
Spark ist eine schnelle, vielseitige und skalierbare Big-Data-Computing-Engine . Sie bietet die Vorteile hoher Leistung, Benutzerfreundlichkeit, Fehlertoleranz, nahtloser Integration in das Hadoop-Ökosystem und hoher Community-Aktivität. Im tatsächlichen Einsatz gibt es vielfältige Anwendungsszenarien:
· Datenbereinigung und -vorverarbeitung: In Big-Data-Analyseszenarien benötigen Daten normalerweise Bereinigungs- und Vorverarbeitungsvorgänge, um die Datenqualität und -konsistenz sicherzustellen. Spark bietet eine umfangreiche API, die Daten bereinigen, filtern, transformieren und andere Vorgänge durchführen kann.
· Stapelverarbeitungsanalyse: Spark eignet sich für Stapelverarbeitungsaufgaben in verschiedenen Anwendungsszenarien, einschließlich statistischer Analyse, Data Mining, Merkmalsextraktion usw. Benutzer können die leistungsstarke API und die integrierten Bibliotheken von Spark verwenden, um komplexe Datenverarbeitung und -analyse zum Mining von Daten durchzuführen . innerer Wert in
· Interaktive Abfrage: Spark bietet das Spark SQL-Modul , das SQL-Abfragen unterstützt . Benutzer können Standard-SQL-Anweisungen für interaktive Abfragen und umfangreiche Datenanalysen verwenden.
Die Verwendung von Spark in Kangaroo Cloud
In der Offline-Entwicklungsplattform Kangaroo Cloud Stack bieten wir drei Möglichkeiten zur Nutzung von Spark:
● Erstellen Sie Spark SQL-Aufgaben
Benutzer können ihre eigene Geschäftslogik direkt implementieren, indem sie SQL schreiben. Diese Methode ist derzeit die am weitesten verbreitete Methode zur Verwendung von Spark auf der Offline-Datenstapelplattform und auch die am häufigsten empfohlene Methode.
● Erstellen Sie eine Spark-Jar-Aufgabe
Benutzer müssen die Scala- oder Java-Sprache verwenden, um Geschäftslogik auf IDEA zu implementieren, dann das Projekt kompilieren und verpacken, das resultierende Jar-Paket auf die Offline-Plattform hochladen, dann beim Erstellen einer Spark-Jar-Aufgabe auf dieses Jar-Paket verweisen und schließlich die Aufgabe einfach senden Gehen Sie zum geplanten Lauf.
Für Anforderungen, die mit SQL nur schwer zu erreichen oder auszudrücken sind, oder wenn Benutzer andere tiefere Anforderungen haben, bieten Spark-Jar-Aufgaben Benutzern zweifellos eine flexiblere Möglichkeit, Spark zu verwenden.
● Erstellen Sie PySpark-Aufgaben
Benutzer können den entsprechenden Python-Code direkt schreiben . In unserem Kundenstamm gibt es etliche Kunden, für die neben SQL möglicherweise Python die Hauptsprache ist. Insbesondere für Benutzer mit bestimmten Datenanalyse- und Algorithmusgrundlagen führen sie häufig eine tiefere Analyse der verarbeiteten Daten durch. Zu diesem Zeitpunkt sind PySpark-Aufgaben natürlich die beste Wahl.
Spark spielt eine wichtige Rolle in der Offline-Entwicklungsplattform Kangaroo Cloud Data Stack . Daher haben wir viele interne Optimierungen an Spark vorgenommen, um es Kunden bequemer zu machen, Aufgaben mit Spark zu übermitteln. Wir haben auch einige auf Spark basierende Tools entwickelt, um die Funktionalität der gesamten Offline-Entwicklungsplattform für den Datenstapel zu verbessern.
Darüber hinaus spielt Spark auch im Data-Lake-Szenario eine sehr wichtige Rolle. Das integrierte Lake- und Warehouse-Modul von Kangaroo Cloud unterstützt bereits zwei große Datenseen, Iceberg und Hudi. Benutzer können Spark zum Lesen und Schreiben von Lake-Tabellen verwenden. Die unterste Ebene der Lake-Tabellenverwaltung wird auch durch die Verwendung von Spark zum Aufrufen verschiedener gespeicherter Prozeduren implementiert.
Im Folgenden wird die in Kangaroo Cloud vorgenommene Optimierung sowohl von der Engine-Seite als auch von Spark selbst erläutert.
Motorseitige Optimierung
Die Funktionen der internen Engine von Kangaroo Cloud werden hauptsächlich zum Senden von Aufgaben, zum Erfassen des Aufgabenstatus, zum Erfassen von Aufgabenprotokollen, zum Stoppen von Aufgaben, zur Syntaxüberprüfung usw. verwendet. Wir haben jeden Funktionspunkt in unterschiedlichem Maße optimiert. Im Folgenden finden Sie eine kurze Einführung anhand von zwei Beispielen.
Die Übermittlungsgeschwindigkeit von Spark on Yarn wurde verbessert
Mit der kontinuierlichen Entwicklung und Verbesserung neuer Funktionen des Spark-Plug-Ins auf der Engine-Seite nimmt auch die Zeit zu, die die Engine für die Übermittlung von Spark-Aufgaben benötigt. Daher muss der Code für die Übermittlung von Spark-Aufgaben optimiert werden Verkürzen Sie die Zeit für die Übermittlung von Spark-Aufgaben. Verbessern Sie die Benutzererfahrung.
Zu diesem Zweck haben wir die folgende Arbeit für einige gängige Konfigurationsdateien wie core-site.xml, Yarn-site.xml, keytab file, spark-sql-application.jar usw. durchgeführt Wenn Sie eine Aufgabe übermitteln, müssen Sie sie von herunterladen. Der Server lädt diese Konfigurationsdateien herunter und übermittelt sie. Nach der Optimierung muss die obige Datei nur einmal heruntergeladen werden, wenn der Client SparkYarnClient initialisiert wird, und dann auf den angegebenen HDFS-Pfad hochgeladen werden. Die anschließende Übermittlung von Spark-Aufgaben muss nur über Parameter an den entsprechenden HDFS-Pfad angegeben werden. Auf diese Weise wird die Übermittlungszeit jeder Spark-Aufgabe erheblich verkürzt.
In der neuen Version des Datenstapels beurteilen wir für temporäre Abfragen auch die Komplexität des auszuführenden SQL anhand benutzerdefinierter Regeln und senden das weniger komplexe SQL an die auf der Engine-Seite gestartete SparkSQLEngine, um den Vorgang zu beschleunigen. Diese interne SparkSQLEngine wurde in der Vergangenheit nur zur Syntaxüberprüfung verwendet, übernimmt aber jetzt auch einen Teil der SQL-Ausführungsfunktion, und SparkSQLEngine kann Ressourcen entsprechend der Gesamtlaufsituation auch dynamisch erweitern und verkleinern, um eine effektive Ressourcennutzung zu erreichen.
Grammatik Überprüfung
In älteren Datenstack-Versionen sendet die Engine zur Syntaxüberprüfung von SQL zunächst die SQL an den Spark Thrift Server. Dieser Spark Thrift Server wird im lokalen Modus bereitgestellt und nicht nur zur Syntaxüberprüfung verwendet. Alle Metadaten auf anderen Plattformen werden durch Senden von SQL zur Ausführung an diesen Spark Thrift Server abgerufen. Da diese Methode große Nachteile hat, haben wir einige Optimierungen vorgenommen. Eine Spark-Aufgabe wird im lokalen Modus auf der Engine-Seite gestartet. Bei der Syntaxüberprüfung wird die SQL nicht mehr an den Spark Thrift-Server gesendet. Stattdessen wird intern eine SparkSession verwaltet, um die Syntaxüberprüfung direkt durchzuführen.
Obwohl diese Methode keine starke Verbindung mit dem externen Spark Thrift-Server erfordert, übt sie einen gewissen Druck auf die Planungskomponente aus und auch die Gesamtkomplexität der Engine-Plugins wird während des Implementierungsprozesses stark zunehmen.
Um die oben genannten Probleme zu optimieren, haben wir eine weitere Optimierung vorgenommen. Wenn die Planungskomponente gestartet wird, sendet sie eine Spark-Aufgabe SparkSQLEngine an Yarn. Es kann als Remote-Spark-Thrift-Server verstanden werden, der auf Yarn ausgeführt wird. Die Engine-Seite überwacht jederzeit den Gesundheitszustand der SparkSQLEngine . Auf diese Weise sendet die Engine bei jeder Syntaxüberprüfung SQL über JDBC an SparkSQLEngine zur Syntaxüberprüfung.
Durch die oben genannte Optimierung ist die Offline-Entwicklungsplattform vom Spark Thrift Server entkoppelt. EasyManager muss keinen zusätzlichen Spark Thrift Server bereitstellen, wodurch die Bereitstellung einfacher wird. Es ist nicht erforderlich, auf der Planungsseite einen Spark-residenten Prozess im lokalen Modus aufrechtzuerhalten. Es ebnet auch den Weg für die interaktive Abfrageverbesserung von Spark SQL-Aufgaben auf der Offline-Entwicklungsplattform.
Die Entkopplung der Offline-Entwicklungsplattform vom von EasyManager bereitgestellten Spark Thrift Server bietet folgende Vorteile:
· Kann die Koexistenz mehrerer Spark-Cluster und mehrerer Versionen wirklich realisieren
· Mit der EasyManager-Standardbereitstellung kann Spark Thrift Server entfernt und die Belastung für den Betrieb und die Wartung an vorderster Front verringert werden
· Die Überprüfung der Spark SQL-Syntax wird einfacher, SparkContext muss nicht zwischengespeichert werden, wodurch die Ressourcennutzung der Engine reduziert wird
Spark-Funktionsoptimierung
Im Laufe der Geschäftsentwicklung stellen wir fest, dass der Open-Source-Spark Spark in einigen Szenarien nicht über entsprechende funktionale Implementierungen verfügt. Aus diesem Grund haben wir weitere neue Plug-Ins auf Basis des Open-Source-Sparks entwickelt, um funktionale Anwendungen des Datenstapels zu unterstützen.
Missionsdiagnostik
Zuerst haben wir die Metriksenke von Spark verbessert. Spark stellt intern verschiedene Senken bereit, darunter auch CSVSink, JmxSink, MetricsServlet, GraphiteSink, Slf4jSink, StatsdSink usw. PrometheusServlet wurde nach Spark3.0 ebenfalls hinzugefügt, diese können jedoch unsere Anforderungen nicht erfüllen.
Bei der Entwicklung der Aufgabendiagnosefunktion müssen wir die internen Indikatoren von Spark auf einheitliche Weise an PushGateway übertragen, und der Prometheus-Server ruft die Indikatoren regelmäßig von PushGateway ab. Durch Aufrufen der von Prometheus bereitgestellten Abfrageschnittstelle können wir schließlich die internen Indikatoren abfragen Indikatoren von Spark in nahezu Echtzeit.

Aber Spark implementiert keine sinkenden internen Indikatoren für PushGateway. Aus diesem Grund haben wir das Spark-Prometheus-Sink-Plug-In hinzugefügt und PrometheusPushGatewaySink angepasst, um interne Spark-Indikatoren an PushGateway zu übertragen.
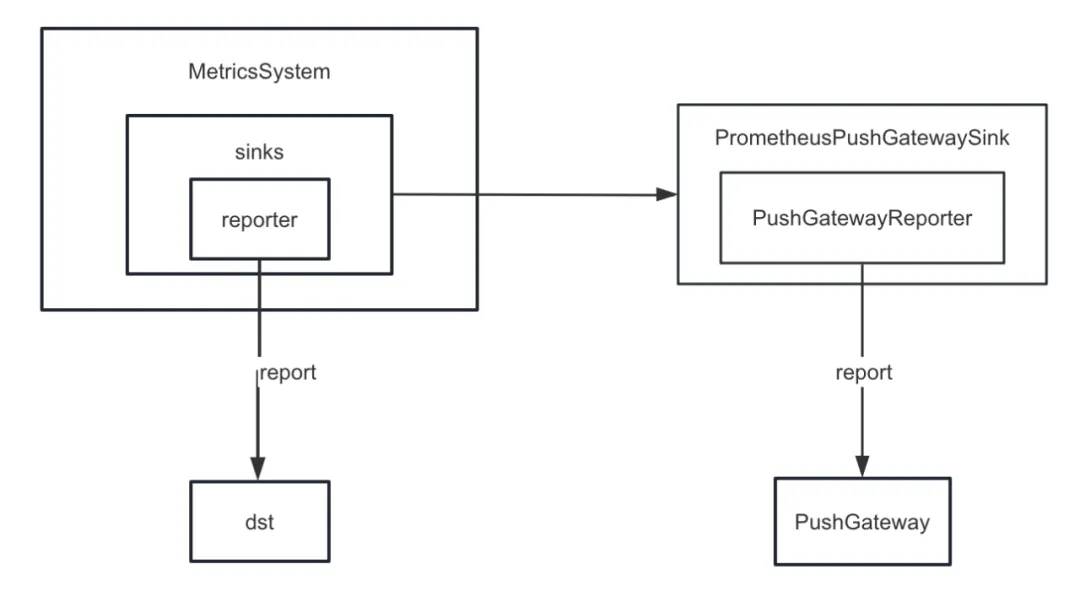
Darüber hinaus haben wir auch einen neuen Indikator angepasst, um den Ausführungsfortschritt der temporären Abfrageanzeige von Spark SQL zu beschreiben. Konkrete Schritte sind wie folgt:
· Fügen Sie einen Indikator hinzu, um den Fortschritt von Offline-Aufgaben zu beschreiben, indem Sie JobProgressSource anpassen , und registrieren Sie den Indikator im Indikatorverwaltungssystem im internen Verwaltungssystem von Spark
· Passen Sie den JobProgressListener an und registrieren Sie den JobProgressListener beim ListenerBus im internen Verwaltungssystem von Spark. Die Logik der onJobStart-Methode von JobProgressListener besteht darin, die Anzahl aller Aufgaben unter dem aktuellen Job zu berechnen. Die Logik der onTaskEnd -Methode besteht darin, den aktuellen Offline-Aufgabenfortschritt zu berechnen und zu aktualisieren Die onJobEnd-Methode besteht darin, den aktuellen Fortschritt der Offline-Aufgabe zu berechnen und zu aktualisieren, nachdem jeder Job abgeschlossen ist
Herstellen einer Verbindung zur kommerziellen Version des Hadoop-Clusters
Da die Zahl der Kangaroo Cloud-Kunden steigt, variieren auch deren Umgebungen. Einige Kunden verwenden die Open-Source-Version von Hadoop-Clustern, und eine beträchtliche Anzahl von Kunden verwendet HDP, CDH, CDP, TDH usw. Wenn wir eine Verbindung zu den Clustern dieser Kunden herstellen, muss die Entwicklungsseite häufig neue Anpassungen vornehmen, und die Betriebs- und Wartungsseite muss bei jeder Bereitstellung und Aktualisierung zusätzliche Parameter konfigurieren oder andere zusätzliche Vorgänge ausführen.
Nehmen wir als Beispiel HDP: Wenn wir eine Verbindung zu HDP herstellen, verwenden wir Spark2.3, das mit HDP geliefert wird. Außerdem müssen wir einige Parameter auf der Betriebs- und Wartungsseite hinzufügen und alle Jar-Pakete von Spark verschieben, die mit HDP geliefert werden um Verzeichnis anzugeben. Diese Vorgänge führen tatsächlich zu Verwirrung und Problemen bei Betrieb und Wartung. Verschiedene Arten von Clustern müssen unterschiedliche Betriebs- und Wartungsdokumente verwalten, und der Bereitstellungsprozess ist auch fehleranfälliger. Und wir haben tatsächlich funktionale Verbesserungen und Fehlerbehebungen am Spark-Quellcode vorgenommen. Wenn Sie den mit HDP gelieferten Spark verwenden, können Sie nicht alle Vorteile unseres intern gepflegten Spark nutzen.
Um die oben genannten Probleme zu lösen, wurde unser interner Spark an bestehende und gängige Publisher im bestehenden Markt angepasst. Mit anderen Worten: Unser interner Spark kann auf allen verschiedenen Hadoop-Clustern ausgeführt werden. Auf diese Weise müssen Betrieb und Wartung unabhängig von der Art des verbundenen Hadoop-Clusters nur denselben Spark bereitstellen, was den Druck der Betriebs- und Wartungsbereitstellung erheblich verringert. Noch wichtiger ist, dass Kunden unsere interne stabile Spark-Version direkt nutzen können, um mehr neue Funktionen und größere Leistungsverbesserungen zu genießen.
Spark3.2 neue Funktionen – AQE
In älteren Data Stack-Versionen ist die Spark-Standardversion 2.1.3. Später haben wir die Spark-Version auf 2.4.8 aktualisiert. Ab Data Stack 6.0 kann auch Spark 3.2 verwendet werden. Hier konzentrieren wir uns auf AQE , das auch die wichtigste neue Funktion in Spark3.x ist.
AQE-Übersicht
Vor Spark3.2 war AQE standardmäßig deaktiviert. Sie müssen spark.sql.adaptive.enabled auf true setzen, um AQE zu aktivieren. Nach Spark3.2 ist AQE standardmäßig aktiviert. Solange die Aufgabe während des Betriebs die Auslösebedingungen von AQE erfüllt, können Sie die von AQE bereitgestellte Optimierung genießen.
Es ist zu beachten, dass die Optimierung von AQE nur in der Shuffle-Phase erfolgt. Wenn der Shuffle-Vorgang nicht am laufenden Prozess von SQL beteiligt ist, spielt AQE keine Rolle, selbst wenn der Wert von spark.sql.adaptive.enabled ist WAHR. Genauer gesagt wird AQE nur wirksam, wenn der physische Ausführungsplan einen Austauschknoten oder eine Unterabfrage enthält.
Während des Betriebs sammelt AQE die Informationen der in der Shuffle-Map-Phase generierten Zwischendateien, sammelt Statistiken zu diesen Informationen und passt den optimierten logischen Plan und den Spark-Plan, die noch nicht ausgeführt wurden, dynamisch basierend auf den vorhandenen Regeln an, wodurch das Original geändert wird SQL-Anweisung. Laufzeitoptimierung.
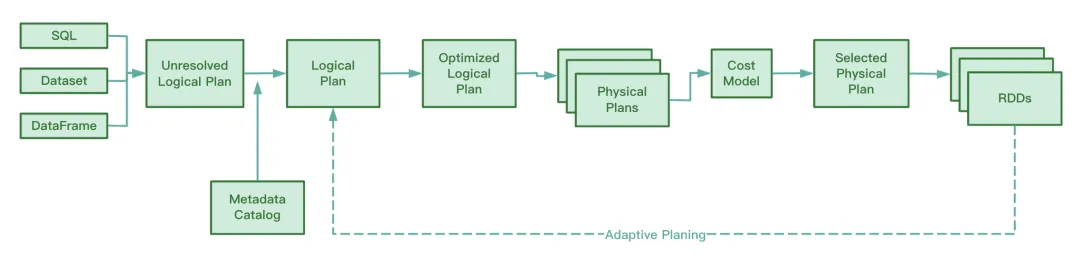
Dem Spark-Quellcode nach zu urteilen, umfasst AQE die folgenden vier Optimierungsregeln:

Wir wissen, dass RBO SQL basierend auf einer Reihe von Regeln optimiert, einschließlich Prädikat-Pushdown, Spaltenbereinigung, ständigem Ersetzen usw. Diese statischen Regeln selbst wurden in Spark integriert. Wenn Spark SQL ausführt, werden diese Regeln einzeln auf SQL angewendet.
AQE-Vorteile
Diese Funktion von CBO ist erst nach Spark2.2 verfügbar. Im Vergleich zu RBO kombiniert CBO die statistischen Informationen der Tabelle und wählt basierend auf diesen statistischen Informationen und dem Kostenmodell einen optimierten Ausführungsplan aus.
CBO unterstützt jedoch nur Tabellen, die im Hive Metastore registriert sind. CBO unterstützt keine Dateien wie Parquet und Orc, die in verteilten Dateisystemen gespeichert sind. Wenn der Hive-Tabelle außerdem Metadateninformationen fehlen, kann CBO beim Sammeln von Statistiken keine Statistiken erfassen, was zu einem Ausfall von CBO führen kann.
Ein weiterer Nachteil von CBO besteht darin, dass CBO ANALYZE TABLE COMPUTE STATISTICS ausführen muss, um vor der Optimierung statistische Informationen zu sammeln. Wenn diese Anweisung während der Ausführung auf eine große Tabelle stößt, ist dies zeitaufwändiger und die Erfassungseffizienz ist gering.
Ob CBO oder RBO, es handelt sich um statische Optimierungen. Wenn sich nach der Übermittlung des physischen Ausführungsplans das Datenvolumen und die Datenverteilung während der Ausführung der Aufgabe ändern, optimiert CBO den vorhandenen physischen Ausführungsplan nicht.
Im Gegensatz zu CBO und RBO analysiert AQE während des laufenden Prozesses die während des Shuffle-Map-Prozesses generierten Zwischendateien und passt den logischen Ausführungsplan und den physischen Ausführungsplan, die noch nicht mit der Ausführung begonnen haben, dynamisch an und optimiert sie im Vergleich zum statisch optimierten CBO Im Vergleich zu RBO kann durch die AQE-Verarbeitung ein optimierter physischer Ausführungsplan erzielt werden .
AQE drei Hauptmerkmale
● Automatische Partitionszusammenführung
Der Shuffle-Prozess ist in zwei Stufen unterteilt: Map-Stufe und Reduce-Stufe. In der Reduce-Stufe werden die in der Map-Stufe generierten temporären Zwischendateien zum entsprechenden Executor gezogen. Wenn die von der Map-Stufe verarbeiteten Daten sehr ungleichmäßig sind, gibt es viele Tatsächlich gibt es nur wenige Schlüssel, die Daten können nach der Verarbeitung eine große Anzahl kleiner Dateien bilden.
Um die obige Situation zu vermeiden, können Sie die automatische Partitionszusammenführungsfunktion von AQE aktivieren, um zu vermeiden, dass zu viele Reduzierungsaufgaben gestartet werden, um die kleinen Dateien abzurufen, die in der Map-Phase generiert wurden.
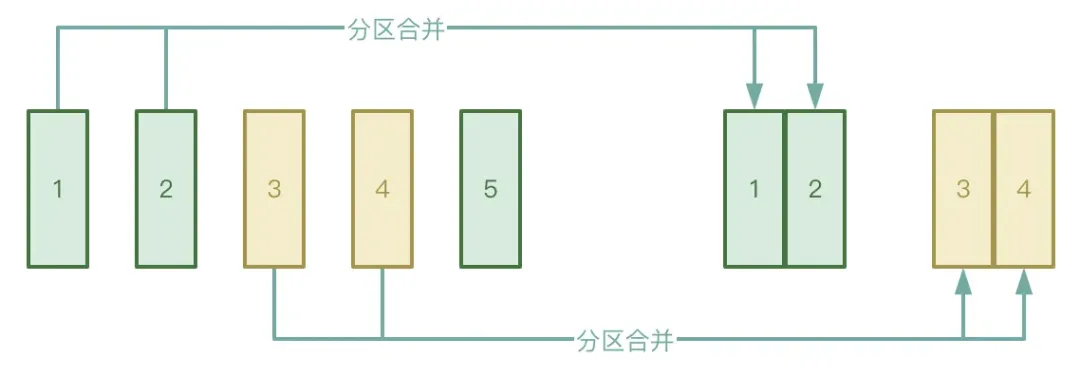
● Automatische Verarbeitung von Datenverzerrungen
Das Anwendungsszenario besteht hauptsächlich aus Datenverknüpfungen. Wenn ein Datenversatz auftritt, kann AQE die verzerrte Partition automatisch erkennen und die verzerrte Partition gemäß bestimmten Regeln aufteilen. Derzeit wird in Spark3.2 die automatische Datenversatzverarbeitung sowohl für SortMergeJoin als auch für ShuffleHashJoin unterstützt.
● Anpassung der Strategie beitreten
AQE wird Hash Join und Sort Merge Join dynamisch auf Broadcast Join herabstufen.
Wir wissen, dass der Grad der Parallelität bestimmt wird, sobald eine Spark-Aufgabe ausgeführt wird. In der Shuffle-Map-Stufe ist die Parallelität beispielsweise die Anzahl der Partitionen; in der Shuffle-Reduction-Stufe ist die Parallelität der Wert von spark.sql.shuffle.partitions, der standardmäßig 200 ist. Wenn die Datenmenge während der Ausführung der Spark-Aufgabe kleiner wird, wodurch die Größe der meisten Partitionen kleiner wird, führt dies zu einer Ressourcenverschwendung, wenn noch so viele Threads gestartet werden, um den kleinen Datensatz zu verarbeiten.
Während des Ausführungsprozesses führt AQE Partitionen automatisch zusammen, basierend auf den temporären Zwischenergebnissen, die nach dem Mischen generiert wurden, und unter bestimmten Bedingungen durch Anwenden der CoalesceShufflePartitions-Regeln und Kombinieren der vom Benutzer bereitgestellten Parameter, wodurch die Anzahl der Reduzierer tatsächlich angepasst wird. Ursprünglich würde ein Reduzierungsthread nur die Daten einer verarbeiteten Partition abrufen. Jetzt wird ein Reduzierungsthread entsprechend der tatsächlichen Situation die Daten mehrerer Partitionen abrufen, was die Verschwendung von Ressourcen reduzieren und die Effizienz der Aufgabenausführung verbessern kann. Downloadadresse „Industry Indicator System White Paper“: https://www.dtstack.com/resources/1057?src=szsm
Download-Adresse „Dutstack Product White Paper“: https://www.dtstack.com/resources/1004?src=szsm
Downloadadresse „Data Governance Industry Practice White Paper“: https://www.dtstack.com/resources/1001?src=szsm
Wenn Sie mehr über Big-Data-Produkte, Branchenlösungen und Kundenbeispiele erfahren oder sich beraten lassen möchten, besuchen Sie die offizielle Website von Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Ich habe beschlossen, Open-Source-Hongmeng aufzugeben . Wang Chenglu, der Vater von Open-Source-Hongmeng: Open-Source-Hongmeng ist die einzige Architekturinnovations- Industriesoftwareveranstaltung im Bereich Basissoftware in China – OGG 1.0 wird veröffentlicht, Huawei steuert den gesamten Quellcode bei Google Reader wird vom „Code-Scheißberg“ getötet Fedora Linux 40 wird offiziell veröffentlicht Ehemaliger Microsoft-Entwickler: Windows 11-Leistung ist „lächerlich schlecht“ Ma Huateng und Zhou Hongyi geben sich die Hand, um „Groll zu beseitigen“ Namhafte Spielefirmen haben neue Vorschriften erlassen : Hochzeitsgeschenke für Mitarbeiter dürfen 100.000 Yuan nicht überschreiten Ubuntu 24.04 LTS offiziell veröffentlicht Pinduoduo wurde wegen unlauteren Wettbewerbs zu einer Entschädigung von 5 Millionen Yuan verurteilt