
论文连接:https://readpaper.com/pdf-annotate/note?pdfId=4731757617890738177¬eId=1715361536274443520
源码链接: https://github.com/Johanan528/Cones
Overview
What problem is addressed in the paper?
Concatenating multiple clusters of concept neurons representing different persons, objects, and backgrounds can flexibly generate all related concepts in a single image. (将多个指定主体融入到一个场景中)
Is it a new problem? If so, why does it matter? If not, why does it still matter?
No, this is the first method to manage to generate four different diverse subjects in one image. (subject-driven generation methods)
What is the key to the solution?
We propose to find a small cluster of neurons, which are parameters in the attention layer of a pretrained text-to-image diffusion model, such that changing values of those neurons can generate a corresponding subject in different contents, based on the semantics in the input text prompt.
This paper proposes a novel gradient-based method to analyze and identify the concept neurons, termed as Cones1. We motivate them as the parameters that scale down whose absolute value can better construct the given subject while preserving prior information.
What is the result?
Extensive qualitative and quantitative studies on diverse scenarios show the superiority of our method in interpreting and manipulating diffusion models.
Method
3.1. Concept Neurons for a Given Subject
concept-implanting loss
![]()
where:
![]()

Algorithm:

3.2. Interpretability of Concept Neurons
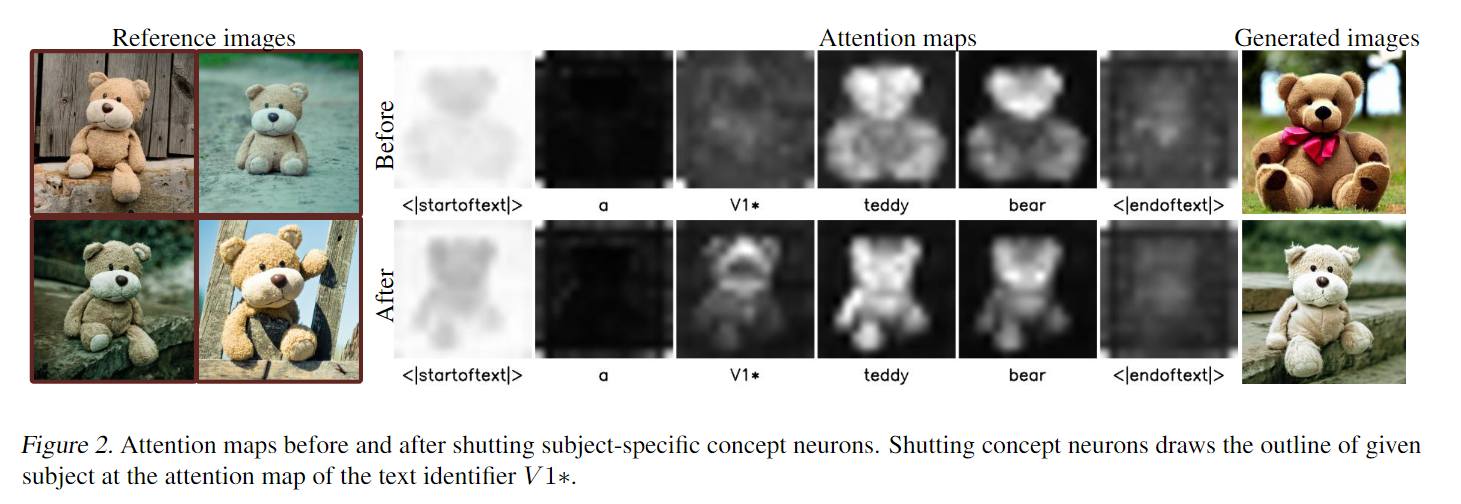
Shutting the concept neurons immediately draw the outline of the given subject in the attention map corresponding to the text identifier and subsequently generate the subject in the final output. This shows the strong connections between concept neurons and the given subject in the network representations.



3.3. Collaboratively Capturing Multiple Concepts

Expriments

Figure 7. Comparison of multi-subject generation ability. First row: compared with other methods, ours can better generate the “sweater” in the prompt. Second row: Our method better reflects the semantics of “playing”, while Dreambooth loses the details of the wooden pot. Third row: our generated images have a higher visual similarity with the target subject, and better semantics alignment with “sitting” and “wearing”. Dreambooth fails to generate “chair”. Fourth row: Cones (Ours) maintains high visual similarity for all subjects.

Figure 8. Comparison of tuning-free subject generation methods. For Cones, we concatenate concept neurons of multiple subjects directly. For Custom Diffusion, we use the “constraint optimization” method of it to composite multiple subjects.

Table 1. Quantitative comparisons. Cones performs the best except for image alignment in the single subject case. This could be due to that the image alignment metric is easy to overfit as is pointed out in Custom Diffusion (Kumari et al., 2022). DreamBooth and Textual Inversion employ plenty of parameters in the learning, while Cones only involves the deactivation of a few parameters.

Table 2. Storage cost and sparsity of concept neurons. As the number of target subjects increases, we need to store more indexes of concept neurons. We save more than 90% of the storage space compared with Custom Diffusion
Conclusion
This paper reveals concept neurons in the parameter space of diffusion models. We find that for a given subject, there is a small cluster of concept neurons that dominate the generation of this subject. Shutting them will yield renditions of the given subject in different contexts based on the text prompts. Concatenating them for different subjects can generate all the subjects in the results. Further finetuning can enhance the multi-subject generation capability, which is the first to manage to generate up to four different subjects in one image. Comparison with state-of-the-art competitors demonstrates the superiority of using concept neurons in visual quality, semantic alignment, multi-subject generation capability, and storage consumption.