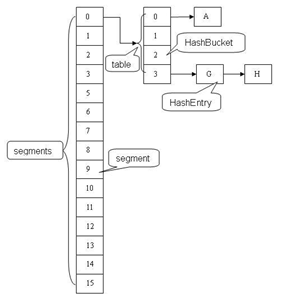
ConcurrentHashMap segment data structure is an array of structures and HashEntry, a reentrant segment lock ReetrantLock, ConcurrentHashMap role in the lock, the HashEntry for storing key data, a ConcurrentHashMap array which contains a Segment, the Segment HashMap structure and the like, a list structure and the array, which contains a Segment a HashEntry array, each element of a list is HashEntry structure. Each Segment HashEntry a guardian element array, when the data array is modified HashEntry, must first obtain its corresponding locking segment.
Second, the application scenarios
When there is a large array as needed when multiple threads share can consider whether to put it into multiple nodes, avoid big lock. Consider some of the modules and can be positioned by the Hash algorithm. In fact, more than a thread, when the transaction design data table (also reflect a sense Affairs synchronization mechanism), the instrument can be viewed as an array of synchronization required, if the table data manipulation is too much to consider matters separated ( this is why you want to avoid a large table), such as data field split level sub-lists.
Third, source code interpretation
ConcurrentHashMap three main classes are implemented, ConcurrentHashMap (entire Hash table), segment (barrels), HashEntry (node), corresponding to the above relationship can be seen between the
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
Constant (the Immutable) and variable (Volatile) `
of ConcurrentHashMap fully allow multiple operating concurrently, the read operation does not require a lock, if using conventional techniques, as implemented in the HashMap, if possible Hash permitted to add or remove the chain element, a read operation does not lock the resulting inconsistent data. ConcurrentHashMap implementation technology is a guarantee on behalf of each node HashEntry Hash chain, which structure is shown below:
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
In addition you can see, not the final value of the other values are final. This means that from the middle or the tail can not add or delete nodes hash chain, because it needs to be modified next reference value, all of the nodes can only be modified from the head, to put all the operation can add value hash head the list, but for remove operation, you may need to remove a node from the middle, which is necessary to delete the entire replication node side, the last node points to the next node to be deleted. This will be described in detail when talking about the deletion, in order to ensure that the read operation can see the latest value, the value is set to volatile, which avoids the lock.
Other
order to accelerate the speed and positioning of the segment hash groove segments, the length of each slot is a hash 2^n, which makes the position by the position calculating section and positioning section can hash slot. When the default value of 16 concurrency level, which is high 4 determines the number of segments, hash value allocated to the segment that, but we should not forget: the number of hash slots should not be 2 ^ n, which may lead to hash uneven distribution groove, which need to re-hash value in a hash.
Positioning operation:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
Since ConcurrentHashMap use to protect data segment segment segment is different, then the insertion time and get the elements, you must first locate through a hashing algorithm to segment, you can see ConcurrentHashMap will first hash algorithm using a variety of elements once again hashCode hashes.
Re-hash, its purpose is to reduce the hash collision, the element is uniformly distributed over different segment, thereby improving the access efficiency of the container, if the hash extreme poor quality level. So all the elements are the same in a segment, not only slow access elements, the staging area when it meaning. I did a test, not directly by re-hashed hash.
System.out.println (the Integer.parseInt ( "0001111", 2) & 15);
System.out.println (the Integer.parseInt ( "0011111", 2) & 15);
System.out.println (the Integer.parseInt ( "0111111", 2) & 15);
System.out.println (the Integer.parseInt ( "1111111", 2) & 15);
hash value calculated output 15 is full, by this example can be found if no longer hash, hash collision will be very serious, because as long as low as, no matter what the number is high, it is always the same hash value. We then performed the above binary data after re-hash result as follows, for ease of reading, the upper 32 bits make up less than 0, the vertical bar is divided every four.
0100|0111|0110|0111|1101|1010|0100|1110
1111|0111|0100|0011|0000|0001|1011|1000
0111|0111|0110|1001|0100|0110|0011|1110
1000|0011|0000|0000|1100|1000|0001|1010
You can find every bit of data are hashed opened, and every one in this re-hash can participate to make digital hashing them, thereby reducing the hash collision. ConcurrentHashMap by hashing positioning segment.
SegmentShift default is 28, segmentMask 15, then the maximum number of hash binary data is 32-bit, no symbols are moved to the right 28, upper 4 bits does mean that participate hash calculation, (hash >>> segmentShift ) & calculation result segmentMask 4,15,7 and 8 respectively, can be seen that the hash value does not conflict.
Data Structure
All members are final, where segmentMask and segmentshfit mainly for positioning section, see above segmentFor method, on the basis of the structure of Hash table, but the degree to explore here, hash table is an important aspect is how to resolve the conflict hash , and HashMap of ConcurrentHashMap the same way, that is, the same hash value of the node in a hash chain. And hashMap except that, using a plurality of ConcurrentHashMap sub hash table, i.e. segment (segment).
Each sub-segment is quite a hash table, its data members are as follows:
/**
* Stripped-down version of helper class used in previous version,
* declared for the sake of serialization compatibility
*/
static class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
//loadFactor表示负载因子。
final float loadFactor;
Segment(float lf) { this.loadFactor = lf; }
}
Delete remove (key)
/**
* {@inheritDoc}
*
* @throws NullPointerException if the specified key is null
*/
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
The entire operation is to locate the segment, and then remove entrusted to the operation section. When a plurality of delete operations concurrently, as long as they are located segments are not the same, they may be performed simultaneously.
Here is the Segment remove method to achieve:
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
The entire operation is performed in the case of holdings segment locks, blank lines before the line is mainly targeted to be deleted node e. Next, the node if there is no direct return null, otherwise it is necessary to copy it again in front of the node e, the end point to the next node in node e. e node behind replication is not needed, they can be reused.
The middle of the for loop is what to do with it? (Marked with *) from the code, is that after all the entry positional cloning and back to the front to fight, but necessary? Every element is necessary to remove an element before that clone again? This is actually the entry of invariance to the decision, careful observation entry definitions found in addition to value, all other attributes are used to modify the final, which means that it can no longer be changed after the first set next domain and replaced it all before cloning a node. As for why the entry is set to invariance, which does not require synchronization with the invariance of access thus saving time about the
Here is a schematic diagram of

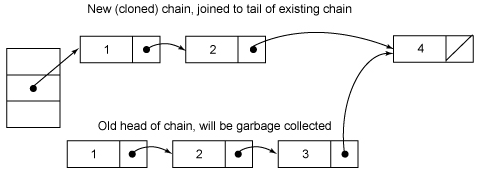
the second figure is actually a problem, node replication should be the value of the node 2 in front, value node 1 is in the back, which is exactly the reverse order of the original node, but fortunately, this does not affect our discussion.
Remove the entire implementation is not complicated, but requires attention to the following points. First, when there is a node to be deleted, the value To delete the last step count minus one. This must be the last step of the operation, or the read operation may not see the structural modifications made before segment. Second, remove begins execution will assign a local variable table Tab, because the variable table is volatile, read-write volatile variables large overhead. The compiler can not do any reading and writing volatile variables optimization, direct access to non-volatile multiple instance variables had little effect, the compiler will optimize accordingly.
get operation
ConcurrentHashMap the get operation is a direct method to get delegate segment, the segment of looking directly at the get method:
V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
/**
*
/
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
If it finds a node desires, it is determined if the value of its non-empty return directly, or to read it again in a locked state. It may seem hard to understand, the theoretical value of the node can not be empty, since when he has been put to determine if we should throw NullPointerException is empty. The only source is the default value of null values in HashEntry, because HashEntry the value is not final, non-synchronous read is possible to read to a null value. Look carefully put operation statement: tab [index] = new HashEntry <K, V> (key, hash, first, value), in this statement, HashEntry constructor and the value assignment of the tab [index] the assignment may be re-ordered, which may cause the node is empty. Here, when v is empty, it may be a thread is changing node, whereas the previous operation get none of the lock, according to bernstein condition, after reading write or read-write will cause inconsistent data, so be here again on this e lock read it again, which guarantees the correct value.
put operation
same normal operation is entrusted put methods that segment, the following method is put:
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
Since the method was needed to put the shared variable write operation, so in order to thread safety, must be locked in operation shared variable, put positioning segment method first, and then operate in the segment. Inserts need to go through two steps, first determines whether or not the need for HashEntry segment in the array expansion, the second step is then positioned into the position of the element added to the array HashEntry.
The method of operation containKey
//判断是否包含key
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
return true;
e = e.next;
}
}
returnfalse;
}
size () operation
if we are to be counted in the size of the entire ConcurrentHashMap elements, it is necessary to count all segment in the size of the element summation, segment in the global variable count is a volatile variable, in multithreaded scenarios, we are not directly the sum of all segment of the count you can get the whole ConcurrentHashMap size? No, although adding that access to the latest count value of the segment, but the count value before use changes that may accumulate after get, then the result is a statistical allowed. So security approach is in the statistics when the size of the segment of the put, remove, clean method all locked, but the efficiency of this approach is particularly low.
Because the probability of a change in the count accumulated count operation process, prior to accumulation had a very small, so ConcurrentHashMap approach is to first attempt to count twice by not locking Segment Segment size each way, if the statistical process, the container count changes, then locked again using the statistical approach to the size of all Segment.
So ConcurrentHashMap is how to determine whether the vessel has changed in the statistics when it? Use modCount variable, the variable modCount front element will be added to 1, then compare modCount whether changes in size before and after statistics put, remove and clean method in operation, so that the size of the vessel has changed.
