文章目录
一.urllib库基本介绍
urllib库是python内置的HTTP请求库,它可以看作处理URL的组件集合。urllib库包含三大组件:
1.urllib.request 请求模块
2.urllib.error 异常处理模块
3.urllib.parse URL解析模块
4.urllib.robotparser robots.txt解析模块
注意:python2使用的是urllib2模块,python3出现后,之前的python2中的urllib2模块被
移植到了urllib.request模块中了,之前的urllib中的函数的路径也发生了改变
二.urllib.request 请求模块
1.urlopen方法参数解析
urlopen方法用于向指定URL发送get请求或者post请求
def urlopen(
url, #url参数,标识目标网站中的位置,表示url地址
data=None, #1.用来指明向服务器发送请求的额外信息 http协议是唯一支持data参数的协议
data默认是None,此时发送的时get请求;当设置参数时,需要使用post请求
2.使用urllib.parse.urlencode()方法将data转换为标准格式,而这个参数接收
的类型是键值对类型
3.data必须是一个bytes对象
timeout=socket._GLOBAL_DEFAULT_TIMEOUT,*, #可选参数,用于设置超时时间,单位秒
cafile=None,capath=None,cadefault=False, #这三个参数用于实现CA证书的HTTPS请求,很少使用
context=None #实现ssl加密传输,很少使用
)
1.1.发送get请求
from urllib import request,parse
# 使用urlopen方法向url方式请求
response = request.urlopen("https://www.baidu.com/")
# 使用read() 方法读取到页面内容,使用decode()方法解码 utf-8
html = response.read().decode('utf-8')
# 打印结果
print(html)
1.2.发送post请求(设置data参数)
如果设置data参数那么请求方式会改为post,默认是get请求。这两种请求方式最大的区别在于:get方式直接使用URL访问,在URL中包含了所有的参数;post方式则不会在URL中显示所有的参数,参数包含在请求体中,会更加安全。
注意:1.需要使用urllib.parse.urlencode(data)将data转换为标准格式
2.data必须是一个bytes对象
from urllib import request,parse
# data参数使用,使用data参数,那么就是post请求 encode('utf-8'))使用utf-8编码方式
data = bytes(parse.urlencode({'world':'hello'}).encode('utf-8'))
#http://httpbin.org/ 是一个简单的HTTP请求和响应服务。
#这里发送的就是post请求
response2 = request.urlopen("http://httpbin.org/post",data=data)
# 这里需要用utf-8编码解码
html2 = response2.read().decode('utf-8')
print(html)
1.3.设置timeout参数
该参数用于设置超时时间,单位是秒
from urllib import request,parse
# timeout参数使用,超时时间设置成一秒
response3 = request.urlopen("https://www.baidu.com/",timeout=1)
html3 = response3.read()
1.4.HTTPResponse对象
使用上述urlopen方法发送http请求后,服务器返回的响应内容会封装在一个HTTPResponse对象中,如下代码演示:
from urllib import request
# 传入URL构造出Request对象
url = request.Request("https://www.baidu.com/")
response = request.urlopen(url)
print(type(response))
#输出结果:<class 'http.client.HTTPResponse'>
HTTPResponse类提供了URL,状态码,响应内容等方法,常见方法如下:
| 方法名 | 解释 |
|---|---|
| geturl() | 获取当前请求的URL |
| info() | 返回页面元信息 |
| getcode() | 返回响应码 |
代码演示
from urllib import request
# 传入URL构造出Request对象
url = request.Request("https://www.baidu.com/")
response = request.urlopen(url)
# print(type(response)) #<class 'http.client.HTTPResponse'>
# 获取当前请求的URL
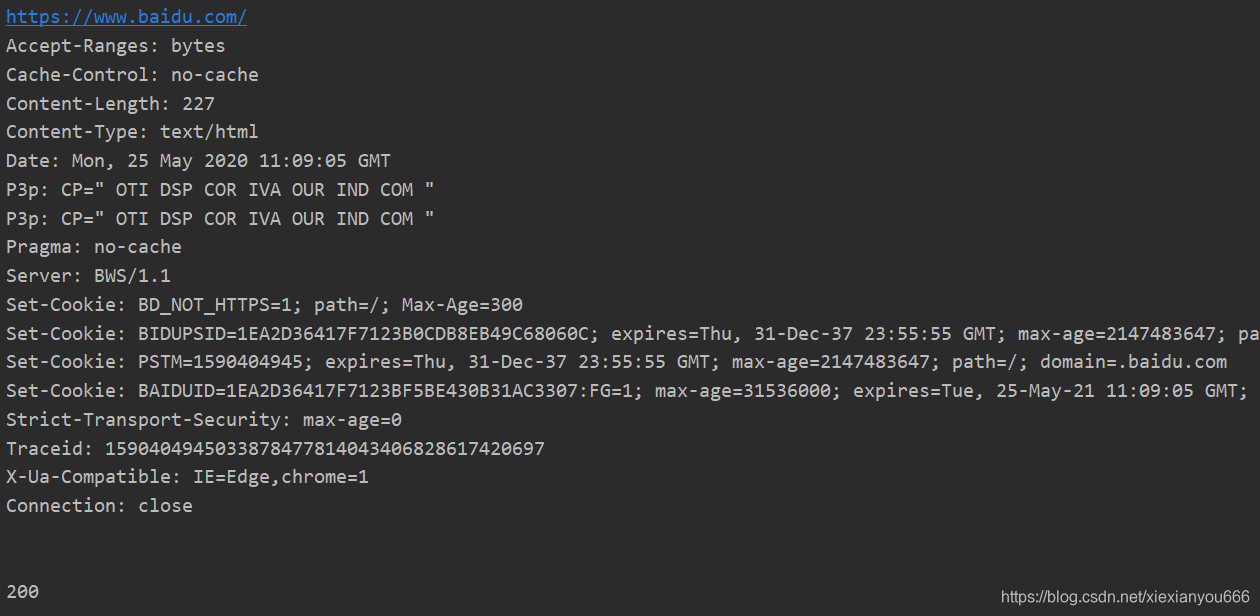
print(response.geturl())
#返回页面元信息
print(response.info())
# 返回状态码
print(response.getcode())
输出结果
2.构造Request对象
细心的朋友已经发现,urlopen()方法没有接收header的参数,如果需要添加HTTP报头,这时就需要用到Request对象
下面是Request的构造方法
class Request:
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None):
我们可以将url,data,headers等参数传入构造方法,构建一个Request对象
下面是爬虫百度翻译的案例
from urllib import request, parse
url = "https://fanyi.baidu.com/sug"
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
fromdata = {
# 待翻译的英语单词
"kw": "China"
}
# 构建data对象
data = bytes(parse.urlencode(fromdata).encode("utf-8"))
# # 构建Request对象
request1 = request.Request(url=url, headers=header, data=data)
responce = request.urlopen(request1)
# 将Unicode编码转换成中文
html = responce.read().decode("unicode-escape")
print(html)
输出结果

*
三.urllib.parse URL解析模块
URL编码转换,就是将中文或者其他特殊符号转换成URL编码(URL encoding),这个编码也称作百分号编码(Percent-encoding), 是特定上下文的统一资源定位符 (URL)的编码机制
URL编码和解码实例代码
from urllib import parse
data = {
"a": "爬虫",
}
# 按照UrlEncode对data进行编码
result = parse.urlencode(data) #a=%E7%88%AC%E8%99%AB
print(result)
# 对该编码进行解码
result2 = parse.unquote(result)
print(result2)
输出结果

四.代理服务器
很多网站会检测某一段时间某个IP的访问次数,如果同一IP访问过于频繁,那么该网站会禁止该IP的访问。针对这种情况,可以使用代理服务器,每隔一段时间换一个代理。如果某个IP被禁,可以换成其他IP继续爬取从而有效解决网站禁止访问的情况;代理多用于防止“反爬虫”机制。
1.使用自定义opener对象发送请求
前面我们一直使用的是urlopen方法发送请求,其实这也是一个opener。但是urlopen()方法不支持代理、cookie等其他的HTTP/HTTPS高级功能,如果需要用到这些高级功能,这时就需要自定义opener了。
构建opener对象实例代码
from urllib import request
# 构建一个HTTPHandler处理器对象,支持处理HTTP请求
http_handler = request.HTTPHandler()
# 创建支持处理HTTP请求的opener对象
'''
从处理程序列表创建opener对象。
opener将使用几个默认处理程序,包括支持
适用于HTTP、FTP和HTTPS。
如果作为参数传递的任何处理程序是
默认处理程序,将不使用默认处理程序。
'''
opener = request.build_opener(http_handler)
# 构建Request请求
res = request.Request("https://www.baidu.com/")
# 使用指定要的opener对象的open方法,发送request请求
response = opener.open(res)
print(response.read().decode("utf-8"))
2.设置代理服务器
我们可以使用urllib.request中的ProxyHandler()方法来设置代理服务器
from urllib import request
#构建两个代理Handler,一个有代理IP,一个没有代理IP
httpProxy_handler = request.ProxyHandler({"http":"192.168.220.13:80"})
nullProxt_handler = request.ProxyHandler()
#设置一个代理开关
proxy_loop = True
# 根据代理开关是否打开,使用不同的代理
if proxy_loop:
opener = request.build_opener(httpProxy_handler)
else:
opener = request.build_opener(nullProxt_handler)
response = opener.open("https://www.baidu.com/")
print(response.read().decode("utf-8"))
五.requests库
requests库是基于python开发的HTTP库,与urllib标准库相比,代码要简洁。实际上,requests库是在urllib的基础上进行了高度封装,它不仅继承了urllib库的所有特性,而且还支持Cookie保存会话,自动确定响应内容的编码等。
1.requests库常用类:
| 库 | 解释 |
|---|---|
| requests.Request | 表示请求对象,用于将一个请求发送到服务器 |
| requests.Response | 表示响应对象,其中包含服务器对HTTP请求的响应 |
| requests.Session | 表示请求会话,提供Cookie持久性,连接池和配置 |
2.requests库的请求函数
| 函数 | 功能说明 |
|---|---|
| requests.request() | 构造一个请求,支持以下各方法的基础方法 |
| requests.get() | 请求指定页面信息,并返回实体主体 |
| requests.post() | 向指定资源提交数据进行处理请求(如提交表单或者上传文件),数据包含在请求体中。post请求可能会导致新的资源的建立和已有资源的修改 |
| requests.head() | 类似于get请求,只不过返回的响应中没有具体内容,用于获取报头 |
| requests.put() | 这种请求方式下,从客户端向服务器传送的数据取代指定的文档内容 |
| requests.delete() | 请求指定服务器删除指定页面 |
| requests.patch() | 向HTML网页提交局部修改请求 |
3.返回响应
Response类用于动态的响应客户端的请求,控制发送给用户的信息,并且将动态地生成响应,包括状态码,网页的内容等
Response的常用属性
| 属性 | 说明 |
|---|---|
| status_code | HTTP请求的返回状态,200代表连接成功,404表示失败 |
| text | HTTP响应内容的字符串形式,即URL对应的页面内容 |
| encoding | 从HTTP请求头中猜测的响应内容编码方式 |
| apparent_encoding | 从内容中分析出响应编码方式(备选编码方式) |
| content | HTTP响应的二进制形式 |
Response类会自动解码来自服务器的内容,并且大多数的Unicode字符集都可以被无缝地解码。
代码示例,你会发现requests库比urllib库简单好多
import requests
url = "https://www.baidu.com/"
response = requests.get(url)
#以字符串的形式返回
print(response.text)
# 查看文本编码
print(response.encoding)
# 查看响应码
print(response.status_code)
输出结果