
Willkommen beim Updatebericht zu den Produktfunktionen von Kangaroo Cloud 09. In diesem Bericht halten wir an dem Konzept fest, dass Innovation und Optimierung gleichermaßen im Vordergrund stehen, und führen eine gründliche Optimierung und umfassende Verbesserung des Produkts durch. Die Verbesserung jedes Details ist unser unermüdliches Streben nach hervorragender Qualität. Wir hoffen, dass diese neuen Funktionen Ihren Geschäftsbetrieb und Ihre Entwicklung unterstützen und den Weg zur digitalen Transformation reibungsloser gestalten können.
Im Folgenden finden Sie den Inhalt des Kangaroo Cloud Product Function Update Report, Ausgabe 09. Für weitere Informationen lesen Sie bitte weiter.
Offline-Entwicklungsplattform
Neue Funktionsupdates
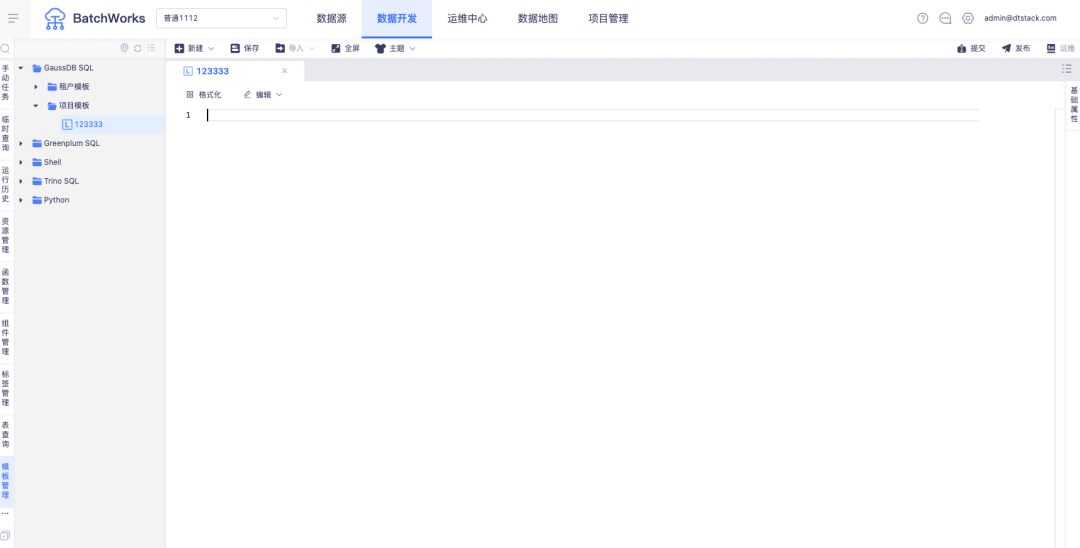
1.Aufgabenvorlage
Hintergrund: Kunden möchten täglich gängige Codevorlagen offline verwalten und während der Datenentwicklung direkt darauf verweisen.
Der Unterschied zwischen Vorlagen und Komponenten:
1. Die Bearbeitung wird unterstützt, nachdem auf den Vorlagencode verwiesen wurde, die Bearbeitung wird jedoch nicht unterstützt, nachdem auf die Komponente verwiesen wurde.
2. Vorlagenänderungen wirken sich nicht auf die referenzierten Aufgaben aus, Komponentenänderungen wirken sich jedoch auf die referenzierten Aufgaben aus.
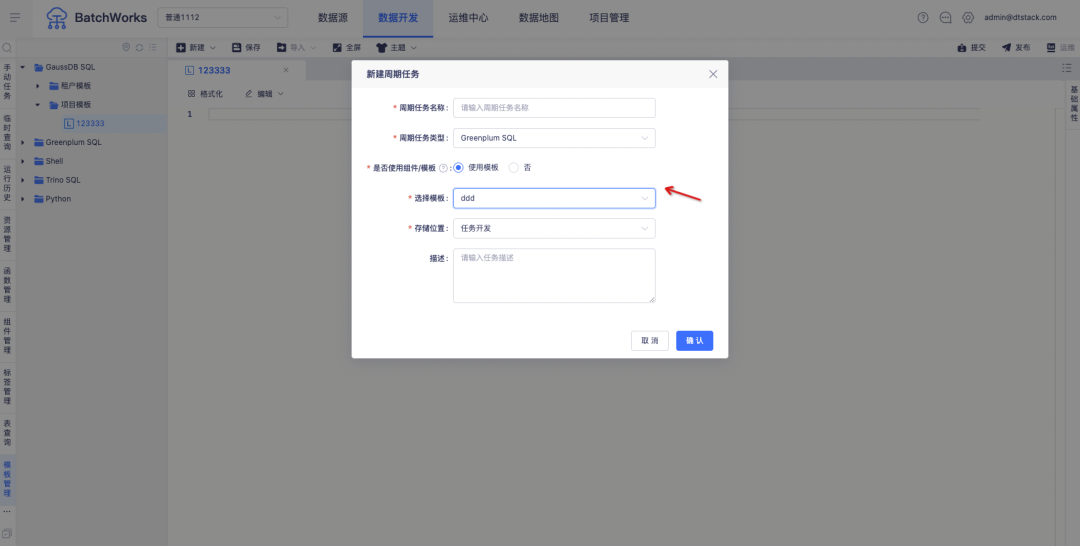
Beschreibung der neuen Funktion: Unterstützt Projektcodevorlagen und Mandantencodevorlagen für jeden Aufgabentyp und unterstützt das Referenzieren von Codevorlagen beim Erstellen von Aufgaben .
2.Shell auf Agent/Python auf Agent fügt neue Projektdimensionssteuerung hinzu
Hintergrund:
Shell on Agent ist ein spezieller Aufgabentyp für Offline-Plattformen.
Die Shell-Aufgabe wird nicht direkt auf der im Cluster bereitgestellten Maschine ausgeführt, sondern die Shell wird auf einem unabhängig bereitgestellten Serverknoten ausgeführt. Da für eine Offline-Aufgabe zwei Kerne erforderlich sind, ist es bei vielen Shell-Aufgaben im Kundenszenario einfach, die Clusterressourcen zu füllen . Daher kann die Ausführung von Aufgaben wie Shell und Python auf unabhängig bereitgestellten Knoten den Druck auf den Cluster effektiv verringern.
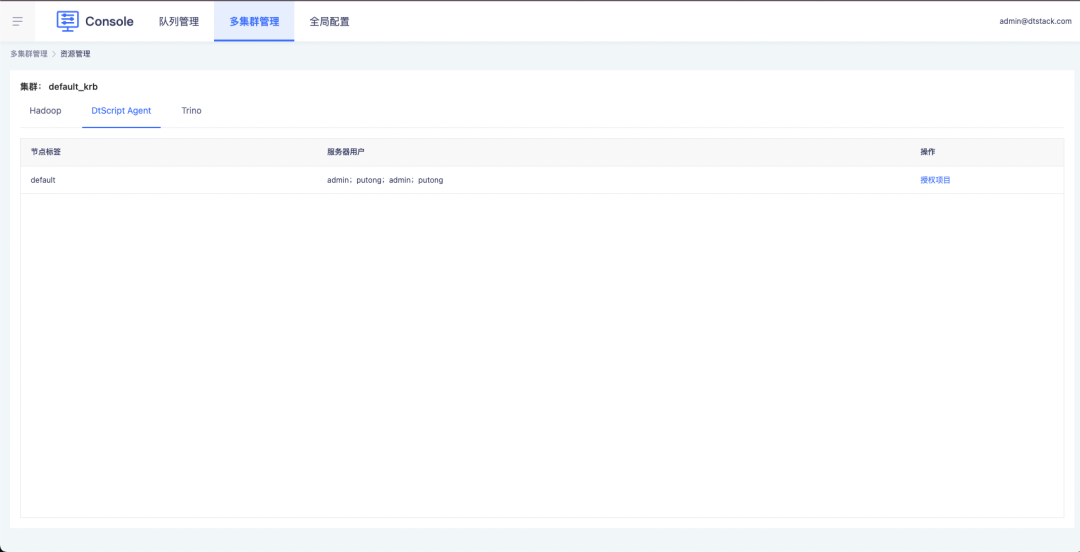
Derzeit besteht ein Problem, solange der Kunde den Knoten- und Serverbenutzer auf EM und der Konsole konfiguriert. Alle Projekte unter dem Cluster können den konfigurierten Knoten- und Serverbenutzer verwenden. Beispielsweise legen Kunden bei Benutzern mit hohen Berechtigungen wie Root mehr Wert auf Sicherheitsprobleme und möchten nicht, dass alle Projekte dieses Konto verwenden können. Daher ist es notwendig, eine Lösung zu entwerfen, die die Konfiguration von Serverknoten steuern kann und Serverbenutzer, um dieses Problem zu lösen.
Beschreibung der neuen Funktionen:
1. Die Konsole steuert die Benutzerberechtigungen für Knoten und Server über die Projektautorisierung.
2. Aufgaben in Offline-Projekten unterstützen die Auswahl autorisierter Serverknoten und Benutzer.
Funktionsoptimierung
1. Planung der Konfigurationsoptimierung, die jede periodische Instanz steuern kann, die auf vorgelagerten Aufgaben basiert
Hintergrund:
Derzeit kann die Planung von Zhongtian-Aufgaben standardmäßig nur auf der Upstream-Instanz des aktuellen Zyklus basieren. Kunden können die folgenden Szenarien haben:
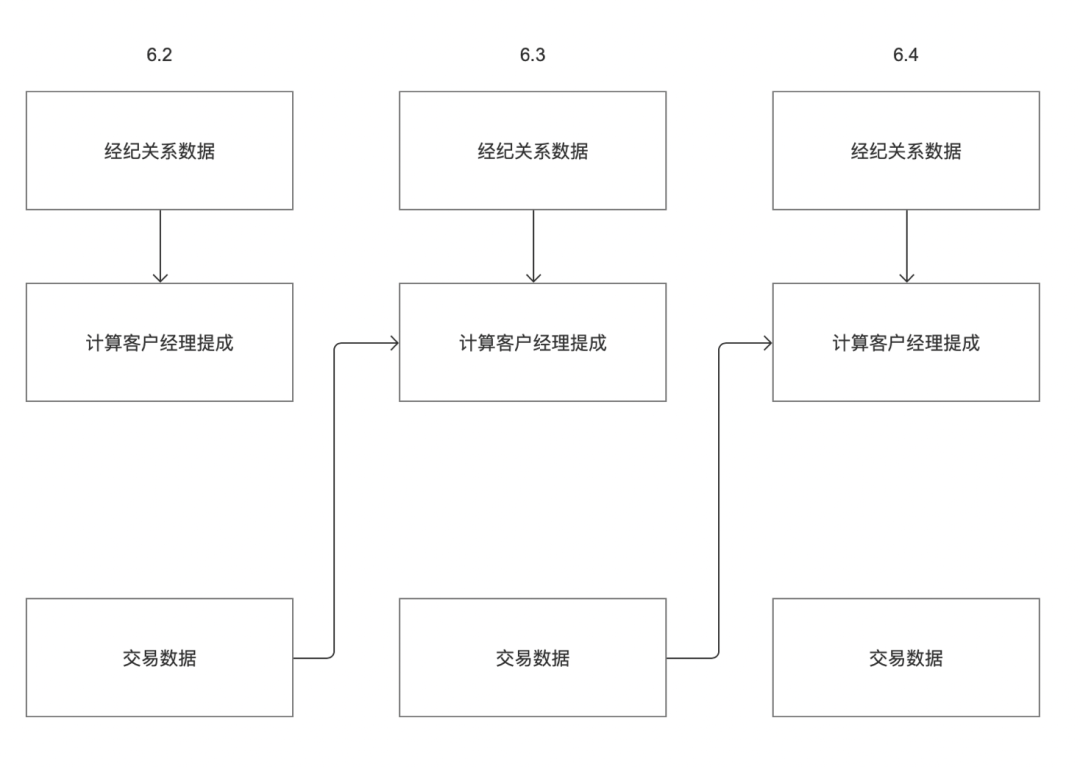
Beispielsweise verfügt ein Kunde über zwei Geschäftssysteme „Vermittlungsbeziehungsdaten“ und „Transaktionsdaten“. Die Provision des Kunden am 3. Juni muss auf der Grundlage der „Vermittlungsbeziehungsdaten“ bzw. „Transaktionsdaten“ berechnet werden. Wie in der Abbildung oben gezeigt, ist die Ausgabezeit der Geschäftssystemdaten „Vermittlungsbeziehungsdaten“ am 2. Juni der 3. Juni, die Ausgabezeit der Geschäftssystemdaten „Transaktionsdaten“ am 2. Juni der Abend des 2. Juni.
Gemäß der aktuellen Offline-Upstream- und Downstream-Abhängigkeitslogik kann die Aufgabe „Account Manager-Provision berechnen“ nur Aufgaben am 3. Juni erhalten, jedoch keine Aufgaben am 2. Juni. Daher muss sie geändert werden, um die Abhängigkeitseinstellungen für Aufgabeninstanzen zu unterstützen kann individuell angepasst werden.
Anleitung zur Erlebnisoptimierung:
Unterstützt die Anpassung des Planungszyklus abhängiger Upstream-Aufgaben .
T stellt die geplante Zeit der aktuellen Aufgabe (nachgelagerte Aufgabe) dar, „+ -“ stellt die Versatzrichtung dar, „+“ stellt den Zeitversatz in die Zukunft dar, „-“ stellt den Zeitversatz in die Vergangenheit dar und „-“ ist standardmäßig ausgewählt.
Der Offset ist ein numerisches Eingabefeld mit einem Maximalwert von 10 und einem Minimalwert von 1, was die Anzahl der Upstream-Task-Zyklen des Offsets darstellt.
Echtzeit-Entwicklungsplattform
Neue Funktionsupdates
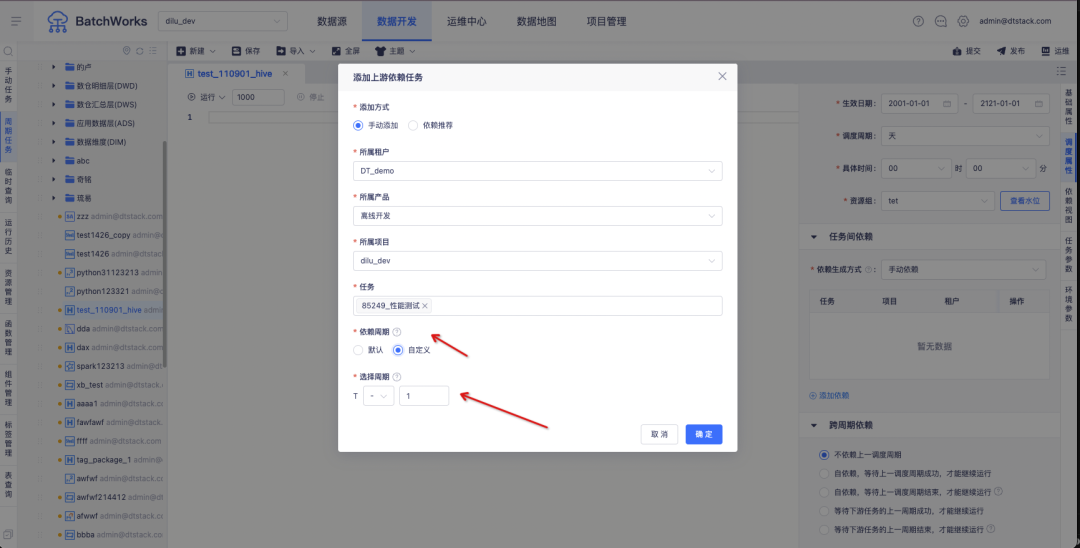
1. Blutlinienanalyse ansehen
Hintergrund: Derzeit unterstützt SQLParser die Ansichtsherkunftsanalyse von FlinkSQL nicht. Wenn die Aufgabe jedoch mehr als drei Tabellen umfasst, entscheiden sich viele Besprechungen dafür, Ansichten in der IDE zu erstellen, um das Lesen der SQL-Logik zu erleichtern.
Funktion:
1. SQLParser unterstützt die FlinkSQL-Ansichtstabelle zur Anzeige der Blutsverwandtschaftsanalyse
2. Aufgabenbetrieb und -wartung – Echtzeitaufgaben – FlinkSQL-Aufgabendetails – Anzeigefunktion für die Blutlinienanalyse
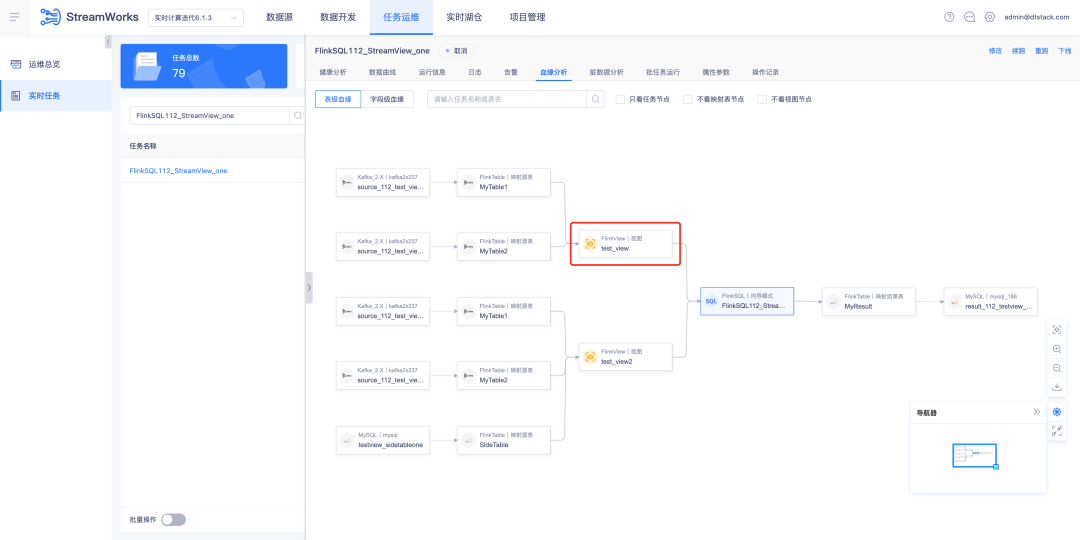
2.FlinkSQL unterstützt Oceanbase Sink
FlinkSQL Version 1.16 unterstützt OceanBase-Ergebnistabellen und ist mit den MySQL- und Oracle-Modi von OceanBase Version 4.2.0 kompatibel und bietet Benutzern flexiblere und effizientere Datenverarbeitungsfunktionen.
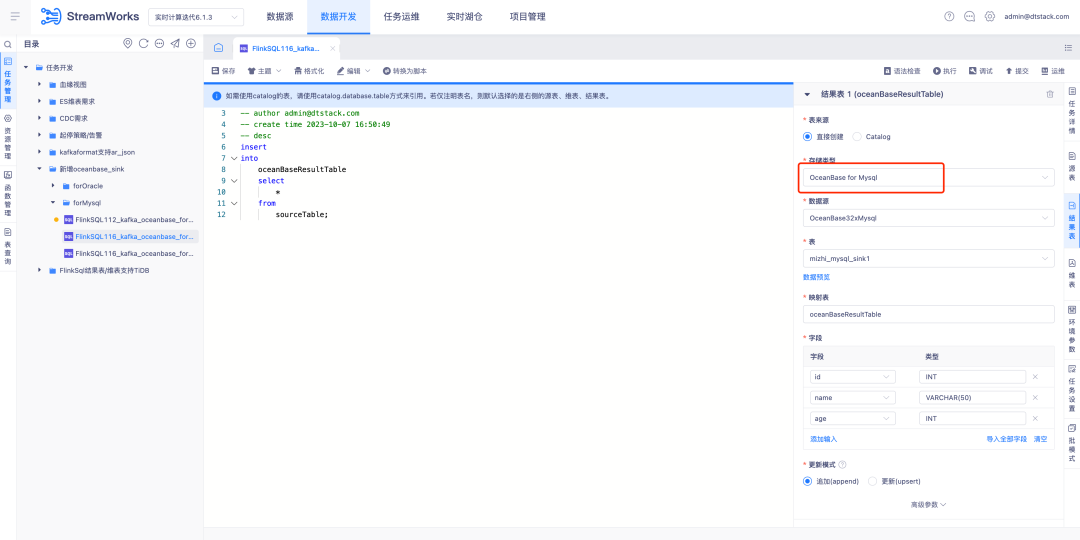
3. Der Kafka-Lesetyp der Quelltabelle unterstützt AR Json
Hintergrund: OGG und Attunity Replicate sind zwei im Ausland weit verbreitete kommerzielle Produkte . Um den Kundenanforderungen besser gerecht zu werden, müssen wir sicherstellen, dass das JSON-Format von Kafka mit dem AR-Json-Lesetyp kompatibel ist.
Beschreibung der neuen Funktion: Der Kafka-Lesetyp der Quelltabelle der FlinkSQL1.16-Version unterstützt den AR-Json-Typ und unterstützt automatische Zuordnungsfunktionen zum Parsen von Json.
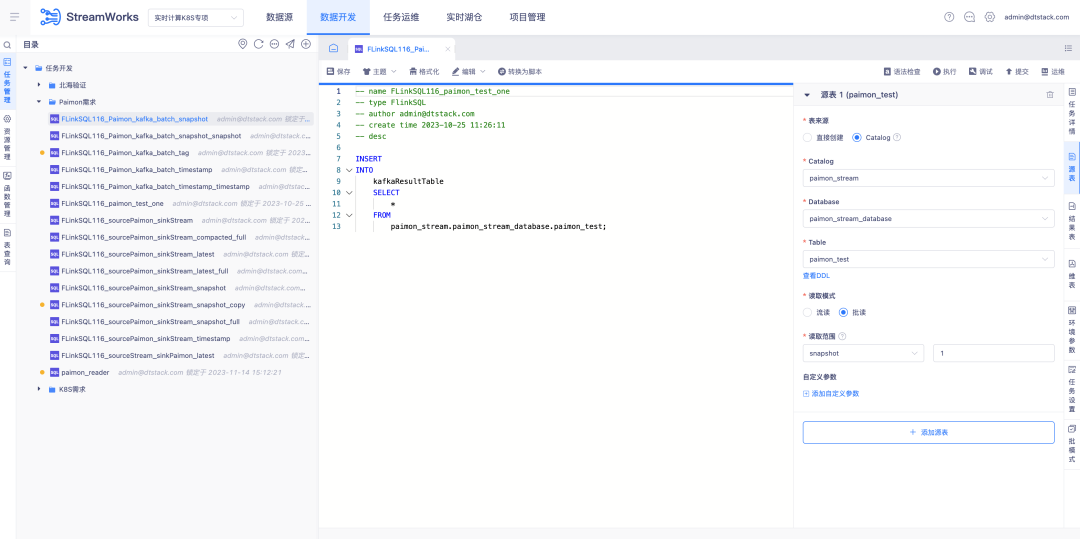
4. Echtzeit-Lake-Lager-Paimon-Unterstützung
Hintergrund: Mit der Entwicklung von Paimon muss dieses Mal ein neues FlinkSQL-Entwicklungsmodell iteriert werden. Mit diesem Modell kann das Lake-Warehouse-Management-Modul über die gesamte Kette aneinandergereiht werden.
Beschreibung der neuen Funktionen:
1. Lake Warehouse Management bietet die Möglichkeit, Paimon-Tabellen hinzuzufügen, zu löschen, zu ändern und abzufragen
2. Fügen Sie die visuelle Konfigurationsfunktion der Paimon-Tabelle zur Datenentwicklungsplattform hinzu.
3. Die Datenentwicklungsplattform verwendet die IDE, um die Lese- und Schreibfunktionen der Paimon-Tabelle abzuschließen.
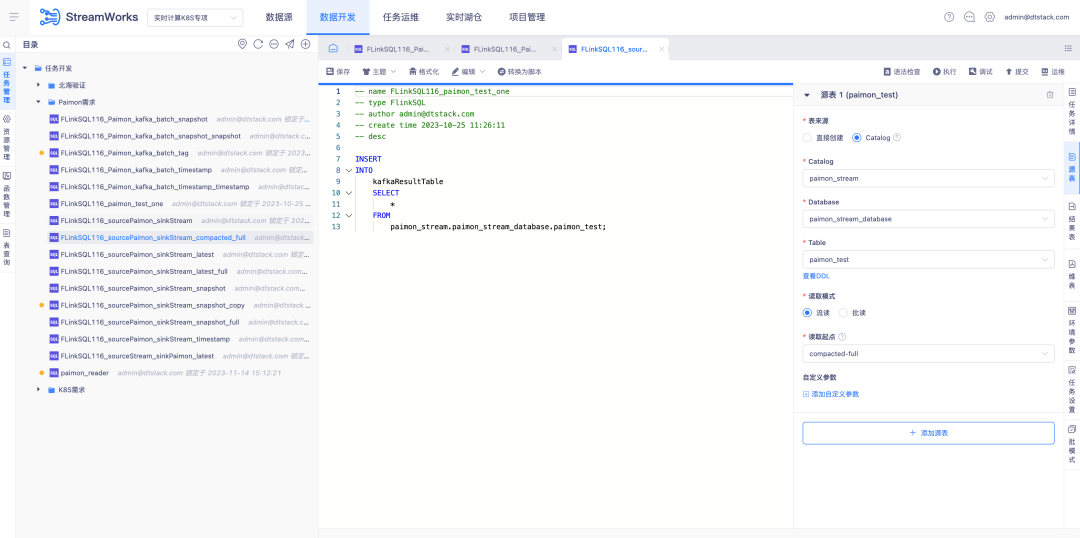
5.In FlinkSQL integriertes FlinkCDC
Hintergrund: FlinkCDC ist eine Open-Source-Echtzeit-Sammlungskomponente mit sehr hoher Iterationsgeschwindigkeit. Das zugrunde liegende Flink-Framework ist dasselbe wie das von uns verwendete ChunJun-Framework. Daher erwägen wir, es zu einer Standardkomponente für die Echtzeit-Plattformbereitstellung zu machen und in unser System zu packen.
Beschreibung der neuen Funktionen:
1. Echtzeit-Standardbereitstellungspaket, Einrichtung der FlinkCDC-Echtzeiterfassung
2. Plattform-Skriptmodus: Sie müssen die integrierten Erfassungsfunktionen und unterstützten Connectors von FlinkCDC überprüfen
3. Der Plattform-Assistentenmodus konfiguriert die von FlinkCDC unterstützte Connector-Sammlung entsprechend der Projektsituation.
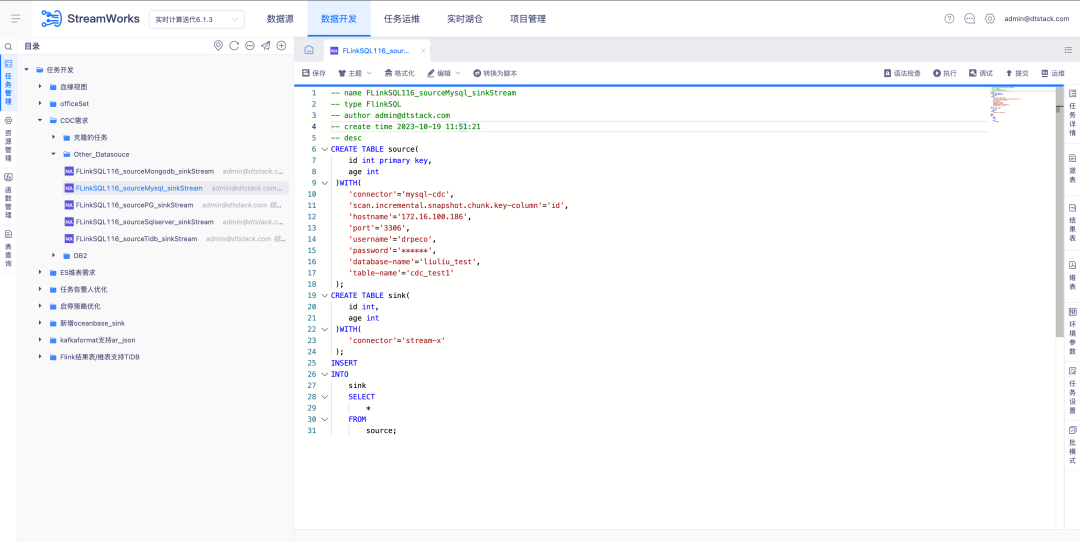
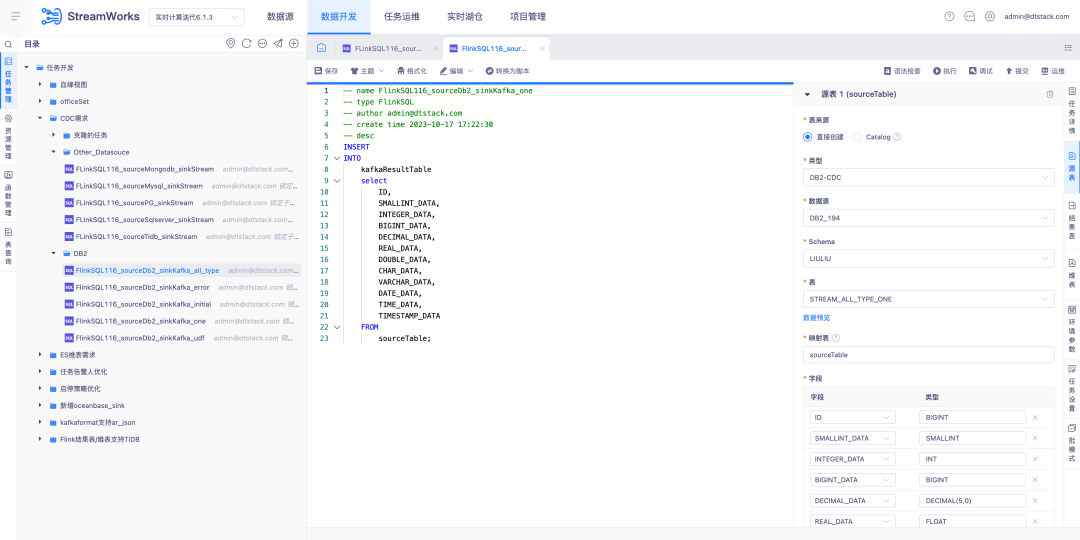
6.FlinkSQL unterstützt die FlinkCDC DB2-Datenquelle
Hintergrund: Kunden müssen die Echtzeiterfassung von DB2 unterstützen. Da die Entwicklung von CDC Connector schwierig ist, unterstützt FinkCDC dies lediglich, sodass die unterste Ebene die Funktionen von FlinkCDC übernimmt.
Neue Funktionsbeschreibung: Die Echtzeitplattform unterstützt den Assistentenmodus zum Konfigurieren der Quelltabelle als DB2-CDC-Datenquelle .
Funktionsoptimierung
1.Optimierung der Fortsetzungslogik
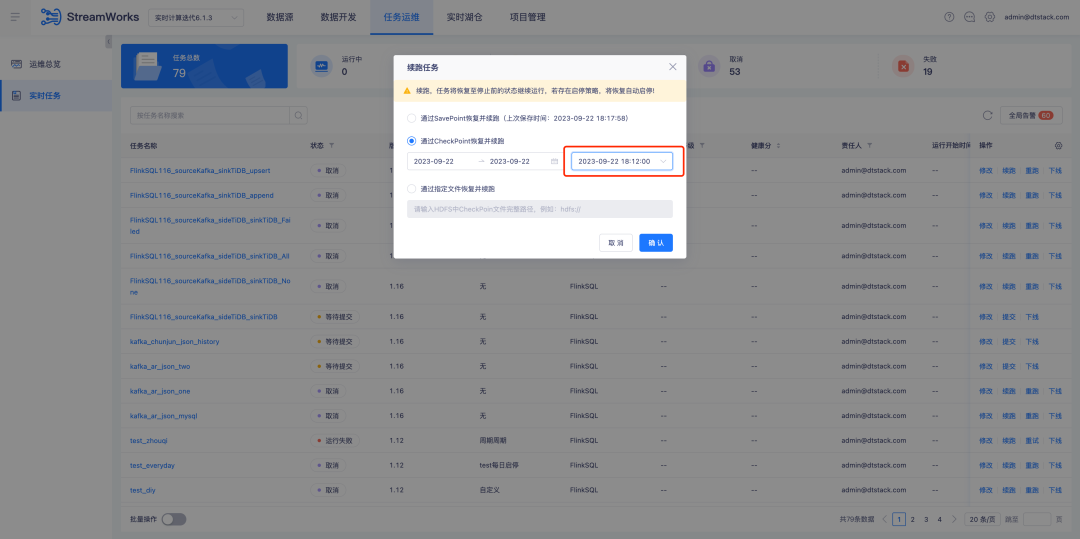
Hintergrund: Wenn eine Echtzeitaufgabe über CheckPoint fortgesetzt wird und weiter ausgeführt wird, muss manuell ein Zeitpunkt ausgewählt werden. Tatsächlich wird jedoch in den meisten Fortsetzungsszenarien der neueste CheckPoint ausgewählt.
Beschreibung der Erlebnisoptimierung: Bei der Optimierung zur Wiederherstellung und Fortsetzung der Ausführung über CheckPoint wird automatisch der nächstgelegene CheckPoint innerhalb des Datums ausgewählt.
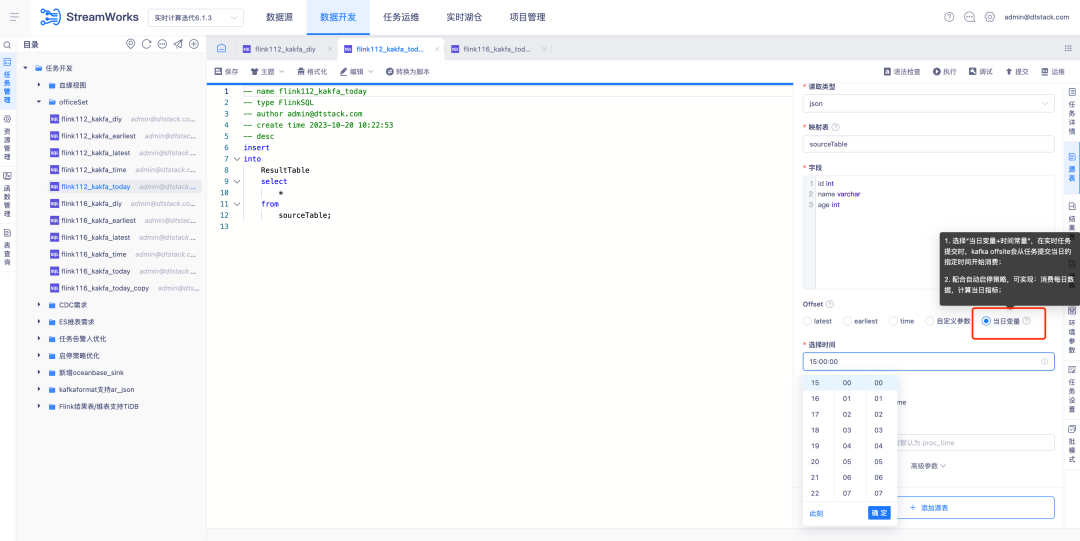
2. Start-Stopp-Strategie/Offsite-Optimierung
Hintergrund: Bei der intensiven Nutzung durch Kunden haben wir festgestellt, dass Aspekte wie Start-Stopp-Strategie, Einreichung und Wiederholung optimiert werden können, um einen effizienteren Arbeitsablauf und ein besseres Benutzererlebnis zu erreichen.
Derzeit ist die Offsite-Zeitstempelkonfiguration in unseren Datenentwicklungs-Quelltabellen behoben. In Echtzeit-Aufgabenberechnungsszenarien konzentrieren sich einige Kunden jedoch nur auf die Datenberechnung des Tages und konfigurieren daher eine Start-Stopp-Richtlinie, um die Aufgabe jeden Tag erneut auszuführen. Sie möchten die Aufgabe jeden Tag ab Mitternacht erneut ausführen können, anstatt einen festen Zeitstempel zu verwenden. Obwohl Latest diese Anforderung theoretisch erfüllen kann, kann der Verbrauch der Echtzeit-Task-Startzeit dazu führen, dass die tatsächliche Laufzeit von Null abweicht, was zu Datenfehlern führt.
Anleitung zur Erlebnisoptimierung:
1. Optimieren Sie die Start-Stopp-Richtlinienkonfiguration , unterstützen Sie jetzt tagesübergreifende Start-Stopp-Richtlinien und verbessern Sie die aktuelle Interaktion der Start-Stopp-Richtlinienseite, um ein effizienteres und komfortableres Betriebserlebnis zu bieten
2. Datenentwicklung – Quelltabelle, unterstützt parametrisierte Konfiguration von Offsite-Standorten
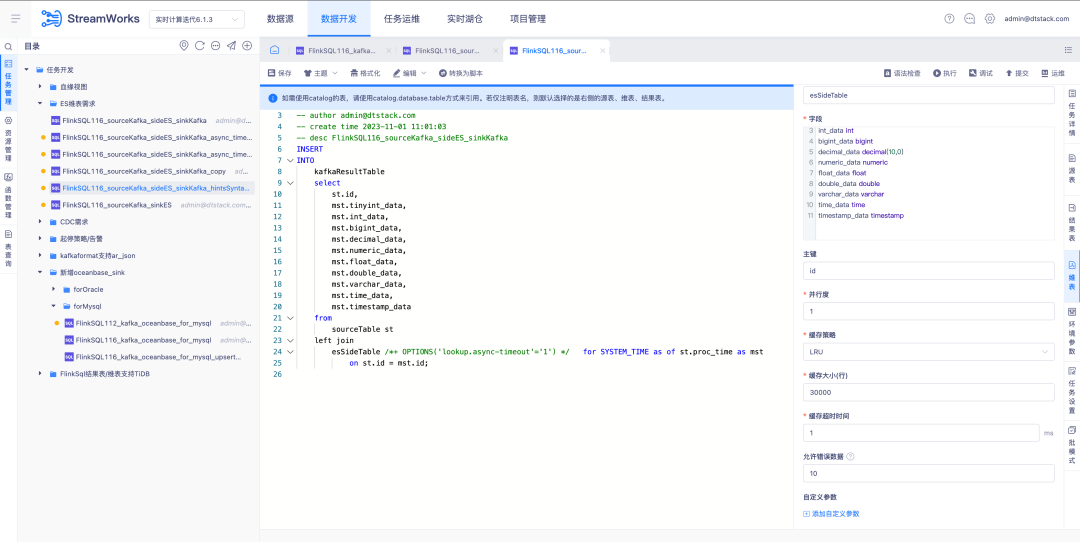
3.FlinkSQL1.16 Version ES7.x Plug-in-Optimierung
Hintergrund: Das ES-Plugin von FlinkSQL Version 1.10 unterstützt die Konfiguration der Dimensionstabellen-Timeout-Zeit und des Timeout-Datenlimits. Diese Funktion ist in der aktuellen FlinkSQL-Version 1.16 vorübergehend nicht verfügbar und wird aktiv optimiert.
Anleitung zur Erlebnisoptimierung:
Die Dimensionstabelle des FlinkSQL1.16-Plug-ins ES7.x konfiguriert table.exec.async-lookup.timeout oder verwendet die Hints-Syntax, um das Zeitlimit festzulegen. Wenn die Aufgabe im LRU-Modus der Dimensionstabelle ausgeführt wird, dauert die Zeitüberschreitung der asynchronen Abfrage Wirkung.
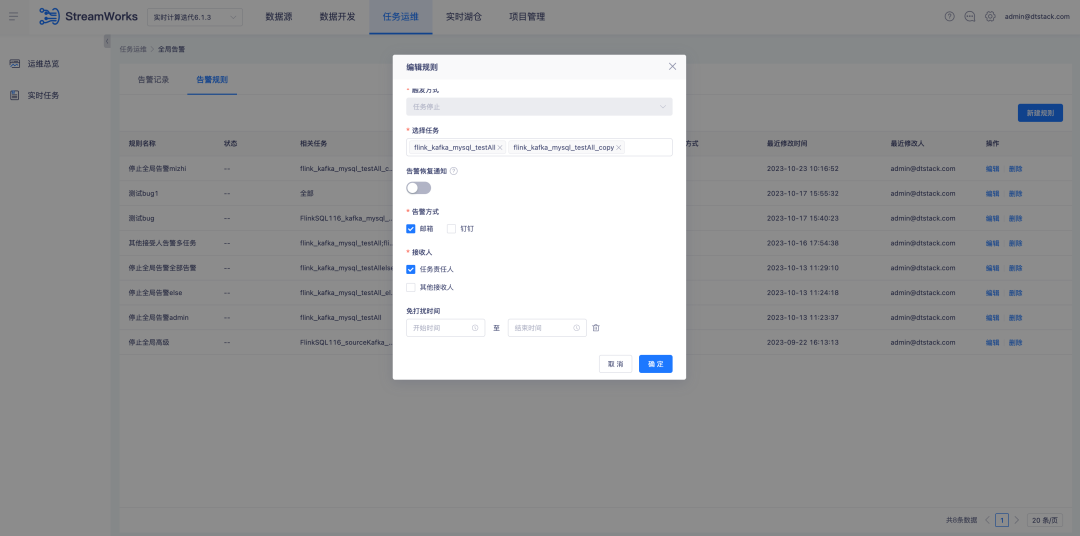
4.Optimierung der Alarmkonfiguration
Hintergrund: In den Aufgabenalarmregeln muss die Alarmempfangskonfiguration manuell ausgewählt werden. Es ist nicht möglich, Alarminformationen automatisch entsprechend der für die Aufgabe verantwortlichen Person abzugleichen und zu senden. Dies ist jedoch auch in der globalen Alarmkonfiguration der Fall Es ist nicht möglich, die entsprechenden Alarminformationen automatisch gemäß der für die Aufgabe verantwortlichen Person zu senden.
Anleitung zur Erlebnisoptimierung:
1. Empfängeranpassung für einzelne Aufgabenalarme . Die für die Aufgabe zuständige Person kann standardmäßig über das Auswahlfeld ausgewählt werden.
2. Die globale Alarmregelkonfiguration wird tatsächlich an die für jede Aufgabe verantwortliche Person gesendet, wenn die für die Aufgabe verantwortliche Person ausgewählt wird. Wenn andere Empfänger ausgewählt werden, wird die ausgewählte Aufgabe an den ausgewählten Empfänger gesendet, wenn die ausgewählte Aufgabe abnormal ist.
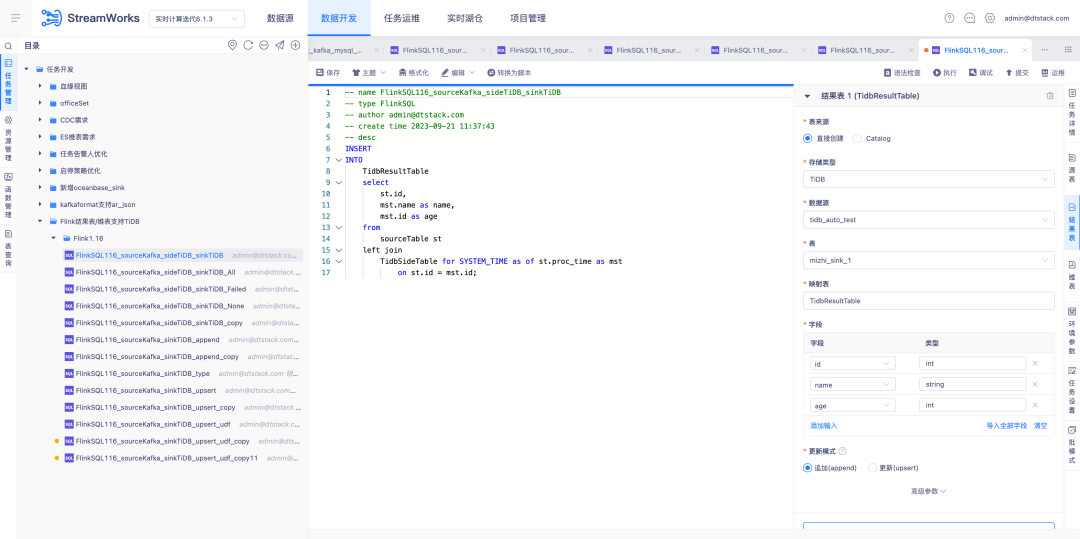
5.FlinkSQL1.12 & 1.16 Version Tidb Plug-in-Plattform ist kompatibel
Hintergrund: Die Anpassung der FlinkSQL-Versionen 1.12 und 1.16 an Tidb ist abgeschlossen. Die Plattformschicht wurde jedoch erst in Version 1.10 angepasst, sodass die Versionen 1.12 und 1.16 nicht unterstützt werden.
Anleitung zur Erlebnisoptimierung:
Die Echtzeitplattform ist mit den Tidb-Plug-In-Versionen 1.12 und 1.16 kompatibel und muss sowohl Dimensionstabellen als auch Ergebnistabellen unterstützen.
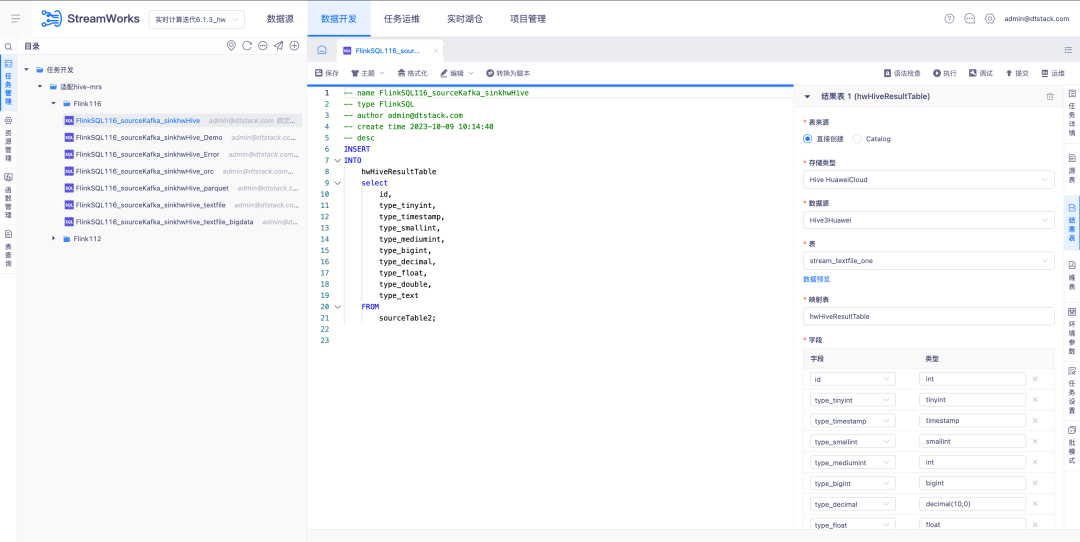
6.FlinkSQL1.12&1.16 Version Hive HuaweiCloud-Anpassung
Hintergrund: Echtzeit-Backup von Kafka-Daten wird in MRS Hive eingegeben. Wenn ein Problem mit den Echtzeit-Berechnungsdaten auftritt, können die Backup-Nachrichten in Hive analysiert werden.
Anleitung zur Erlebnisoptimierung:
FlinkSQL Version 1.12 und 1.16 sind an Hive huaweiCloud angepasst. Das Datenquellenzentrum, die Engine und die Plattform werden gleichzeitig entwickelt, um die Hive-huaweiCloud- Ergebnistabelle zu unterstützen. Sie müssen auf das Szenario der Aktivierung von Kerberos achten.
Datendienstplattform
Neue Funktionsupdates
1. Unterstützt die HBase TBDS-Versionserstellungs-API
HBase TBDS-Versionserstellungs-API hinzugefügt, einschließlich: Generierungs-API im Assistentenmodus , Import und Export sowie Veröffentlichung in Zielprojekten.

Funktionsoptimierung
1.Oracle-Datenquelle unterstützt DML
Verbessern Sie die von DML unterstützten Datenquellen .
2. Beim Analysieren von Kommentaren im benutzerdefinierten SQL-Modus wird die Beschreibung nicht mehr überschrieben
Hintergrund: Für die historische Logik werden die geänderten Anweisungen durch die mit der Datenbank gelieferten Kommentare überschrieben, nachdem das benutzerdefinierte SQL-Schema für die Datenbank erneut analysiert wurde.
Anweisungen zur Erlebnisoptimierung: Ändern Sie die historische Logik. Für die geänderten Anweisungen werden die Kommentare in der Datenbank nach dem erneuten Parsen nicht mehr überschrieben.
3. Nachdem Berechtigungen auf Zeilenebene aktiviert wurden, ist es nicht erforderlich, sie standardmäßig auszufüllen.
Hintergrund: Für historische Berechtigungen auf Zeilenebene werden Berechtigungen auf Zeilenebene über die Felder in der Tabelle aktiviert. Nach der Aktivierung sind die Felder standardmäßig erforderlich und die Stornierung durch den Benutzer wird nicht unterstützt.
Beschreibung der Erlebnisoptimierung: Diese Iteration passt die historische Logik an, die auf der API-Ebene aktiviert wird. Wenn die API die Tabelle verwendet, wird sie durch Berechtigungen auf Zeilenebene eingeschränkt .
4. Framework-Version und Komponenten-Upgrade
Die Version des Spring Cloud (Boot)-Frameworks wird aktualisiert, und die Nacos-Komponente wird aktualisiert, um die Wahrscheinlichkeit von Schwachstellen zu verringern und die Stabilität der API selbst zu verbessern.
Customer Data Insight-Plattform
Neue Funktionsupdates
1.Unterstützt benutzerdefinierte UDF-Funktionen
Hintergrund: Die Mobiltelefonnummer, die ID-Nummer und andere Daten, die an den vom Kunden verarbeiteten Daten beteiligt sind, sind verschlüsselte Daten. Aus Sicht der Prüfung können diese Daten nicht im Klartext angezeigt werden, es wird jedoch Szenarien geben, in denen Klartextinhalte vorliegen im übergeordneten Geschäft angezeigt, zum Beispiel: SMS-Marketing auf Basis von Mobiltelefonnummern.
Kunden müssen den Entschlüsselungsprozess so spät wie möglich durchführen, ihn zum Abschluss auf die Etikettenplattform stellen und über die Anpassung der UDF-Funktion benutzerdefinierte Etiketten hinzufügen, um die Verarbeitung abzuschließen.
Beschreibung der neuen Funktionen: Dem Tag Center wurde ein neues Funktionsverwaltungsmodul hinzugefügt , mit dem UDF-Funktionen erstellt, angezeigt und gelöscht werden können (nur Trino385 und höhere Versionen unterstützen das Erstellen von Funktionen).
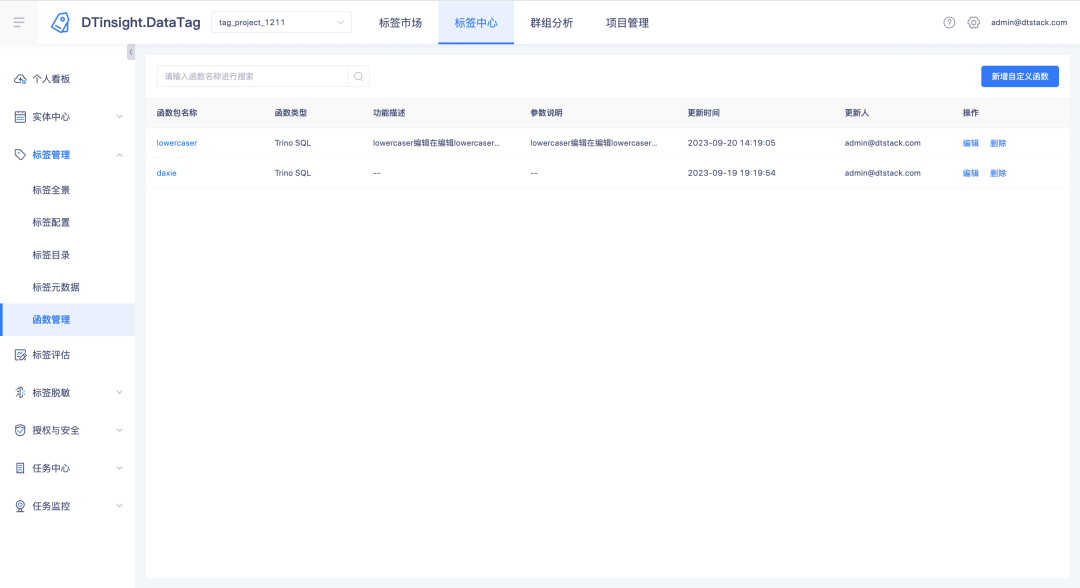
Bei hochgeladenen Funktionen können Sie auf den Funktionsnamen klicken, um Funktionsdetails anzuzeigen.
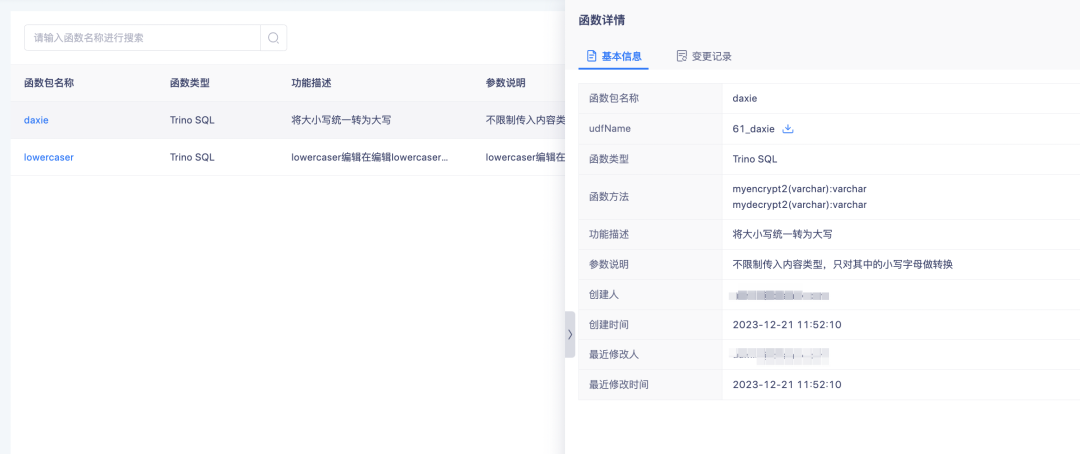
Die Upload-Funktion wird hauptsächlich zur Verarbeitung abgeleiteter SQL-Tags verwendet.
2. Unterstützt die Verarbeitung von Mehrwert-Tags
Hintergrund: Die aktuellen Verarbeitungsregeln für abgeleitete Tags und kombinierte Tags lauten: Wenn eine Instanz zum ersten Mal eine bestimmte Regelbedingung erfüllt, wird der entsprechende Tag-Wert auf der Instanz markiert und andere Tag-Werte werden am Ende nicht mehr abgeglichen , werden die Ergebnisse der Einzelwert-Tags in der Datenbank gespeichert.
In praktischen Anwendungen schließen sich die Bedingungen jedoch nicht unbedingt gegenseitig aus. Beispielsweise erhält der Benutzer ein Produktpräferenzetikett, das auf der Häufigkeit basiert, mit der der Benutzer einen bestimmten Produkttyp gekauft hat. Ein Benutzer kann sowohl Möbel als auch Kleidung mögen. In diesem Fall müssen mehrere Werte unterstützt werden.
Beschreibung der neuen Funktionen:
Abgeleitete Regel-Tags, abgeleitete SQL-Tags, Kombinations-Tags und die Verarbeitung benutzerdefinierter Tags unterstützen die Konfiguration als mehrwertige Tags , und das System berechnet sie basierend auf dem festgelegten Tag-Werttyp.
• Einzelwert-Tags: Abgleich in der angegebenen Reihenfolge, wenn ein bestimmter Tag-Wert erreicht wird. Das Datenergebnis enthält höchstens einen Tag-Wert.
• Mehrwertige Tags: Übereinstimmung in der Reihenfolge der Regelkonfiguration. Jede Regel wird einmal abgeglichen. Das Datenergebnis enthält höchstens n konfigurierte Tag-Werte.
Basierend auf den Berechnungsergebnissen zählen die Labeldetails die Anzahl der Instanzen für jedes einzelne Label, d. h. die Summe der Anzahl der Instanzen, die von jedem Labelwert eines Einzelwertlabels abgedeckt werden, ist die Anzahl der Instanzen, die vom Label abgedeckt werden und die Anzahl der Instanzen, die von jedem Labelwert eines mehrwertigen Labels abgedeckt werden. Die Summe der Zahlen ist größer oder gleich der Anzahl der Labelabdeckungsinstanzen.
3. Angepasstes Rollen-Docking-Businesscenter
Hintergrund: Zuvor waren Rollen im System integriert und Rollenberechtigungen konnten nicht angepasst werden. Die Funktionen waren zu fest und konnten nicht flexibel an die tatsächlichen Geschäftsszenarien angepasst werden In Version 6.0 verfügt das Business Center über eine Anpassungsrollenfunktion. Das Tag-Produkt ist mit dieser Funktion des Business Centers verbunden, um die folgenden Effekte zu erzielen:
1. Unterstützen Sie neue Rollen
2. Unterstützen Sie benutzerdefinierte Rollenberechtigungen
Neue Funktionsbeschreibung: Konfigurieren Sie Rollen und ihre Indikatorberechtigungen im Business Center, und die Beschriftungsplattform führt automatisch die Ergebnisse der Berechtigungskonfiguration zur Abfrage ein.
1. Fügen Sie neue Rollen hinzu und konfigurieren Sie Rollenberechtigungspunkte im Business Center:
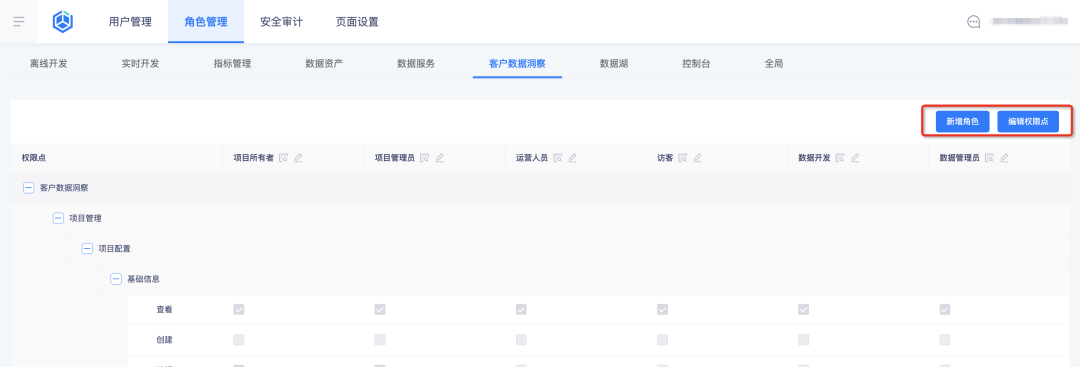
2. Rollen und ihre Berechtigungspunkte auf der Tag-Plattform anzeigen:
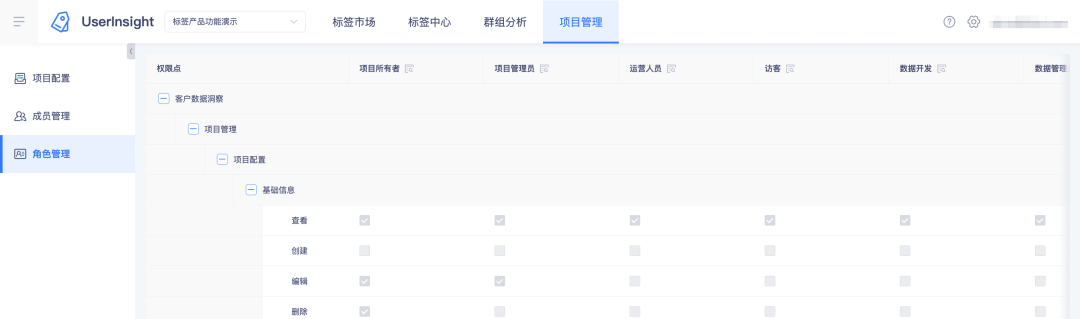
4. Das Datenanzeigeformat unterstützt die Anpassung
Hintergrund: Bei numerischen Tags wird die Einstellung der Anzeigegenauigkeit derzeit nicht unterstützt, was dazu führt, dass einige Ganzzahlen wie 1 und einige Dezimalzahlen wie 1,234 angezeigt werden. Das allgemeine Leseerlebnis ist nicht hoch Erfahrung ist es notwendig, Einstellungen für die Datenanzeigeregel hinzuzufügen.
Beschreibung der neuen Funktionen:
1. Beim Erstellen/Bearbeiten von Entitäten, Bearbeiten von atomaren Tags und Erstellen/Bearbeiten abgeleiteter SQL-Tags wird das Festlegen von Anzeigeregeln für numerische Tags unterstützt.
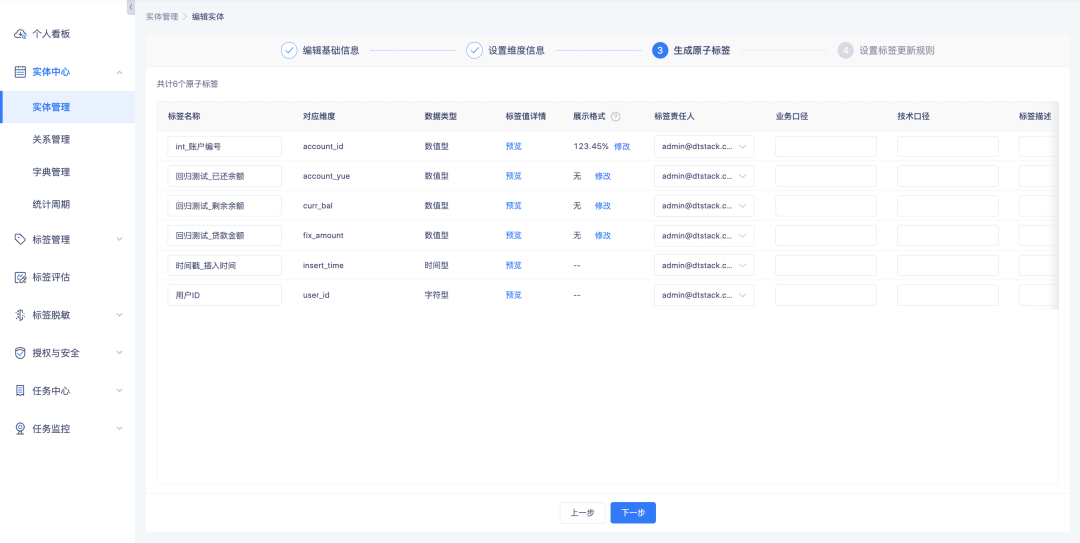
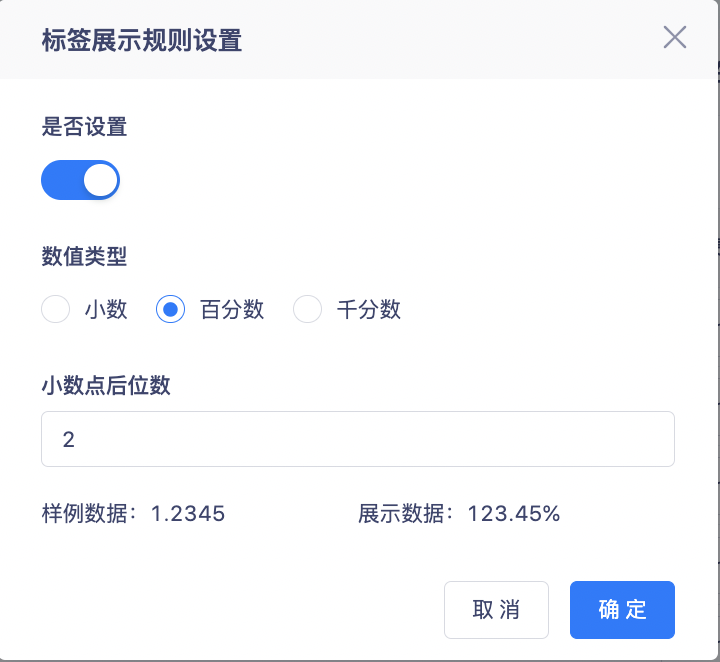
2. Unterstützt die Anzeige als Dezimalzahlen, Prozentsätze und Tausendstel sowie das Festlegen der Anzahl der Nachkommastellen.
3. Die auf gruppenbezogenen Seiten angezeigten Tag-Daten werden gemäß den festgelegten Anzeigeregeln angezeigt.
5. Das Hochladen von Tag-/Gruppendateien unterstützt die Anzeige des Upload-Fortschritts
Hintergrund: Die Dateiimportfunktion lädt derzeit ohne Fortschrittsaufforderungen hoch. Wenn die Datei zu groß ist, ist die Wartezeit lang, was dazu führt, dass Benutzer falsch verstehen, dass die Seite hängen bleibt, um den aktuellen Fortschritt deutlich zu machen Benutzer.
Beschreibung der neuen Funktionen:
1. Fortschrittsmeldungen während Etiketten-, Gruppendatei-Upload- und Offline-Abfrageaufgaben hinzugefügt.
2. Das Hochladen von Gruppendateien wurde angepasst, um das Hochladen von Dateien mit einer Größe von bis zu 500 MB zu unterstützen.
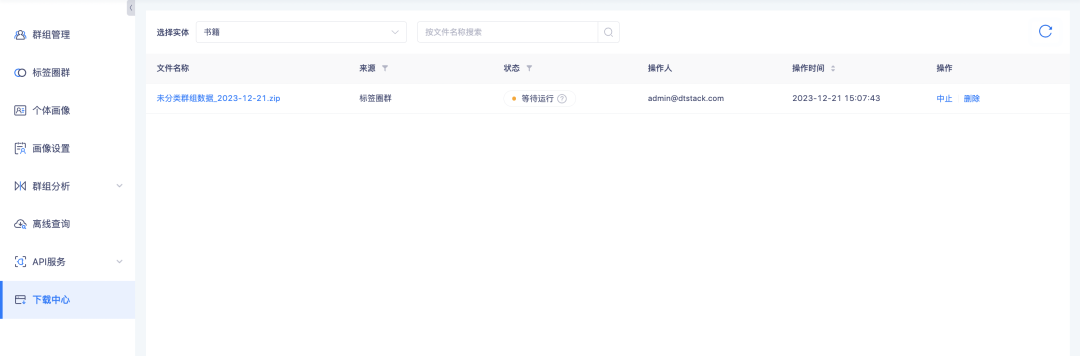
6. Das Download-Center unterstützt die Abfrage des Download-Fortschritts.
Hintergrund: Während des Datendownloadvorgangs dauert es aufgrund der großen Datenmenge lange, die Daten vorzubereiten, bevor sie heruntergeladen werden können. Benutzer erwarten sie nicht, wenn sie sie verwenden, und müssen häufig aktualisieren, um festzustellen, ob der Download erfolgt durchgeführt werden kann. Es müssen Aufforderungen zum Download-Fortschritt hinzugefügt werden, um Benutzern die Entscheidung zu erleichtern, wie lange sie warten müssen.
Neue Funktionsbeschreibung: Der Status der Download-Center- Aufgabe fügt den Status „Warten auf Ausführung“ und „Abgebrochen“ hinzu. Unter anderem hängt das Herunterladen der Tag-Kreis-Gruppen-Gruppenliste, der Gruppendetails-Gruppenliste, des Hochladens der lokalen Gruppen-Instanzenliste, der Offline-Abfrage-Gruppendetails-Instanzenliste, der Gruppenschnittmenge und der Differenz-Instanzenliste von den Gruppenlistendaten ab Das Download-Volumen ist groß, es wird im seriellen Download-Modus ausgeführt. Aufgaben, die sich auf die Gruppenliste beziehen, werden nacheinander in die Warteschlange gestellt. Andere Downloads mit kleinem Datenvolumen werden direkt ausgeführt . Während Aufgaben ausgeführt werden, können Sie nicht mehr benötigte Aufgaben abbrechen.
Funktionsoptimierung
1. Der Datenexport ist so angepasst, dass Dateien über das Downloadcenter heruntergeladen werden
Hintergrund: Auf einigen Seiten werden Dateidownloads direkt heruntergeladen, wodurch sich die Schaltfläche immer im laufenden Zustand befindet und der Benutzer den Download-Fortschritt nicht erkennen kann.
Beschreibung der Erlebnisoptimierung: Nachdem Sie auf die Schaltfläche zum Datenexport geklickt haben, wird die Datei asynchron heruntergeladen. Nach Abschluss des Downloads können Sie das Modul „Download Center“ aufrufen, um die Datendetails herunterzuladen: Tag Kreisgruppe – Datenexport, Gruppendetails – Gruppenlistendatenexport, Hochladen lokaler Gruppen – Instanzlistendatenexport, Offline-Abfrage – Hochladen lokaler Gruppen/Gruppenschnittpunkte und Differenzdetails – Datenexport, Gruppenschnittpunkt und Differenzdatenexport.
Wenn die Datenmenge zu groß ist, exportiert das System sie in separate Dateien, basierend auf der vom Benutzer festgelegten Obergrenze der Anzahl von Datensätzen.
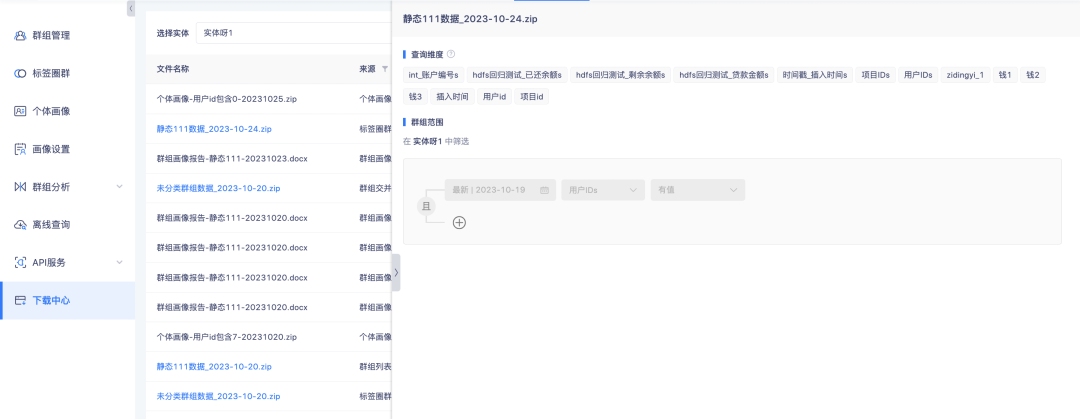
2. Listendaten von Tag-Circle-Gruppen und Gruppendetails im Download-Center unterstützen die Anzeige von Konfigurationsdetails.
Hintergrund: Derzeit gibt es im Download-Center viele Dateiquellen und es ist unpraktisch, den Inhalt nur anhand der Dateinamen zu unterscheiden. Um die Datenverfügbarkeit zu verbessern, müssen die Dateidatenquellen erhöht werden.
Beschreibung der Erlebnisoptimierung: Listen Sie Daten aus Tag-Kreisgruppen auf und klicken Sie auf Gruppendetails. Klicken Sie auf die Seitenleiste, um die Konfigurationsdetails zu öffnen.
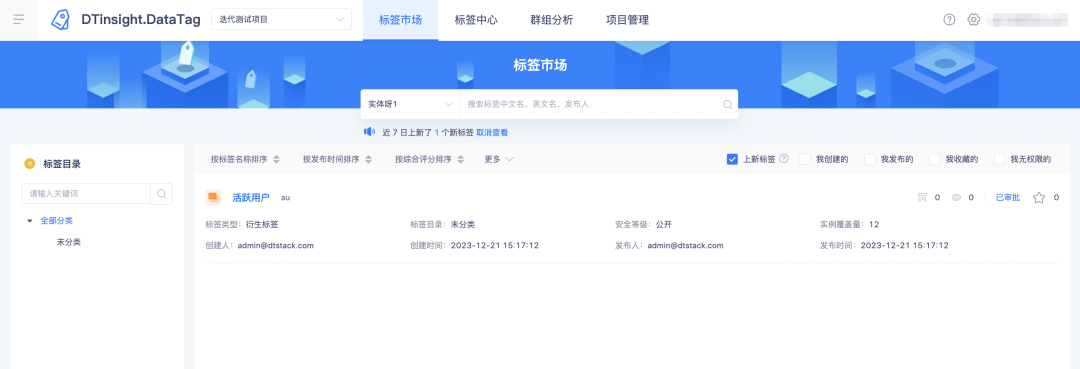
3. Optimierung neuer Tag-Funktionen im Tag-Markt
Hintergrund: Derzeit erklärt die Plattform die Definition neuer Tags nicht und muss hinzugefügt werden.
Beschreibung der Erlebnisoptimierung: Neue Tags auf der Plattform werden als die letzten 24 Stunden definiert, aber bei der tatsächlichen Nutzung achten die Leute am Wochenende im Allgemeinen nicht darauf Freitag bis Sonntagmorgen können nicht vor Ort benachrichtigt werden. Passen Sie die Definition an die letzten 7 Tage an.
4. Optimierung der unterproduktübergreifenden Anpassung der Schaltberechtigungen
Wenn ein getaggtes Produkt zwischen Unterprodukten gewechselt wird, fehlt der Tab-Inhalt auf der Seite. Dies wird durch Berechtigungsprobleme verursacht. Diese Optimierung stellt sicher, dass die Funktion beim Seitenwechsel zwischen Produkten verfügbar ist.
5. Unterstützt die Anpassung und Anpassung der Spaltenbreite
Gruppenliste, Gruppendetails-Gruppenliste, Tag-Kreis-Gruppe-Benutzerliste, Gruppenschnittpunkt- und Differenz-Instanzliste sowie die Spaltenbreite der Tag-Liste unterstützen die Anpassung.
Nach der Anpassung der Spaltenbreite wird sie für spätere Verwendungen basierend auf dem aktuellen Browser und dem aktuell angemeldeten Benutzer wirksam. Wenn sich der Benutzer mit einem neuen Browser anmeldet, den Cache des aktuellen Browsers löscht oder sich erneut anmeldet, wird die Spaltenbreite wirksam Die Standardeinstellungen werden angezeigt.
Plattform zur Indikatorverwaltung
Neue Funktionsupdates
1. Angepasstes Rollen-Docking-Businesscenter
Hintergrund: Bisher waren Rollen im System integriert und Rollenberechtigungen konnten nicht angepasst werden. Die Funktionen waren zu fest und konnten nicht flexibel an das tatsächliche Geschäftsszenario des Kunden angepasst werden .
Beschreibung der neuen Funktionen:
Konfigurieren Sie die Rolle und ihre Indikatorberechtigungen im Business Center . Die Indikatorplattform führt dann automatisch die Ergebnisse der Berechtigungskonfiguration für die Abfrage ein:
1. Fügen Sie neue Rollen hinzu und konfigurieren Sie Rollenberechtigungspunkte im Business Center
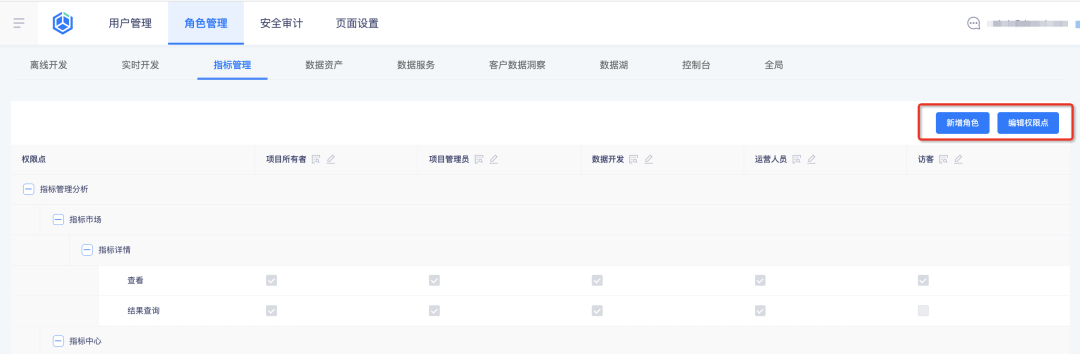
2. Rollen und ihre Berechtigungspunkte auf der Indikatorplattform anzeigen
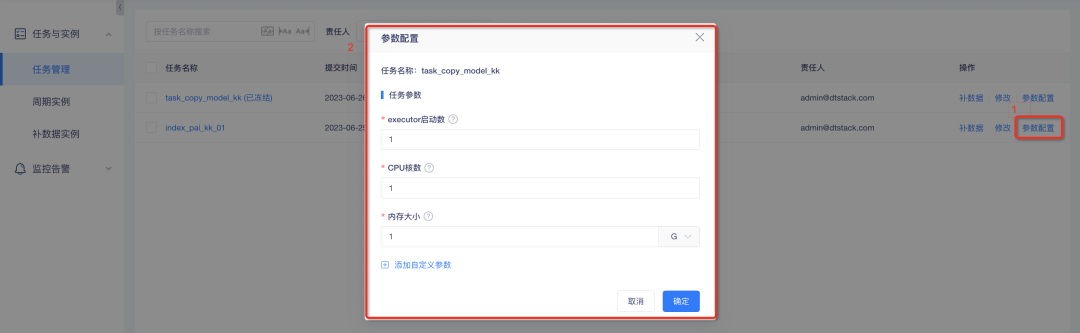
2. Spark- und Datensynchronisierungsaufgaben unterstützen die benutzerdefinierte Parameterkonfiguration
Hintergrund: Bei Spark-Aufgaben und Datensynchronisierungsaufgaben können Parameteranpassungen derzeit nur über die Konsole vorgenommen werden. Die Anpassungsergebnisse werden jedoch global wirksam. Die Unterschiede in der Datengröße zwischen den Indikatoraufgaben sind jedoch groß und die Konfiguration derselben Parameter führt zu einer Verschwendung Daher können Parameter auf Aufgabenebene für Spark- und Datensynchronisierungsaufgaben festgelegt werden, um eine flexible Steuerung von Aufgaben zu ermöglichen.
Beschreibung der neuen Funktionen:
1. Benutzerdefinierte Parameterkonfiguration für Spark-Tasks : Darunter können die Anzahl der Executor-Starts, die Anzahl der CPU-Kerne und die Speichergröße festgelegt werden
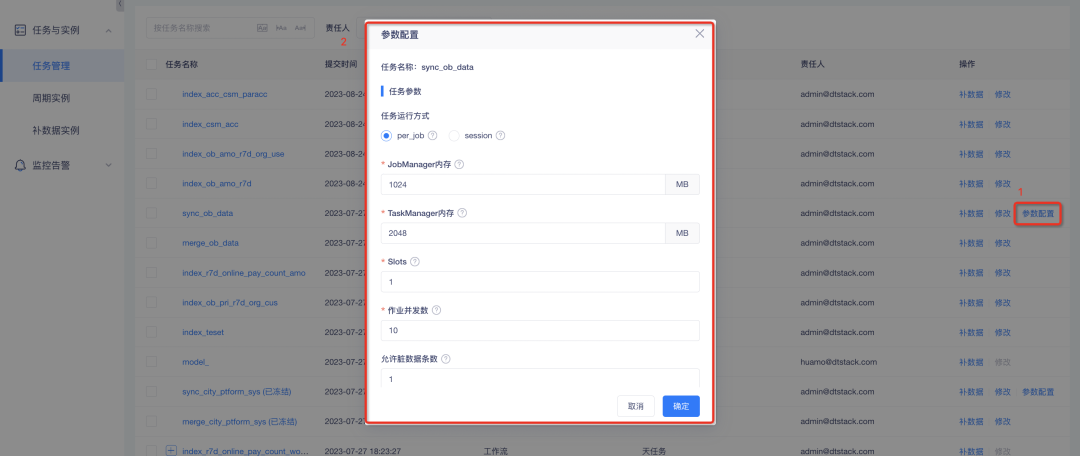
2. Benutzerdefinierte Parameterkonfiguration für Datensynchronisierungsaufgaben : Im Jobmanager-Speicher, Taskmanager-Speicher und Slots sind die Anzahl der gleichzeitigen Jobs und die WriteBufferSize von HBase erforderlich
Funktionsoptimierung
1. Der Browser unterstützt das gleichzeitige Öffnen mehrerer Projekte
Hintergrund: In der Verlaufsfunktion speichert das Cookie keine Projektparameter. Wenn der Datenstapel ein neues Projektfenster öffnet, wird der Inhalt des Verlaufsfensters aktualisiert und der Benutzer kehrt zur Projektlistenseite für das Projekt zurück Auswahl, die sich auf die Nutzung durch den Kunden auswirkt.
Beschreibung der Erlebnisoptimierung: Diese Optimierung unterstützt den Browser dabei, mehrere Projekte gleichzeitig für Abfragen, Operationen usw. zu öffnen, um die Effizienz der Produktnutzung zu verbessern.
2.Edge-Browser kompatibel
Kompatibel mit dem egde-Browser, werden die Funktionen entsprechend angepasst, um die Benutzerfreundlichkeit des Produkts auf gängigen Browsern zu verbessern.
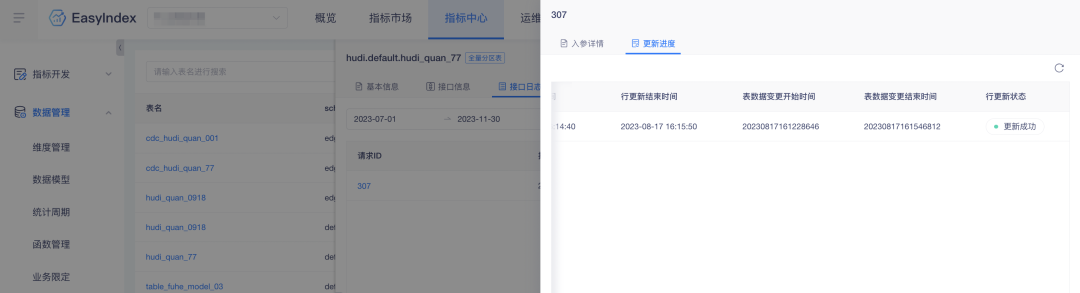
3. Aktualisierungszeit der Zusatztabelle für Zeilenaktualisierung
Hintergrund: Dem Datensatz zur Zeilenaktualisierung fehlt der Zeitraum für die Änderung der Tabellendaten, was den Datenabruf unpraktisch macht. Um die Effizienz des Datenabrufs zu verbessern, werden der Plattform relevante Daten hinzugefügt.
Beschreibung der Erlebnisoptimierung: Die Aktualisierung der Indikatorzeile fügt die Start- und Endzeit der Tabellendatenänderung hinzu.
4. Fügen Sie eine manuelle Aktualisierungsfunktion zum Zeilenaktualisierungsstatus hinzu
Während des Zeilenaktualisierungsprozesses wird der Seite eine Aktualisierungsschaltfläche hinzugefügt, um die Aktualisierungseffizienz zu verbessern, um eine rechtzeitige Verfolgung des Aktualisierungsfortschritts zu ermöglichen.
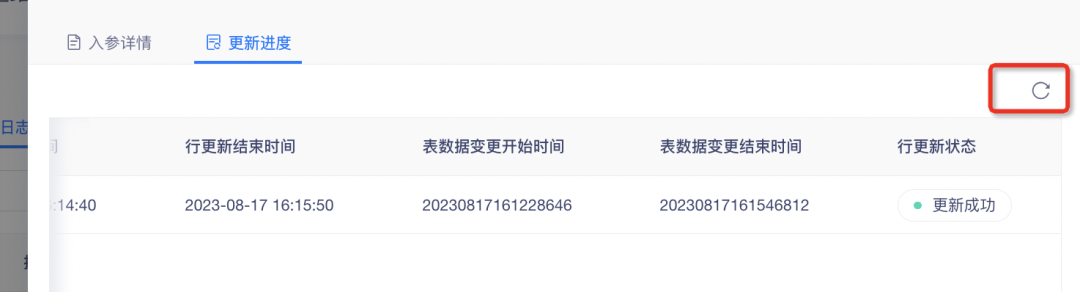
5. Optimierung modellbestückter dimensionaler Objekte und dimensionaler Attributfunktionen
Wenn Sie das Modell bearbeiten, füllt das System im Schritt des Festlegens der Dimensionsinformationen standardmäßig die an die Hauptdimensionstabellenfelder gebundenen Dimensionsinformationen auf, wenn der Benutzer die zugehörigen Dimensionen in der historischen Version geändert hat und Sie nicht darauf achten Aufgrund der Anpassung während des Bearbeitungsprozesses werden falsche Daten gespeichert. Um eine Datenfehlerrate zu vermeiden, werden die in der vorherigen Version gespeicherten Informationen angepasst.
6. Das API-Gateway unterstützt benutzerdefinierte Präfixe
Die Präfixinformationen des Indikators werden derzeit in das Konfigurationselement der API geschrieben. Gleichzeitig verfügt die API derzeit über eine benutzerdefinierte Präfixfunktion, um die Flexibilität der API-Konfiguration zu verbessern. Wenn die API-Konfigurationselemente des Indikators zu diesem Zeitpunkt nicht mit dem benutzerdefinierten API-Präfix übereinstimmen, können die Daten nicht normal aufgerufen werden. Sie müssen an die Konfigurationseinstellungen der Docking-API angepasst werden, um sicherzustellen, dass die globale Konfiguration eindeutig ist.
Download-Adresse „Dutstack Product White Paper“: https://www.dtstack.com/resources/1004?src=szsm
Downloadadresse „Data Governance Industry Practice White Paper“: https://www.dtstack.com/resources/1001?src=szsm
Wenn Sie mehr über Big-Data-Produkte, Branchenlösungen und Kundenbeispiele erfahren oder sich beraten lassen möchten, besuchen Sie die offizielle Website von Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Linus hat es sich zur Aufgabe gemacht, zu verhindern, dass Kernel-Entwickler Tabulatoren durch Leerzeichen ersetzen. Sein Vater ist einer der wenigen Führungskräfte, die Code schreiben können, sein zweiter Sohn ist Direktor der Open-Source-Technologieabteilung und sein jüngster Sohn ist ein Open-Source-Core Mitwirkender : Natürliche Sprache wird immer weiter hinter Huawei zurückfallen: Es wird 1 Jahr dauern, bis 5.000 häufig verwendete mobile Anwendungen vollständig auf Hongmeng migriert sind Der Rich - Text-Editor Quill 2.0 wurde mit einer deutlich verbesserten Erfahrung von Ma Huateng und „ Meta Llama 3 “ veröffentlicht Quelle von Laoxiangji ist nicht der Code, die Gründe dafür sind sehr herzerwärmend. Google hat eine groß angelegte Umstrukturierung angekündigt