写在前面的话:每一个实例的代码都会附上相应的代码片或者图片,保证代码完整展示在博客中。最重要的是保证例程的完整性!!!方便自己也方便他人~欢迎大家交流讨论~
环境:Anaconda3(python3.5)
urllib库
使用urllib构建一个请求和响应模型
import urllib
strUrl="https://www.baidu.com/"
response=urllib.request.urlopen(strUrl)
print (response.read())运行返回:
runfile('F:/Python/SPIDER/1.py', wdir='F:/Python/SPIDER')
b'<html>\r\n<head>\r\n\t<script>\r\n\t\tlocation.replace(location.href.replace("https://","http://"));\r\n\t</script>\r\n</head>\r\n<body>\r\n\t<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>\r\n</body>\r\n</html>'这里有一个python3和python2的区别——
python2中是import urllib2,但是python3没有urllib2即使在cmd中pip3 install urllib2也无法安装 urllib2。
原因:python 3.X版本是不需要安装urllib2包的,urllib和urllib2包集合成在一个包了
那现在问题是:
在python3.x版本中,如何使用:urllib2.urlopen()?
答:
import urllib.request
response=urllib.request.urlopen(“http://www.baidu.com“)
post数据传送方式
import urllib
import urllib.request
import urllib.parse
myData={}
myData['key1']='value1'
myData['key2']='value2'
myNewData=urllib.parse.urlencode(myData).encode(encoding='UTF8')#转换格式
url="https://www.baidu.com"
req=urllib.request.Request(url,myNewData)#新建req变量表示一个请求
respon=urllib.request.urlopen(req)#新建respon变量表示对应req请求的一个响应
page=respon.read().decode("utf8")#让爬到的页面为Html代码
print(req)
print(page)其中没有page=respon.read().decode("utf8")时,你爬到的非常乱
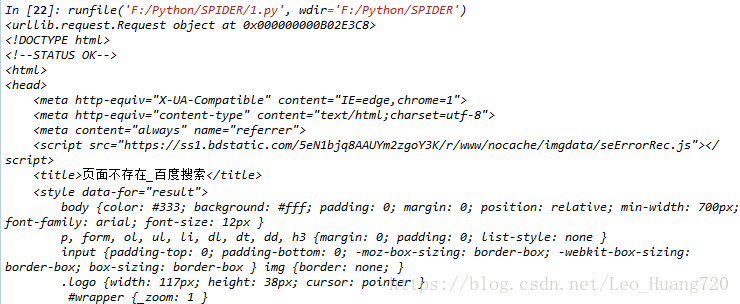
有了上面的格式转换,就成下面的样子,和你在网页中右键——审查元素看到的是一样的格式
Get方式传送数据
import urllib
import urllib.request
import urllib.parse
myData={}
myData['key1']='value1'
myData['key2']='value2'
myNewData=urllib.parse.urlencode(myData)#转换格式
url="https://passport.baidu.com/v2/?login"#百度登录界面
newUrl=url+'?'+myNewData
req=urllib.request.Request(newUrl)#新建req变量表示一个请求
respon=urllib.request.urlopen(req)#新建respon变量表示对应req请求的一个响应
page=respon.read().decode("utf8")#让爬到的页面为Html代码
print(newUrl)
print(page)运行结果:
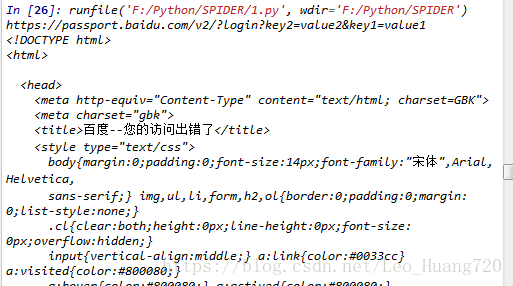
其中要注意:get传送数据最主要的不同是直接修改了请求的URL,使你要传送的数据在URL上体现出来,即https://passport.baidu.com/v2/?login?key2=value2&key1=value1
而post是将数据作为的一个参数传入,即urllib.request.Request(url,myNewData)
requests库
关于如何使用requests模块向网站发送http请求,获取到网页的HTML数据。
get和post传送数据
import requests
myData={"key1":"value1","key2":"value2"}#要传递的数据
response1=requests.get("https://www.baidu.com/")#无参的get请求
response2=requests.get("https://www.baidu.com/",params=myData)#有参的get请求
response3=requests.post("https://www.baidu.com/")#无参的post请求
response4=requests.post("https://www.baidu.com/",data=myData)#有参的post请求
print(response1.text)
print(response2.text)
print(response3.text)
print(response4.text)