NLP相关基础概念
文档(document):是指一段单独的文本信息。可能是一则短信、一条推特、一份邮件、一本书、或者一首歌词。一般一个文档对应于一个观测值或一行数据。
词语(token):例如“今天天气真好”这个文档,是由今天,天气,真好三个单词组成的。token相当于机器学习中的特征(列)。
预料(corpus):文档的集合(预料大于等于一条文档)。这相当于我们要研究对象的所有文本数据。
(1)数据清洗:去除一切不相关的字符,比如清楚无关信息
正则表达式(re)
Sub:检查和替换
语法:
re.sub(pattern,repl,string)
参数:
pattern:正则中的模式字符串
repl:替换的字符串,也可为一个函数
string:要被查找替换的原始字符串

Findall:匹配的所有子串,并放回一个列表
语法:
findall(string[,pos[,endpos]])
参数:
string:带匹配的字符串
pos:指定字符串的起始位置,默认是0
endpos:指定字符串的结束位置,默认是字符串的长度

(2)中文分词:标记你的文本,将他们拆分为独立的词
中文中词语往往是信息载体的最小单位,字往往是没有明确含义的
和拉丁语系不同,亚洲语言是不用空格分开每个有意义的词的
因此需要一个工具去把完整的文本分解成粒度更细的词。jieba就是这样一个非常好用的中文工具,是以分词起家的,但是功能比分词要强大很多。
特点:
支持三种分词模式
①精确模式,试图将句子最精确地切开,适合文本分析。
②全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。
③搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
支持自定义字典
分词效果:
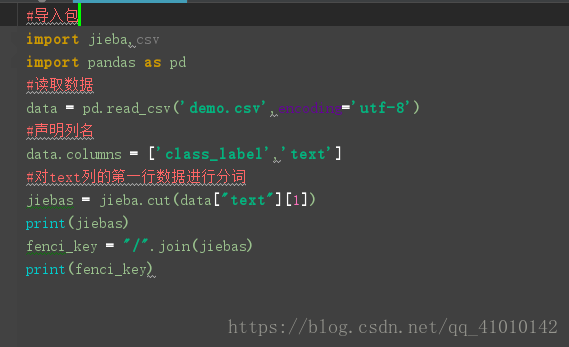
三种模式:

自定义字典:

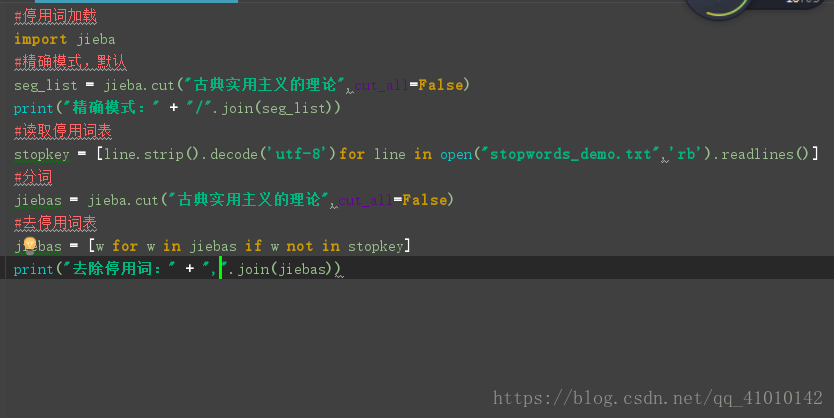
自定义去停用词表:
(3)文本特征表示和特征提取
首先我们要明白,计算机是不能从文本字符串中发现规律的。只有将字符串编码为计算机可以理解的数字,计算机才有可能发现文本中的规律。将每一个字符都编为一个独立的数字(例如ASCII码),这个过程叫做文本特征性表示。
离散表示:Set-of-words词集模型(只考虑词是否出现,不考虑出现的次数)

离散表示:Bag-of-words词袋模型(考虑出现次数)


