分类概述
分类(Classification)是指自动对数据进行标注。人们在日常生活中通过经验划分类别。但是要依据一些规则手工地对互联网上的每一个页面进行分类,是不可能的。因此,基于计算机的高效自动分类技术成为人们解决互联网应用难题的迫切需求。与分类技术类似的是聚类,聚类不是将数据匹配到预先定义的标签集合,而是通过与其他数据相关的隐含结构自动的聚集为一个或多个类别。文本分类是数据挖掘和机器学习领域的一个重要研究方向。
分类是信息检索领域多年来一直研究的课题,一方面以搜索的应用为目的来提高有效性和某些情况下的效率;另一方面,分类也是经典的机器学习技术。在机器学习领域,分类是在有标注的预定义类别体系下进行,因此属于有监督的学习问题;相反聚类则是一种无监督的学习问题。
文本分类(Text Classification或Text Categorization,TC),或者称为自动文本分类(Automatic Text Categorization),是指计算机将载有信息的一篇文本映射到预先给定的某一类别或某几类别主题的过程。文本分类另外也属于自然语言处理领域。本文中文本(Text)和文档(Document)不加区分,具有相同的意义。
F. Sebastiani以如下数学模型描述文本分类任务:文本分类的任务可以理解为获得这样的一个函数Φ:D×C→{T,F},其中,D={d1,d2,…,d|D|} 表示需要进行分类的文档,C={c1,c2,…,c|C|} 表示预定义的分类体系下的类别集合,T值表示对于(dj,ci)来说 ,文档dj属于类ci,而F值表示对于(dj,ci)而言文档dj属于类ci 。也就是说,文本分类的目标就是要寻找一个有价值的函数映射,准确的完成D×C到T/F值的函数映射,这个映射过程本质上讲就是所谓的分类器。
文本分类的形式化定义如下:
设i = 1,…,M为文档集合里面的M篇文档, j = 1,…,N为预先定义的N个类别主题,可以给出这样一个分类结果矩阵C=(cij);其中,矩阵中某一元素cij表示第i篇文档与第j个类别的关系。也就是说,文本自动分类可以归结为确定上面矩阵C的每一个元素的值的过程;使用一个布尔量1或0,如果cij 的值为1,则表示文档i属于第j类,如果值为0,则文档i不能被分入类别j,即:

对于单类别的分类,即某篇文档只允许被分入一个类别中,我们可以增加限定条件,对于第j行( j = 1,…,N)的所有元素,必须满足:
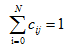
在实际应用中,根据预定义的类别不同,分类系统可以分两种:两类分类器和多类分类器。如果从文本的标注类别上来讲,文本分类可以又可以分为单标签和多标签两类。文本分类系统的任务简单的说:在预定义分类体系下,根据文本的内容相关性自动地判定文本与类别之间的关联。从数学角度来看,文本分类是一个函数映射过程,它将未标明类别的文本映射到预定义的类别,该映射可以是一一映射,也可以是一对多的映射,因为通常一篇文本可以同时关联到多个类别。
分类流程
文本分类系统可以简单的表示为如图2.1所示:

- 文本预处理模型(Text Preprocessing Model),
- 文本表示模型(Text Expressing Model),
- 特征选择模型( Feature Selection Model),
- 学习训练模型(Learning and Selection Model),
- 分类处理模型(Classification Processing Model),
- 性能评估模型(Performance Evaluation Model)。
多数情况下的监督型机器学习算法,学习训练模型仅需在分类预测前运行一次即可;性能评估模型主要起到评估训练模型学习效果,衡量分类精度的作用。
文本分类的一般流程如图所示:

数据采集
数据采集是文本我觉的基础,主要包括爬虫技术和页面处理。
爬虫技术
Web信息检索的第一步就是要抓取网络文档,爬虫就承担了解决这一问题的主要责任。爬虫有很多种类型,但最典型的就是网络爬虫。网络爬虫通过跟踪网页上的超链接来搜寻并下载新的页面。似乎听起来该过程比较简单,但是如何能够高效处理Web上出现的大量新页面,如何处理已抓取页面的更新页面,如何保持页面的最新性,这些问题都成为网络爬虫设计富有挑战的难题。网络爬虫抓取任务可以限定在一个比较小的范围内,例如一个公司,一个网站,或者一所大学的站点。主题网络爬虫与话题网络爬虫要采用分类技术来限制所搜寻页面属于同一主题类别。
页面处理
通过网络爬虫抓取的页面是最原始的Web页面,它们的格式多种多样,如HTML、XML、Adobe PDF、Microsoft Word等等。这些web页面含有大量的噪声数据,包括导航栏、广告信息、Web标签、超链接或者其他非内容格式数据等,这些数据几乎都成是阻碍文本下一步处理的因素。因此需要经过预处理去除上述噪音数据,将Web页面转化成为纯净统一的文本格式和元数据格式。Web关注内容过滤也是Web信息处理领域的一项热门研究课题。
另外一个普遍存在的页面处理问题是编码不一致。由于计算机发展、民族语言、国家地域的不同造成现在计算机存储数据采用许多种编码格式,例如ASCII、UTF-8、GBK、BIG5等等。在实际应用过程中,在对不同编码格式的文档进行深入处理之前,必须要保证对它们编码格式进行统一转换。
文本预处理
文本要转化成计算机可以处理的数据结构,就需要将文本切分成构成文本的语义单元。这些语义单元可以使句子、短语、词语或单个的字。本文无论对于中文还是英文文本,统一将最小语义单元称为“词组”。对于不同的语言来说处理有所区别,下面简述最常见的中文和英文文本的处理方式。
英文处理
英文文本的处理相对简单,每一个单词之间有空格或标点符号隔开。如果不考虑短语,仅以单词作为唯一的语义单元的话,处理英文单词切分相对简单,只需要分类多有单词,去除标点符号。英文还需要考虑的一个问题是大小写转换,一般认为大小写不具有不同的意义,这就要求将所有单词的字幕都转换成小写或大写。另外,英文文本预处理更为重要的问题是词根的还原,或称词干提取。词根还原的任务就是讲属于同一个词干(Stem)的派生词进行归类转化为统一形式。例如,把“computed”, “computer”, “computing”可以转化为“compute”。通过使用一个给定的词来代替一类中每一个元素,可以进一步增加类别与文档中的词之间匹配度。词根还原可以针对所有词进行,也可以针对少部分词进行或者不采用词根还原。针对所有词的词根还原可能导致分类结果的下降,这主要的原因或许是删除了不同形式单词所含有的形式意义。哪些词在哪些应用中应该词根还原尚不清楚。McCallum等人研究工作显示,词根还原可能有损于分类性能。
中文处理
相对于英文来说,中文的文本处理相对复杂。中文的字与字之间没有间隔,并且单个汉字具有的意义弱于词组。一般认为中文词语为最小的语义单元,当然词语可以由一个或多个汉字组成。中文文本分类首先要解决的难题就是中文分词技术,用特殊符号(例如空格符)将中文具有独立语义信息的语义单元分割开。中文分词是中文文本分类的前提条件。目前常用的中文分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。详细介绍见中文分词篇。
去停用词
停用词(Stop Word)是一类普遍纯在与文本中的常用词,并且脱离语境它们本身并不具有明显的意义。最常用的词是一些典型的功能词,这些词构成句子的结构,但对于描述文本所表述的意义几乎没有作用,并且容易造成统计偏差,影响机器学习效果。在英文中这词如:“the”、“of”、“for”、“with”、“to”等,在中文中如:“啊”、“了”、“并且”、“因此”等。由于这些词的用处太普遍,去除这些词,对于文本分类来说没有什么不利影响,相反可能改善机器学习效果。停用词去除组件的任务比较简单,只需从停用词表中剔除别定义为停用词的常用词就可以了。尽管停用词去除简单,含有潜在优势,但是停用词去除与词根还原具有同样的问题,定义停用词表中应该包含哪些词确是比较困难,一般科研中停用词表的规模为几百。
文本表示
文本通常表现为一个由文字或字符与标点符号组成的符号串,由字或字符组成词,由词组成短语,进而形成句子、段落、篇章结构。要使计算机能够有效地处理文本串,就必需找到一种理想的文本表示方法,这种表示形式要既能够真实的反应文本的内容又能区分不同文档。
向量空间模型(VSM,Vector Space Model)是目前文本处理应用领域使用最多且效果较好的文本表示法。VSM是20 世纪60年代末期由G. Salton等人提出的,最早用在SMART信息检索系统中。
定义:向量空间模型:给定文档D,如下
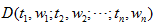
其中 tk 是组成文本的词元素, 1≤k≤n; wk 是词元素tk 的权重,或者说词在文本中的某种重要程度。
性质:向量空间模型满足以下两条性质:
a) 互异性:各词组元素间属于集合元素关系,即若i≠j ,则 ti≠tj ;
b) 无关性:各词组元素间无顺序关系和相互联系,即对于文本D,若i≠j ,交换ti 与tj 的位置,仍表示文档D。词组与词组之间不含任何关系。
可以把词组t1, t2,…,tn 看成n维坐标空间,而权重w1, w2,…,wn 为相应坐标值。因此,一个文本可以表示为一个n维向量。
特征选择
在向量空间模型中,文本可以选择字、词组、短语、甚至“概念”等多种元素表示。这些元素用来表征文本的性质,区别文本的属性,因此这些元素可以被称为文本的特征。在文本数据集上一般含有数万甚至数十万个不同的词组,如此庞大的词组构成的向量规模惊人,计算机运算非常困难。进行特征选择,对文本分类具有重要的意义。特征选择就是要选择那些最能表征文本含义的词组元素。特征选择不仅可以降低问题的规模,还有助于分类性能的改善。选取不同的特征对文本分类系统的性能有不同程度的影响。已提出的文本分类特征选择方法比较多,常用的方法有:文档频率(Document Frequency,DF)、信息增益(Information Gain,IG)、 校验(CHI)和互信息(Mutual Information,MI)等方法。另外特征抽取[36]也是一种特征降维技术,特征抽取通过将原始的特征进行变换运算,形成新的特征。详细内容见特征选择篇。
分类模型
文本分类模型主要分为:
- 规则模型;
- 概率模型;
- 几何学模型;
- 统计模型;
详细参见:
参考文献:
[1] 周志华.机器学习. 清华大学出版社,2016.
[2] 邱江涛,唐常杰,曾涛,刘胤田.关联文本分类的规则修正策略.计算机研究与发展,46(4):683- 688.
[3] 靖红芳,王斌,杨雅辉,徐燕.基于类别分布的特征选择框架.计算机研究与发展,46(9):1586-1593
[4] Sebastiani,F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34(1): 1-47.
[5]Lewis,D.,Schapire,R.,Callan,J.,Papka,R. Training algorithms for linear text classifiers. In: Proc. of the ACM SIGIR.
[6] Joachims,T. Text categorization with support vector machines: Learning with many relevant features In: Proc. of the Machine Learning: ECML’98, 10th European Conf. on Machine Learning.
[7] Lewis,D. A comparison of two learning algorithms for text categorization . In: Proc. of Symp. On Document Analysis and IR.