文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
- 读入文本
- 分词
- 建立字典,将每个词映射到一个唯一的索引(index)
- 将文本从词的序列转换为索引的序列,方便输入模型
使用示例:
text = "Mr. Chen doesn't agree with my suggestion." ####spaCy: import spacy nlp = spacy.load('en_core_web_sm') doc = nlp(text) print([token.text for token in doc]) ['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.'] ####NLTK: from nltk.tokenize import word_tokenize from nltk import data data.path.append('/home/kesci/input/nltk_data3784/nltk_data') print(word_tokenize(text)) ['Mr.', 'Chen', 'does', "n't", 'agree', 'with', 'my', 'suggestion', '.']
语言模型
一段自然语言文本可以看作是一个离散时间序列,给定一个长度为TT的词的序列w1,w2,…,wTw1,w2,…,wT,语言模型的目标就是评估该序列是否合理,即计算该序列的概率:
P(w1,w2,…,wT).P(w1,w2,…,wT).
N-gram语言模型
为了解决自由参数数目过多的问题,引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的n个词有关。基于上述假设的统计语言模型被称为N-gram语言模型。
随机采样
在随机采样中,每个样本是原始序列上任意截取的一段序列,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
import torch import random def data_iter_random(corpus_indices, batch_size, num_steps, device=None): # 减1是因为对于长度为n的序列,X最多只有包含其中的前n - 1个字符 num_examples = (len(corpus_indices) - 1) // num_steps # 下取整,得到不重叠情况下的样本个数 example_indices = [i * num_steps for i in range(num_examples)] # 每个样本的第一个字符在corpus_indices中的下标 random.shuffle(example_indices) def _data(i): # 返回从i开始的长为num_steps的序列 return corpus_indices[i: i + num_steps] if device is None: device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') for i in range(0, num_examples, batch_size): # 每次选出batch_size个随机样本 batch_indices = example_indices[i: i + batch_size] # 当前batch的各个样本的首字符的下标 X = [_data(j) for j in batch_indices] Y = [_data(j + 1) for j in batch_indices] yield torch.tensor(X, device=device), torch.tensor(Y, device=device)
相邻采样
在相邻采样中,相邻的两个随机小批量在原始序列上的位置相毗邻。
def data_iter_consecutive(corpus_indices, batch_size, num_steps, device=None): if device is None: device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') corpus_len = len(corpus_indices) // batch_size * batch_size # 保留下来的序列的长度 corpus_indices = corpus_indices[: corpus_len] # 仅保留前corpus_len个字符 indices = torch.tensor(corpus_indices, device=device) indices = indices.view(batch_size, -1) # resize成(batch_size, ) batch_num = (indices.shape[1] - 1) // num_steps for i in range(batch_num): i = i * num_steps X = indices[:, i: i + num_steps] Y = indices[:, i + 1: i + num_steps + 1] yield X, Y
循环神经网络
模型示意图:
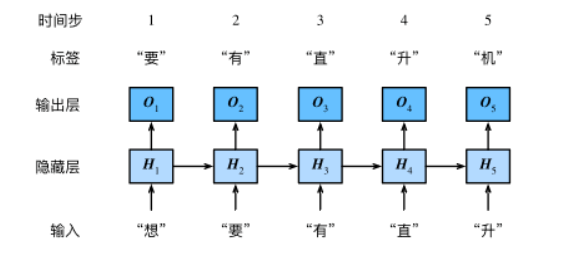
循环神经网络引入一个隐藏变量HH,用HtHt表示HH在时间步tt的值。HtHt的计算基于XtXt和Ht−1Ht−1,可以认为HtHt记录了到当前字符为止的序列信息,利用HtHt对序列的下一个字符进行预测。
扫描二维码关注公众号,回复:
9151048 查看本文章

循环神经网络的构造
def rnn(inputs, state, params): # inputs和outputs皆为num_steps个形状为(batch_size, vocab_size)的矩阵 W_xh, W_hh, b_h, W_hq, b_q = params H, = state outputs = [] for X in inputs: H = torch.tanh(torch.matmul(X, W_xh) + torch.matmul(H, W_hh) + b_h) Y = torch.matmul(H, W_hq) + b_q outputs.append(Y) return outputs, (H,)
解决循环神经网络梯度爆炸问题:梯度裁剪
裁剪梯度(clip gradient)是一种应对梯度爆炸的方法。假设我们把所有模型参数的梯度拼接成一个向量 g,并设裁剪的阈值是θ。裁剪后的梯度
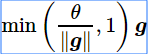
裁剪梯度代码:
def grad_clipping(params, theta, device): norm = torch.tensor([0.0], device=device) for param in params: norm += (param.grad.data ** 2).sum() norm = norm.sqrt().item() if norm > theta: for param in params: param.grad.data *= (theta / norm)
使用RNN模型进行预测:
def predict_rnn(prefix, num_chars, rnn, params, init_rnn_state, num_hiddens, vocab_size, device, idx_to_char, char_to_idx): state = init_rnn_state(1, num_hiddens, device) output = [char_to_idx[prefix[0]]] # output记录prefix加上预测的num_chars个字符 for t in range(num_chars + len(prefix) - 1): # 将上一时间步的输出作为当前时间步的输入 X = to_onehot(torch.tensor([[output[-1]]], device=device), vocab_size) # 计算输出和更新隐藏状态 (Y, state) = rnn(X, state, params) # 下一个时间步的输入是prefix里的字符或者当前的最佳预测字符 if t < len(prefix) - 1: output.append(char_to_idx[prefix[t + 1]]) else: output.append(Y[0].argmax(dim=1).item()) return ''.join([idx_to_char[i] for i in output])