Novel View Synthesis with Diffusion Models
文章的原地址为:https://arxiv.org/abs/2210.04628
想要直接生成一个3d图像比较困难
作者的研究动机主要是,在直接生成一个完整的3d空间点云的时候较为困难,于是作者想要转而寻求其他的方法,作者最终采用的方法是不断地生成3d图像的各个角度的视图,来完成最终的生成。也就是本文的最终目的是生成一组3d图像的视图。
现有模型存在的问题
现有的模型都是直接从一个图片生成到另外一个图片,缺少一个整体的生成。我个人理解这里是这样子的,原始的图片到图片的生成都是生成两个有关系的图片,并不能很好的保证生成的是同一个物体的两个视图,因此很难更有针对性的应用在3d视图的生成。所以作者才要开发这个模型来解决这个问题。
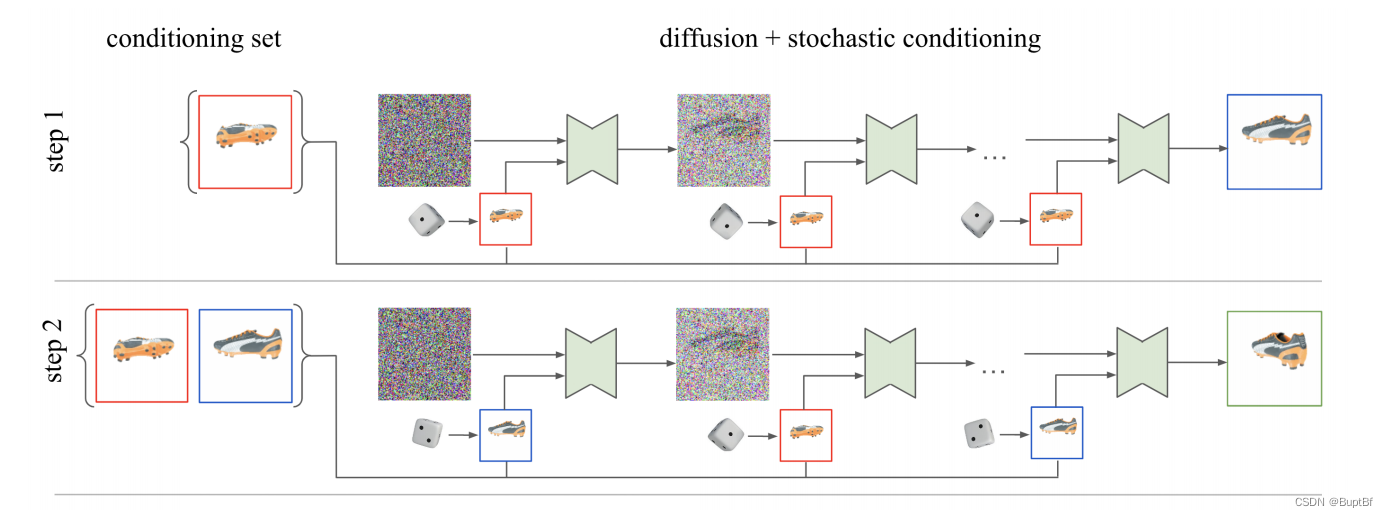
作者采用的结构
作者这里原有的扩散模型没有太大的区别,主要是控制信息的不同。
作者怎么输入控制信息
1.第一次输入(A视图,A视图对应的姿态角)输出(B视图,B视图对应的姿态角)
2.第二次输入(A视图,A视图对应的姿态角,B视图,B视图对应的姿态角)输出(C视图,C视图对应的姿态角)这次有两图片控制的,作者并没有融合他们,而是每次随机选择一个让其对生成进行控制。