Die neueste Fähigkeit zur Bilderzeugung, die das KI-Modell demonstriert, übertrifft die Erwartungen der Menschen bei weitem. Es kann Bilder mit erstaunlichen visuellen Effekten direkt auf der Grundlage von Textbeschreibungen erzeugen. Der Betriebsmechanismus dahinter scheint sehr mysteriös und magisch, aber er beeinflusst die Art und Weise, wie Menschen schaffen Art. Weg.
Die neueste Fähigkeit zur Bilderzeugung, die das KI-Modell demonstriert, übertrifft die Erwartungen der Menschen bei weitem. Es kann Bilder mit erstaunlichen visuellen Effekten direkt auf der Grundlage von Textbeschreibungen erzeugen. Der Betriebsmechanismus dahinter scheint sehr mysteriös und magisch, aber er beeinflusst die Art und Weise, wie Menschen schaffen Art. Weg.
Die Veröffentlichung von Stable Diffusion stellt einen Meilenstein in der Entwicklung der KI-Bildgenerierung dar. Es kommt der Bereitstellung eines nutzbaren Hochleistungsmodells für die Öffentlichkeit gleich. Die erzeugte Bildqualität ist nicht nur sehr hoch, sie läuft schnell, sondern auch geringer Ressourcen- und Speicherbedarf. .
Ich glaube, dass jeder, der die KI-Bilderzeugung ausprobiert hat, wissen möchte, wie es funktioniert. Dieser Artikel wird das Geheimnis enthüllen, wie Stable Diffusion für Sie funktioniert.

Stabile Diffusion umfasst hinsichtlich der Funktion hauptsächlich zwei Aspekte:
1) Seine Kernfunktion besteht darin, Bilder nur basierend auf Texteingabeaufforderungen als Eingabe zu generieren (text2img);
2) Sie können es auch verwenden, um Bilder basierend auf Textbeschreibungen zu ändern (d. h. Eingabe als Text + Bild).

Im Folgenden werden Abbildungen verwendet, um die Komponenten von Stable Diffusion, ihre Interaktion miteinander und die Bedeutung der Bilderzeugungsoptionen und -parameter zu erläutern.
Stabile Diffusionskomponente
Stabile Diffusion ist ein System, das aus mehreren Komponenten und Modellen besteht, nicht ein einzelnes Modell.
Wenn wir das Modell als Ganzes betrachten, können wir feststellen, dass es eine Textverständniskomponente enthält, um Textinformationen in eine numerische Darstellung zu übersetzen, um die semantischen Informationen im Text zu erfassen.

Obwohl wir das Modell noch aus der Makroperspektive analysieren und es später weitere Modelldetails geben wird, können wir auch grob spekulieren, dass es sich bei diesem Text-Encoder um ein spezielles Transformer-Sprachmodell handelt (insbesondere den Text-Encoder des CLIP-Modells ) .
Die Eingabe des Modells ist eine Textzeichenfolge und die Ausgabe ist eine Liste von Zahlen, die zur Darstellung jedes Wortes/Tokens im Text verwendet werden, d. h. jedes Token wird in einen Vektor umgewandelt.
Diese Informationen werden dann an den Bildgenerator übermittelt, der ebenfalls mehrere Komponenten enthält.

Der Bildgenerator besteht im Wesentlichen aus zwei Stufen:
1. Ersteller von Bildinformationen
Diese Komponente ist das exklusive Geheimrezept von Stable Diffusion und viele seiner Leistungssteigerungen im Vergleich zu früheren Modellen werden hier erzielt.
Diese Komponente führt mehrere Schritte aus, um Bildinformationen zu generieren, wobei Schritte auch Parameter in der Stable Diffusion-Schnittstelle und -Bibliothek sind und in der Regel standardmäßig auf 50 oder 100 eingestellt sind .
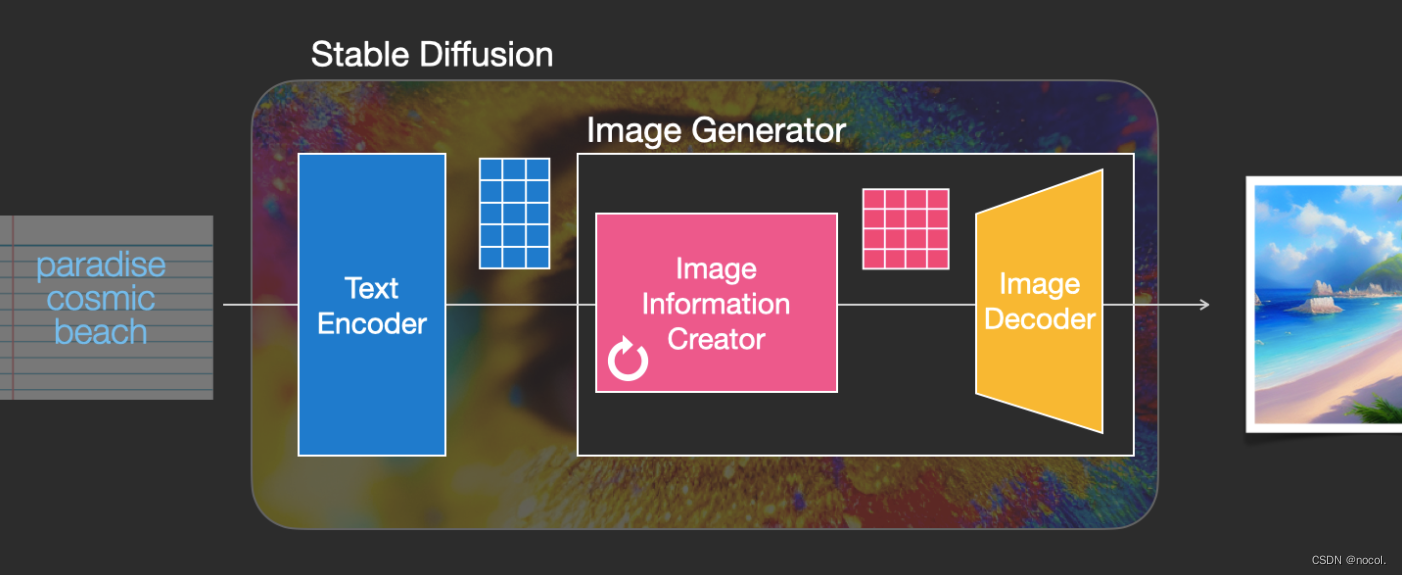
Der Bildinformationsersteller arbeitet vollständig im Bildinformationsraum (oder Latentraum), eine Funktion, die ihn schneller laufen lässt als andere Diffusionsmodelle, die im Pixelraum arbeiten; technisch gesehen besteht diese Komponente aus einem neuronalen UNet-Netzwerk und einem Planungsalgorithmus .
Das Wort Diffusion beschreibt, was während des internen Betriebs dieser Komponente geschieht, d. h. die Informationen werden Schritt für Schritt verarbeitet und schließlich wird von der nächsten Komponente (dem Bilddecoder) ein qualitativ hochwertiges Bild erzeugt.
2. Bilddecoder
Der Bilddecoder zeichnet ein Bild basierend auf den vom Bildinformationsersteller erhaltenen Informationen, und der gesamte Prozess wird nur einmal ausgeführt , um das endgültige Pixelbild zu erzeugen.

Wie Sie sehen, enthält Stable Diffusion insgesamt drei Hauptkomponenten , von denen jede über ein unabhängiges neuronales Netzwerk verfügt:
1) Clip Text wird für die Textkodierung verwendet.
Eingabetext
Ausgabe: 77 Token-Einbettungsvektoren, von denen jeder 768 Dimensionen enthält
2) UNet + Scheduler verarbeitet/verbreitet Informationen schrittweise im (latenten) Informationsraum.
Eingabe: Texteinbettung und ein anfängliches mehrdimensionales Array von Rauschen (strukturierte Liste von Zahlen, auch Tensor genannt).
Ausgabe: ein Array verarbeiteter Informationen
3) Autoencoder Decoder , ein Decoder, der die verarbeitete Informationsmatrix verwendet, um das endgültige Bild zu zeichnen.
Eingabe: verarbeitete Informationsmatrix mit Dimensionen (4, 64, 64)
Ausgabe: Ergebnisbild, jede Dimension ist (3, 512, 512), also (rot/grün/blau, Breite, Höhe)

Was ist Diffusion?
Diffusion ist ein Prozess, der in der rosafarbenen Bildinformationserstellungskomponente in der Abbildung unten stattfindet. Der Prozess umfasst die Token-Einbettung, die den Eingabetext darstellt, und die zufällige anfängliche Bildinformationsmatrix (auch Latent genannt). Dieser Prozess muss ebenfalls verwendet werden Bilddecoder zum Zeichnen der Informationsmatrix des endgültigen Bildes.

Der gesamte laufende Prozess erfolgt Schritt für Schritt und bei jedem Schritt werden weitere relevante Informationen hinzugefügt.
Um ein intuitiveres Gefühl für den gesamten Prozess zu bekommen, können Sie die zufällige latente Matrix zur Hälfte betrachten und beobachten, wie sie in visuelles Rauschen umgewandelt wird, wobei eine visuelle Inspektion durch den Bilddecoder durchgeführt wird.

Der gesamte Diffusionsprozess umfasst mehrere Schritte, von denen jeder auf der Grundlage der eingegebenen latenten Matrix arbeitet und eine weitere latente Matrix generiert , um den „Eingabetext“ und die „visuellen Informationen“, die aus dem Modellbildsatz erhalten wurden, besser anzupassen.

Durch die Visualisierung dieser latenten Daten können Sie sehen, wie diese Informationen bei jedem Schritt addiert werden.
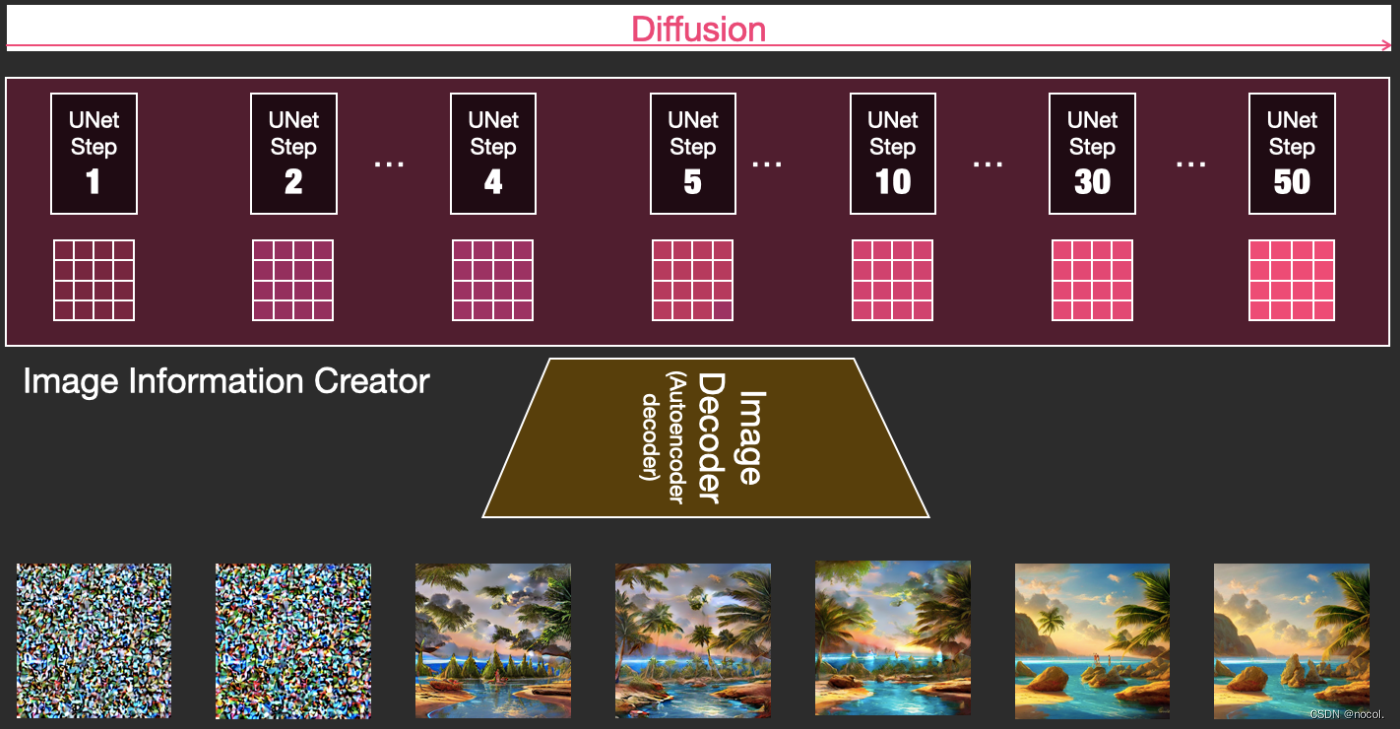
Der gesamte Prozess ist von Grund auf neu, was ziemlich aufregend aussieht.
https://jalammar.github.io/images/stable-diffusion/diffusion-steps-all-loop.webm
Besonders interessant sieht der Prozessübergang zwischen den Schritten 2 und 4 aus, als würden sich die Umrisse des Bildes aus dem Rauschen abzeichnen.
Wie Diffusion funktioniert
Ein Diffusionsmodell ist ein generatives Modell, mit dem Daten generiert werden, die den Trainingsdaten ähneln. Einfach ausgedrückt funktionieren Diffusionsmodelle, indem sie iterativ Gaußsches Rauschen hinzufügen, um die Trainingsdaten zu „verfälschen“, und dann lernen, wie man das Rauschen entfernt, um die Daten wiederherzustellen.
Ein Standarddiffusionsmodell hat zwei Hauptprozesse: Vorwärtsdiffusion und Rückwärtsdiffusion.
In der Vorwärtsdiffusionsstufe wird das Bild durch allmähliche Einführung von Rauschen zerstört, bis das Bild zu völlig zufälligem Rauschen wird.
In der Rückdiffusionsphase wird eine Reihe von Markov-Ketten verwendet, um das Vorhersagerauschen schrittweise zu entfernen und die Daten aus dem Gaußschen Rauschen wiederherzustellen.
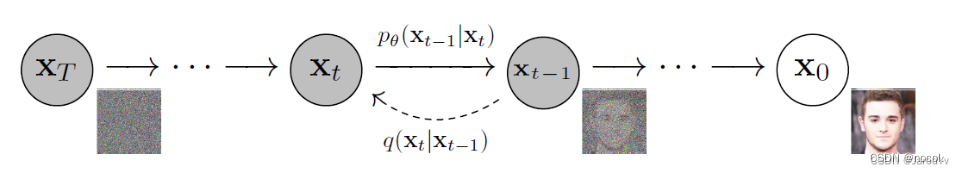
Markov-Kette des Vorwärts- (Rückwärts-)Diffusionsprozesses von Proben, der durch langsames Hinzufügen (Entfernen) von Rauschen erzeugt wird (Bildnachweis: Jonathan Ho, Ajay Jain, Pieter Abbeel. 2020)
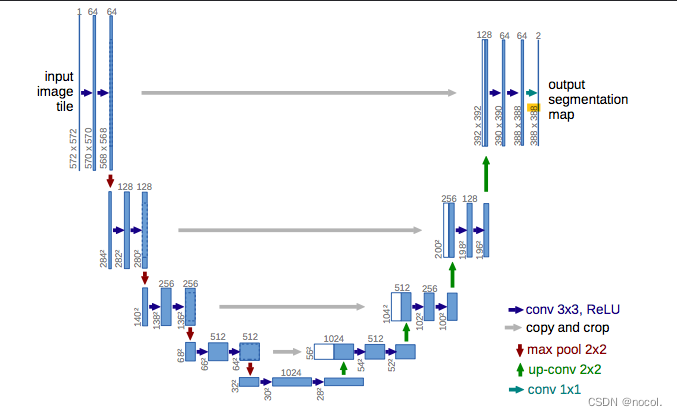
Zur Rauschschätzung und -entfernung wird am häufigsten U-Net verwendet. Die Architektur dieses neuronalen Netzwerks ähnelt dem Buchstaben U, daher der Name. U-Net ist ein vollständig verbundenes Faltungs-Neuronales Netzwerk, was es für die Bildverarbeitung sehr nützlich macht. Das Merkmal von U-Net besteht darin, dass es ein Bild als Eintrag nehmen und durch Reduzierung der Stichproben eine niedrigdimensionale Darstellung dieses Bildes finden kann, wodurch es besser für die Verarbeitung und Suche wichtiger Attribute geeignet ist und das Bild dann durch Vergrößerung wiederhergestellt wird Probenahme.
Konkret handelt es sich bei der sogenannten Rauschentfernung um die Transformation vom Zeitrahmen t zum Zeitrahmen t − 1, wobei t ein beliebiger Zeitrahmen zwischen t 0 (kein Rauschen) und t_{max} (vollständiges Rauschen) ist. Die Transformationsregeln sind:
- Geben Sie ein Bild im Zeitrahmen t ein, und in diesem Zeitrahmen weist das Bild ein bestimmtes Rauschen auf.
- Verwenden Sie U-Net, um die Gesamtlärmmenge vorherzusagen.
- Dann wird „ein Teil“ des Gesamtrauschens aus dem Bild des Zeitrahmens t entfernt und man erhält das Bild des Zeitrahmens t − 1 mit weniger Rauschen.

Mathematisch gesehen ist es sinnvoller, diese obige Methode T-mal durchzuführen, als zu versuchen, das gesamte Rauschen zu eliminieren. Durch die Wiederholung dieses Vorgangs wird das Rauschen nach und nach entfernt und wir erhalten ein „saubereres“ Bild. Bei Bildern mit Rauschen fügen wir beispielsweise dem Ausgangsbild vollständiges Rauschen hinzu und entfernen es dann iterativ, um ein Bild ohne Rauschen zu erzeugen. Der Effekt ist besser als das direkte Entfernen von Rauschen aus dem Originalbild.
In den letzten Jahren haben Diffusionsmodelle eine herausragende Leistung bei Bilderzeugungsaufgaben gezeigt und GANs bei vielen Aufgaben wie der Bildsynthese ersetzt. Da das Diffusionsmodell in der Lage ist, die semantische Struktur der Daten beizubehalten, ist es nicht vom Schemakollaps betroffen.
Allerdings gibt es einige Schwierigkeiten bei der Implementierung eines Diffusionsmodells. Da für die Vorhersage alle Markov-Zustände im Speicher gehalten werden müssen, bedeutet dies, dass mehrere Instanzen großer tiefer Netzwerke im Speicher gehalten werden müssen, was dazu führt, dass das Diffusionsmodell sehr viel Speicher verbraucht. Darüber hinaus können Diffusionsmodelle in unmerklich feinkörnigen Komplexitäten in Bilddaten stecken bleiben, was dazu führt, dass die Trainingszeiten zu lang werden (Tage bis Monate). Paradoxerweise ist die feinkörnige Bilderzeugung einer der Hauptvorteile von Diffusionsmodellen und wir können uns diesem „süßen Ärgernis“ nicht entziehen. Da das Diffusionsmodell sehr hohe Rechenanforderungen hat, erfordert das Training sehr viel Speicher und Leistung, was es den meisten Forschern unmöglich machte, das Modell in die Realität umzusetzen.
Stabile Verbreitung
Das größte Problem beim Diffusionsmodell besteht darin, dass es sowohl zeitlich als auch wirtschaftlich äußerst „teuer“ ist. Die Entstehung einer stabilen Diffusion soll die oben genannten Probleme lösen. Wenn wir ein Bild mit der Größe 1024 × 1024 x 1024 erzeugen möchten, verwendet U-Net Rauschen mit der Größe 1024 x 1024 x 1024 und generiert dann das Bild daraus. Der Rechenaufwand für eine einstufige Diffusion ist hier sehr groß, ganz zu schweigen von der Notwendigkeit, mehrmals zu iterieren, bis 100 % erreicht sind. Eine Lösung besteht darin, ein großes Bild zum Training in mehrere Bilder mit kleinerer Auflösung aufzuteilen und dann ein zusätzliches neuronales Netzwerk zu verwenden, um ein Bild mit größerer Auflösung zu erzeugen (Superauflösungsdiffusion).
Das 2021 veröffentlichte Latent Diffusion-Modell bietet einen anderen Ansatz. Das Modell der latenten Diffusion operiert nicht direkt im Bild, sondern im latenten Raum. Durch die Codierung der Originaldaten in einen kleineren Raum kann U-Net der niedrigdimensionalen Darstellung Rauschen hinzufügen und entfernen (das Kernprinzip der stabilen Diffusion ist die latente Diffusion).
Die Kernidee der Verwendung von Diffusionsmodellen zur Bilderzeugung basiert immer noch auf vorhandenen leistungsstarken Computer-Vision-Modellen. Solange ein ausreichend großer Datensatz eingegeben wird, können diese Modelle beliebig komplexe Operationen lernen.
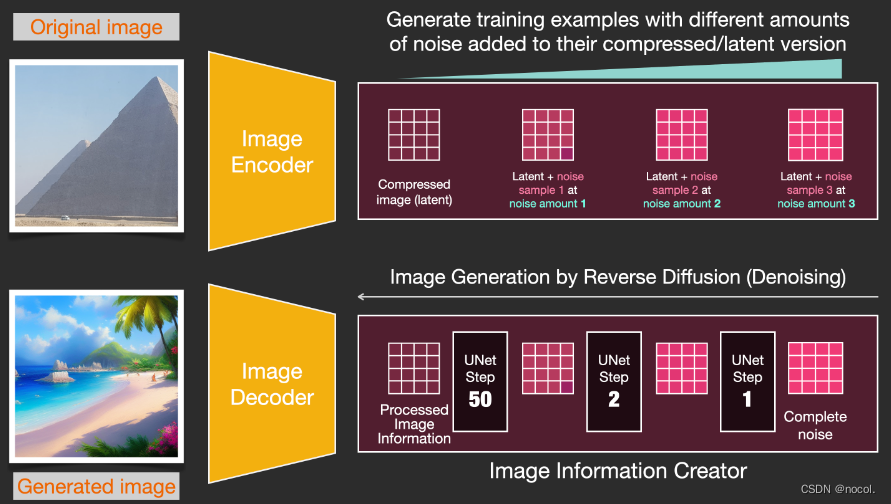
Angenommen, wir haben bereits ein Bild , erzeugen etwas Rauschen, fügen es dem Bild hinzu und behandeln das Bild dann als Trainingsbeispiel.
Trainingsbeispiele werden generiert, indem Rauschen erzeugt und dem Trainingsdatensatz eine bestimmte Menge Rauschen hinzugefügt wird (Vorwärtsdiffusion).
Mit derselben Operation kann eine große Anzahl von Trainingsbeispielen generiert werden, um die Kernkomponenten im Bilderzeugungsmodell zu trainieren.

Das obige Beispiel zeigt eine Reihe auswählbarer Rauschpegel, die vom Originalbild (Stufe 0, kein Rauschen) bis zum gesamten hinzugefügten Rauschen (Stufe 4) reichen, sodass Sie leicht steuern können, wie viel Rauschen dem Bild hinzugefügt wird.
Wir können diesen Prozess also auf Dutzende Schritte verteilen und Dutzende Trainingsbeispiele für jedes Bild im Datensatz generieren.

Basierend auf dem obigen Datensatz können wir einen Geräuschprädiktor mit hervorragender Leistung trainieren . Jeder Trainingsschritt ähnelt dem Training anderer Modelle. Wenn der Rauschprädiktor in einer bestimmten Konfiguration ausgeführt wird, kann er Bilder erzeugen.
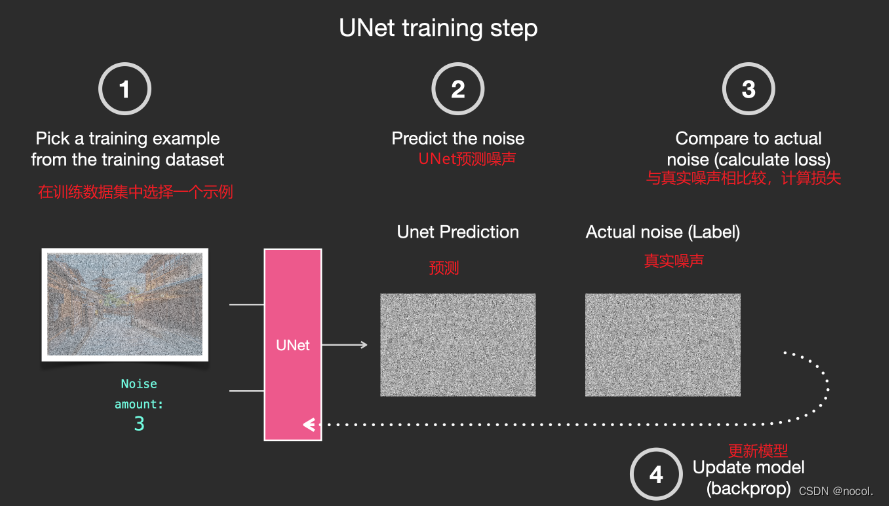
Entfernen Sie Rauschen und zeichnen Sie Bilder
Ein trainierter Rauschprädiktor kann ein Bild mit zusätzlichem Rauschen entrauschen und auch die Menge des hinzugefügten Rauschens vorhersagen.
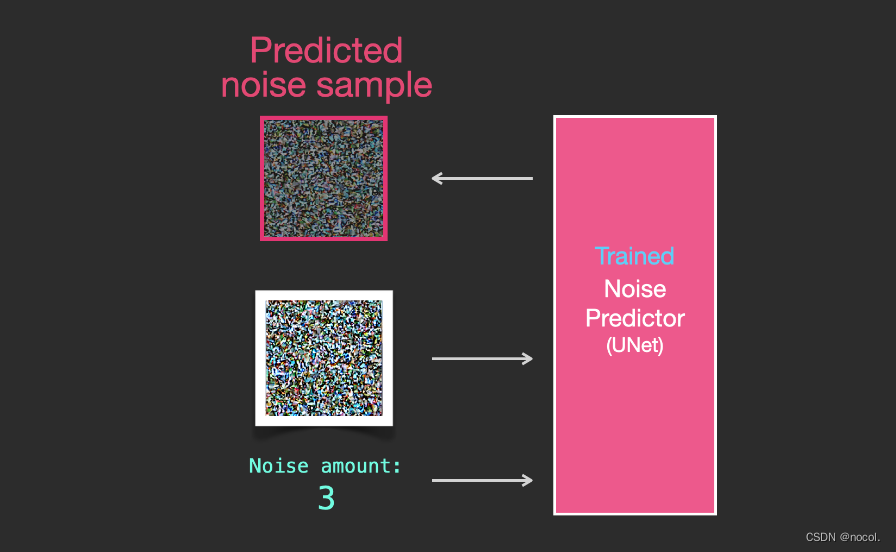
Da das Rauschen der Proben vorhersehbar ist, wird das endgültige Bild näher an dem Bild liegen, auf dem das Modell trainiert wurde, wenn das Rauschen vom Bild subtrahiert wird.
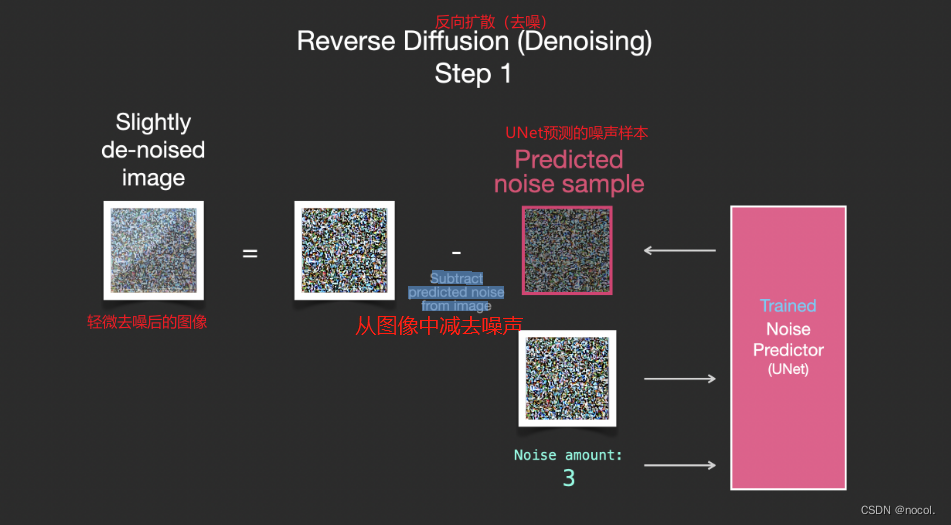
Das resultierende Bild ist kein exaktes Originalbild, sondern eine Verteilung, also die Anordnung der Pixel in der Welt. Beispielsweise ist der Himmel normalerweise blau, Menschen haben zwei Augen, Katzen haben spitze Ohren usw. Das erzeugte spezifische Bild Der Stil hängt vollständig vom Trainingsdatensatz ab.
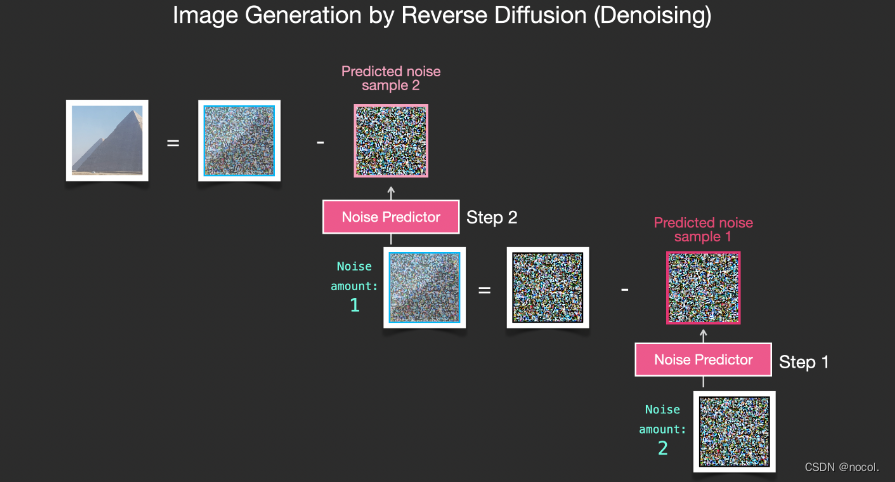
Nicht nur Stable Diffusion führt die Bilderzeugung durch Rauschunterdrückung durch, sondern auch DALL-E 2 und das Imagen-Modell von Google.
Es ist wichtig zu beachten, dass der bisher beschriebene Diffusionsprozess keine Textdaten zur Generierung von Bildern verwendet . Wenn wir dieses Modell also einsetzen, kann es zwar gut aussehende Bilder generieren, aber der Benutzer hat keine Möglichkeit zu steuern, was generiert wird.
In den folgenden Abschnitten beschreiben wir, wie Sie bedingten Text in den Prozess integrieren, um die Art der vom Modell generierten Bilder zu steuern.
Beschleunigung: Verbreitung komprimierter Daten
Lantenter Raum
Latentraum ist einfach eine Darstellung komprimierter Daten. Unter Komprimierung versteht man den Prozess der Kodierung von Informationen mit weniger Bits als die ursprüngliche Darstellung. Beispielsweise verwenden wir einen Farbkanal (Schwarz, Weiß und Grau), um ein Bild darzustellen, das ursprünglich aus drei RGB-Primärfarben bestand. Zu diesem Zeitpunkt wird der Farbvektor jedes Pixels von 3 Dimensionen auf 1 Dimension geändert. Durch die Dimensionsreduzierung gehen einige Informationen verloren, aber in manchen Fällen ist die Dimensionsreduzierung keine schlechte Sache. Durch Dimensionsreduzierung können wir einige weniger wichtige Informationen herausfiltern und nur die wichtigsten Informationen behalten.
Angenommen, wir trainieren ein Bildklassifizierungsmodell über ein vollständig verbundenes Faltungs-Neuronales Netzwerk. Wenn wir sagen, dass das Modell lernt, meinen wir, dass es die spezifischen Eigenschaften jeder Schicht des neuronalen Netzwerks lernt, wie Kanten, Winkel, Formen usw. Wenn das Modell anhand von Daten (bereits vorhandenen Bildern) lernt, Das Bild wird zunächst verkleinert und dann auf die Originalgröße zurückgesetzt. Schließlich verwendet das Modell einen Decoder, um das Bild aus den komprimierten Daten zu rekonstruieren und dabei alle vorherigen relevanten Informationen zu lernen. Daher wird der Raum kleiner, um die wichtigsten Attribute zu extrahieren und beizubehalten. Aus diesem Grund eignet sich der latente Raum für Diffusionsmodelle.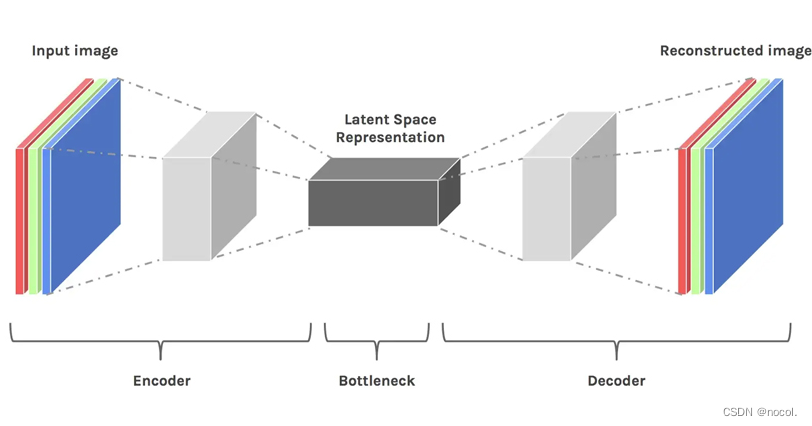
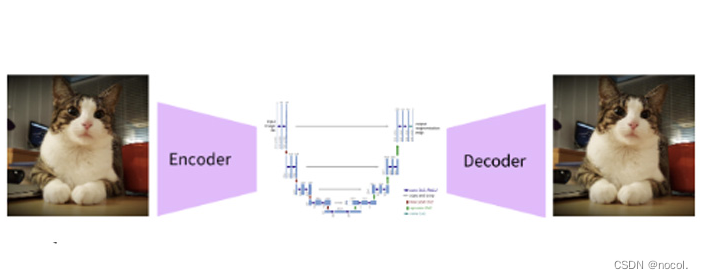
Bei jeder generativen Lernmethode gibt es zwei Hauptphasen: Wahrnehmungskomprimierung und semantische Komprimierung:
In der Lernphase der Wahrnehmungskomprimierung muss die Lernmethode hochfrequente Details entfernen, um die Daten in einer abstrakten Darstellung zu kapseln. Dieser Schritt ist notwendig, um eine stabile und robuste Darstellung der Umgebung zu erstellen. GANs zeichnen sich durch Wahrnehmungskomprimierung aus, die sie durch die Projektion hochdimensionaler redundanter Daten aus dem Pixelraum in einen Hyperraum des latenten Raums erreichen. Ein latenter Vektor im latenten Raum ist eine komprimierte Form des ursprünglichen Pixelbildes und kann das Originalbild effektiv ersetzen.
Genauer gesagt wird die Wahrnehmungskomprimierung mithilfe einer Auto-Encoder-Architektur erfasst. Der Encoder in einem Autoencoder projiziert hochdimensionale Daten in einen latenten Raum, und der Decoder stellt das Bild aus dem latenten Raum wieder her.
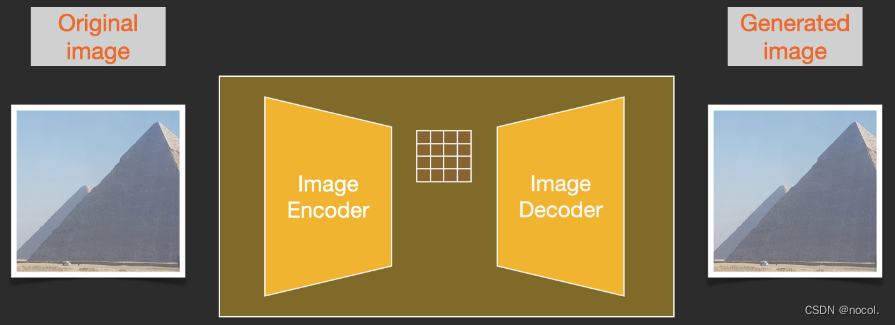
semantische Komprimierung
In der zweiten Lernstufe muss die Bilderzeugungsmethode in der Lage sein, die in den Daten vorhandene semantische Struktur zu erfassen. Diese konzeptionelle und semantische Struktur sorgt für die Erhaltung des Kontexts und der Wechselbeziehungen verschiedener Objekte im Bild. Transformer ist gut darin, semantische Strukturen in Texten und Bildern zu erfassen. Die Kombination der Generalisierungsfähigkeiten des Transformers und der Detailerhaltungsfähigkeiten des Diffusionsmodells bietet das Beste aus beiden Welten und bietet eine Möglichkeit, feinkörnige, hochdetaillierte Bilder zu erzeugen und gleichzeitig die semantische Struktur im Bild (den Transformer in) beizubehalten die UNet-Struktur hauptsächlich zur semantischen Komprimierung).
wahrgenommener Verlust
Autoencoder in latenten Diffusionsmodellen erfassen die Wahrnehmungsstruktur der Daten, indem sie sie in einen latenten Raum projizieren. Die Autoren des Artikels verwenden eine spezielle Verlustfunktion, um diesen Autoencoder zu trainieren, der als „Wahrnehmungsverlust“ bezeichnet wird. Diese Verlustfunktion stellt sicher, dass die Rekonstruktion auf die Bildmannigfaltigkeit beschränkt ist und reduziert die Unschärfe, die bei der Verwendung von Pixelraumverlusten (z. B. L1/L2-Verlusten) auftritt.

Um den Bilderzeugungsprozess zu beschleunigen, hat sich Stable Diffusion dafür entschieden, den Diffusionsprozess nicht auf dem Pixelbild selbst auszuführen, sondern ihn auf der komprimierten Version des Bildes auszuführen, was auch als „Departure to Latent Space“ bezeichnet wird das Papier.
Der gesamte Komprimierungsprozess, einschließlich der anschließenden Dekomprimierung und Zeichnung des Bildes, wird durch den Autoencoder abgeschlossen , der das Bild in den latenten Raum komprimiert und es dann nur noch mithilfe des Decoders anhand der komprimierten Informationen rekonstruiert.
Der Vorwärtsdiffusionsprozess wird auf komprimierten Latentdaten abgeschlossen und Rauschschnitte werden auf das Rauschen auf den Latentdaten und nicht auf das Pixelbild angewendet, sodass der Rauschprädiktor tatsächlich darauf trainiert ist, die komprimierte Darstellung (latent) vorherzusagen. Rauschen im Raum).

Der Vorwärtsprozess verwendet den Encoder im Autoencoder, um den Rauschprädiktor zu trainieren. Sobald das Training abgeschlossen ist, können Bilder durch Ausführen des umgekehrten Prozesses (Decoder im Autoencoder) generiert werden.
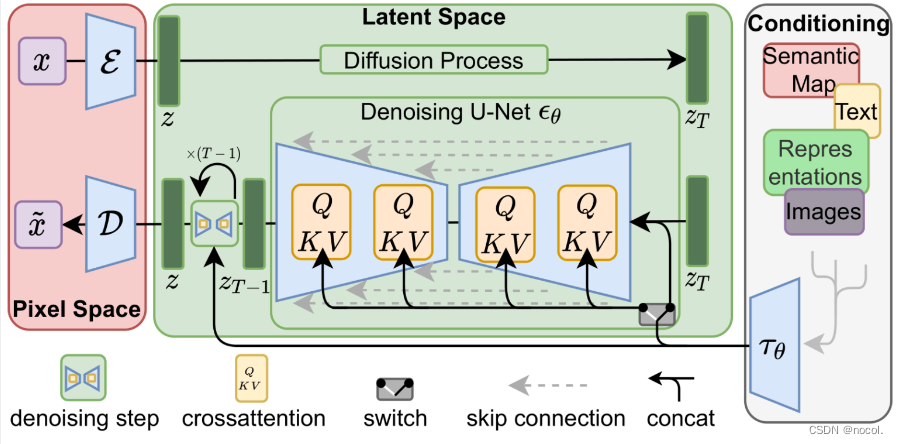
Die Vorwärts- und Rückwärtsprozesse werden unten dargestellt. Die Abbildung enthält auch eine Konditionierungskomponente zur Beschreibung der Textaufforderungen, die das Modell für das Bild generieren soll .

Text Encoder: Ein Transformer-Sprachmodell
Die Sprachverständniskomponente im Modell verwendet das Transformer-Sprachmodell, das Eingabetextaufforderungen in Token-Einbettungsvektoren umwandeln kann. Das veröffentlichte Stable Diffusion-Modell verwendet ClipText (ein GPT-basiertes Modell). In diesem Artikel wird der Einfachheit halber das BERT-Modell ausgewählt.
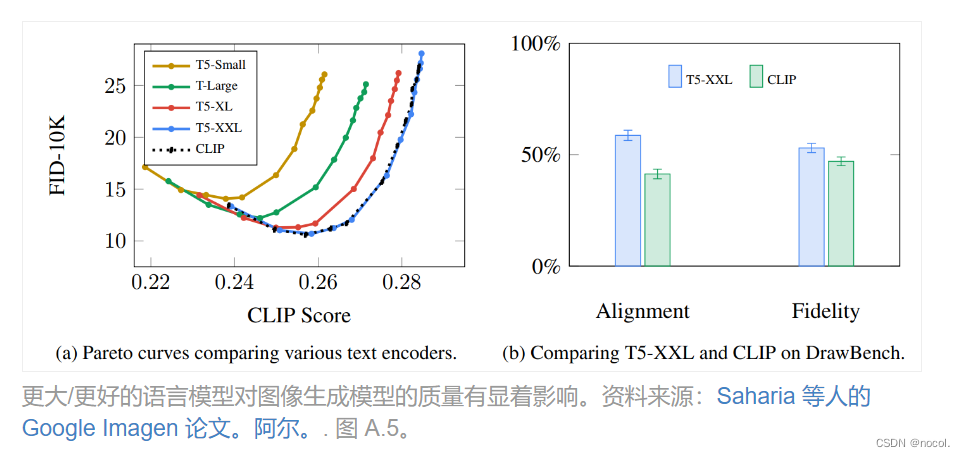
Die Experimente im Imagen-Artikel zeigen, dass ein größeres Sprachmodell mehr Bildqualitätsverbesserungen bringen kann als die Wahl einer größeren Bilderzeugungskomponente.
Das frühe Stable Diffusion-Modell verwendete das von OpenAI veröffentlichte vorab trainierte ClipText-Modell, in Stable Diffusion V2 wurde jedoch auf die neu veröffentlichte, größere CLIP-Modellvariante OpenClip umgestellt.
Wie wird CLIP trainiert?
Bei den von CLIP benötigten Daten handelt es sich um Bilder und deren Bildunterschriften. Der Datensatz enthält etwa 400 Millionen Bilder und Beschreibungen.

Der Datensatz wird aus Bildern aus dem Internet und dem entsprechenden „Alt“-Tag-Text zusammengestellt.
CLIP ist eine Kombination aus Bild-Encoder und Text-Encoder. Der Trainingsprozess kann vereinfacht werden, indem Bilder und Textbeschreibungen aufgenommen und zwei Encoder verwendet werden, um die Daten separat zu codieren.
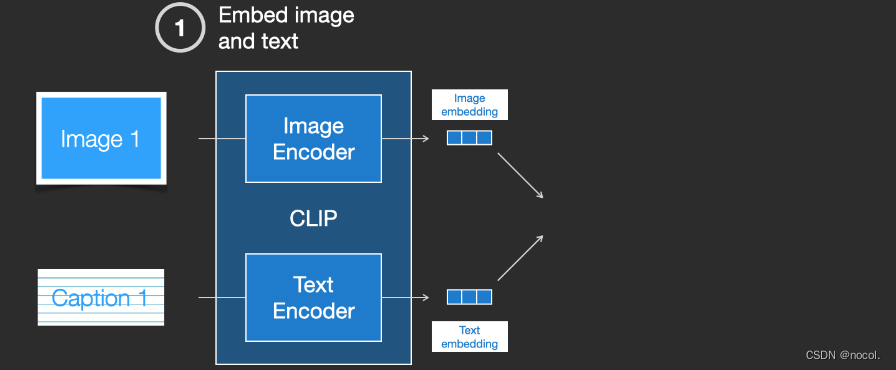
Die resultierenden Einbettungen werden dann mithilfe des Kosinusabstands verglichen . Zu Beginn des Trainings ist die Ähnlichkeit zwischen ihnen definitiv sehr gering, selbst wenn die Textbeschreibung und das Bild übereinstimmen.
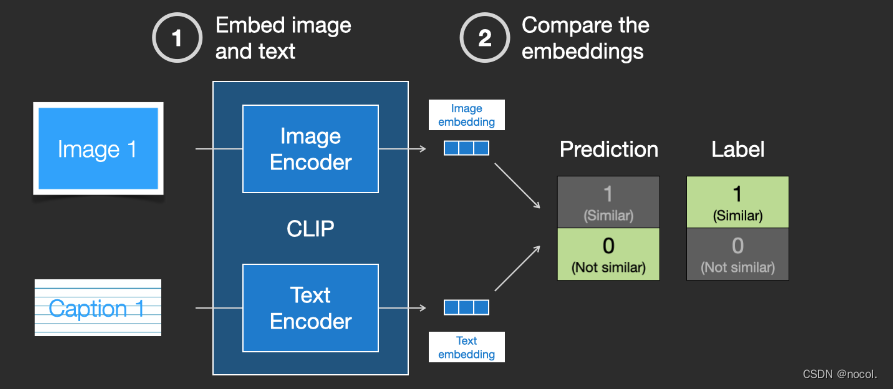
Da das Modell kontinuierlich aktualisiert wird, werden die Einbettungen, die der Encoder beim Codieren von Bildern und Text erhält, in den nachfolgenden Phasen allmählich ähnlich.
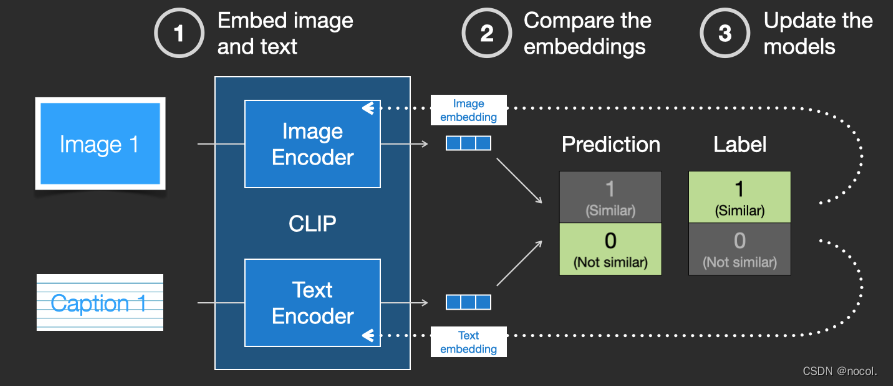
Indem wir diesen Vorgang im gesamten Datensatz wiederholen und einen Encoder mit einer großen Stapelgröße verwenden, können wir letztendlich einen Einbettungsvektor generieren, bei dem das Bild des Hundes dem Satz „Bild eines Hundes“ ähnelt.
Genau wie bei word2vec muss der Trainingsprozess auch negative Beispiele für nicht übereinstimmende Bilder und Bildunterschriften einbeziehen und das Modell muss ihnen niedrigere Ähnlichkeitswerte zuweisen.
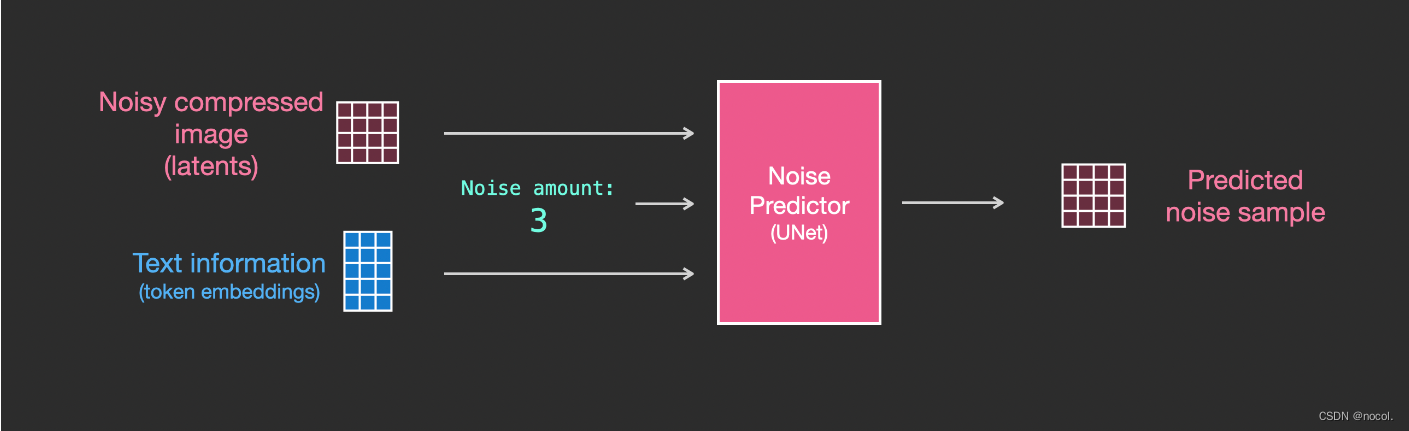
Textinformationen werden in den Bilderzeugungsprozess eingespeist:
Text-Bild-Synthese: In der Python-Implementierung können wir die neueste offizielle Implementierung mit LDM v4 verwenden, um Bilder zu generieren. Bei der Text-zu-Bild-Synthese verwendet das latente Diffusionsmodell das vorab trainierte CLIP-Modell 3, das universelle Transformer-basierte Einbettungen für mehrere Modalitäten wie Text und Bilder bereitstellt. Die Ausgabe des Transformer-Modells wird dann in die Python-API des latenten Diffusionsmodells namens „Diffusoren“ eingegeben, und einige Parameter können ebenfalls festgelegt werden (z. B. Anzahl der Diffusionsschritte, Zufallszahlen-Seed, Bildgröße usw.).
Um die Textkonditionierung als Teil des Bilderzeugungsprozesses zu integrieren, muss die Eingabe in den Rauschprädiktor so angepasst werden, dass sie Text ist .
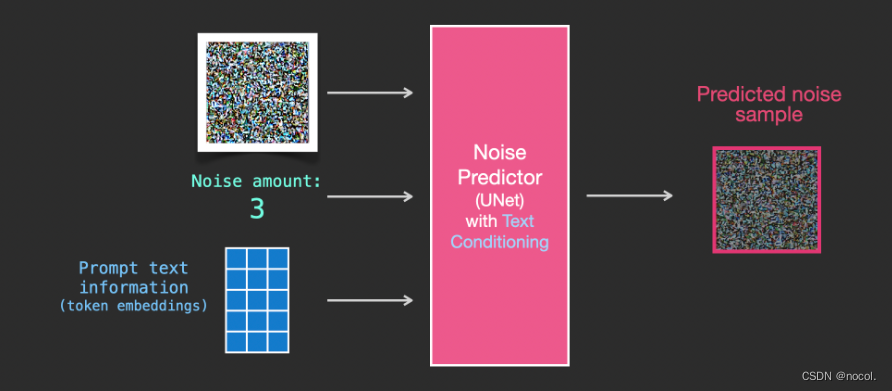
Alle Vorgänge werden im latenten Raum ausgeführt , einschließlich codiertem Text, Eingabebildern und Vorhersagerauschen.

Um besser zu verstehen, wie Text-Tokens in Unet verwendet werden, müssen Sie zunächst das Unet-Modell verstehen.
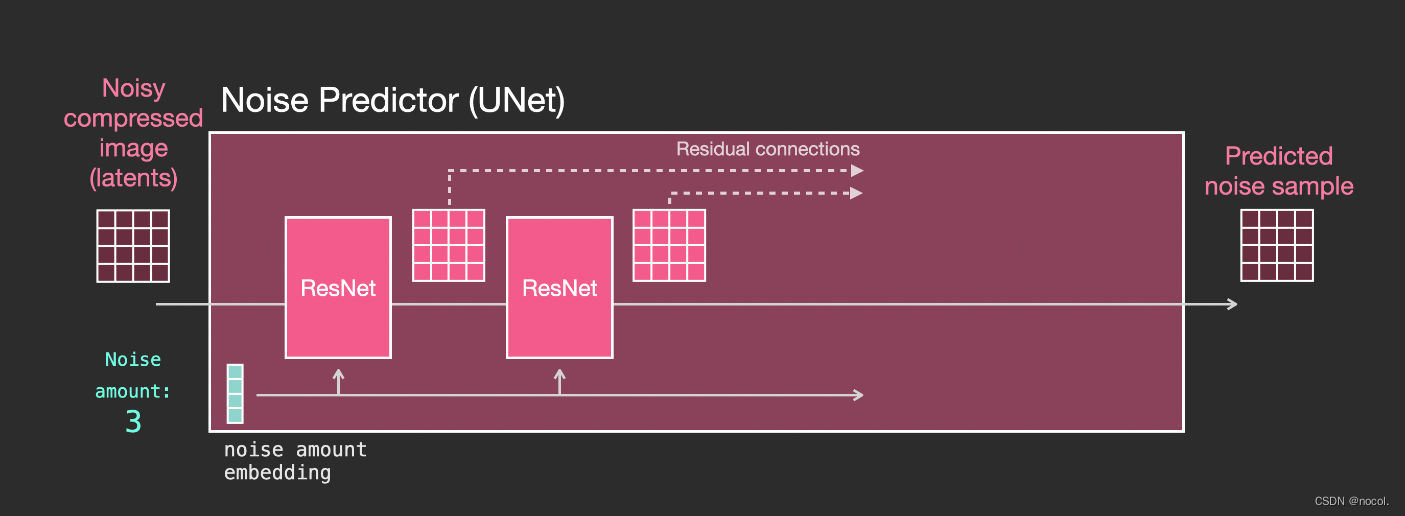
Ebenen im Unet-Lärmprädiktor (kein Text)
Ein Diffusions-Unit, das keinen Text verwendet. Seine Eingabe und Ausgabe sind wie folgt:
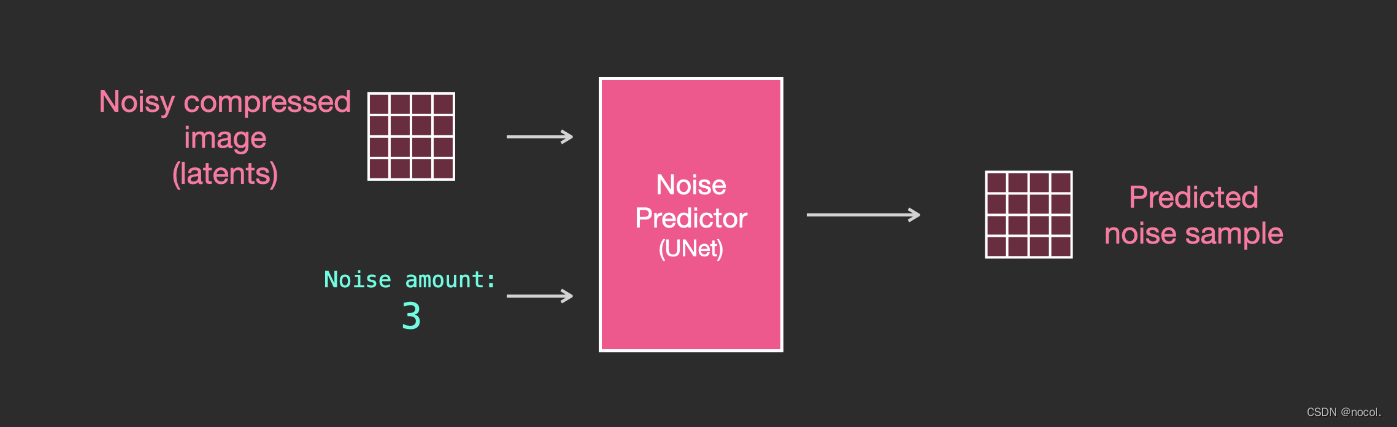
Im Inneren des Modells sehen Sie:
1. Die Schichten im Unet-Modell werden hauptsächlich zum Konvertieren von Latentdaten verwendet.
2. Jede Schicht verarbeitet die Ausgabe der vorherigen Schicht.
3. Bestimmte Ausgänge (über Restverbindungen) speisen sie in die Verarbeitung hinter dem Netzwerk ein
4. Konvertieren Sie Zeitschritte in Zeitschritt-Einbettungsvektoren, die in Ebenen verwendet werden können.
Ebenen im Unet-Lärmprädiktor (mit Text)
Nun gilt es, das bisherige System in eine Textversion umzuwandeln.
bedingte Verbreitung
Diffusionsmodelle sind bedingte Modelle, die auf Prioritäten basieren. Bei Bildgenerierungsaufgaben ist der Prior normalerweise Text, Bild oder semantische Karte. Um eine a priori latente Darstellung zu erhalten, muss man einen Transformator (z. B. CLIP) verwenden, um den Text/das Bild in den latenten Vektor τ\tauτ einzubetten. Daher hängt die endgültige Verlustfunktion nicht nur vom latenten Raum des Originalbilds ab, sondern auch von der latenten Einbettung der Bedingungen.
Die Hauptänderung besteht darin, Unterstützung für die Texteingabe (Begriff: Textkonditionierung) hinzuzufügen, indem eine Aufmerksamkeitsschicht zwischen ResNet-Blöcken hinzugefügt wird .
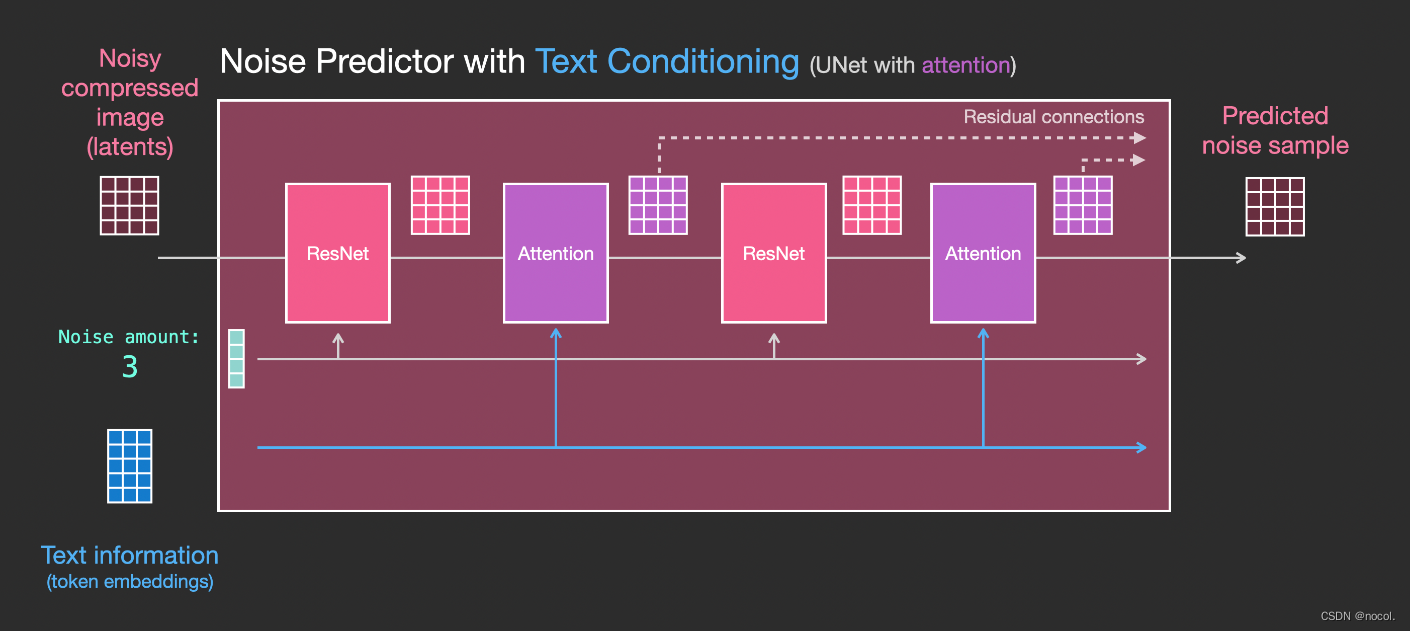
Es ist zu beachten, dass der ResNet-Block den Textinhalt nicht direkt sieht, sondern die latente Darstellung des Textes über die Aufmerksamkeitsschicht zusammenführt und dann der nächste ResNet die oberen Textinformationen in diesem Prozess nutzen kann.
Verweise:
https://jalammar.github.io/illustrated-stable-diffusion/
https://www.reddit.com/r/MachineLearning/comments/10dfex7/d_the_illustrated_stable_diffusion_video/