1、Transformer

LSTM 和 transformer可以互相替代。
Long term dependency 是 rnn/lstm-based models 的主要问题。以及串行计算的高时间复杂度。shallow model,只在时间维度上deep,纵向的角度是浅层的。
Linear computation 是时序模型的通病。
1.2 Transformer的结构
encoder+decoder: 每个部分都是deep的
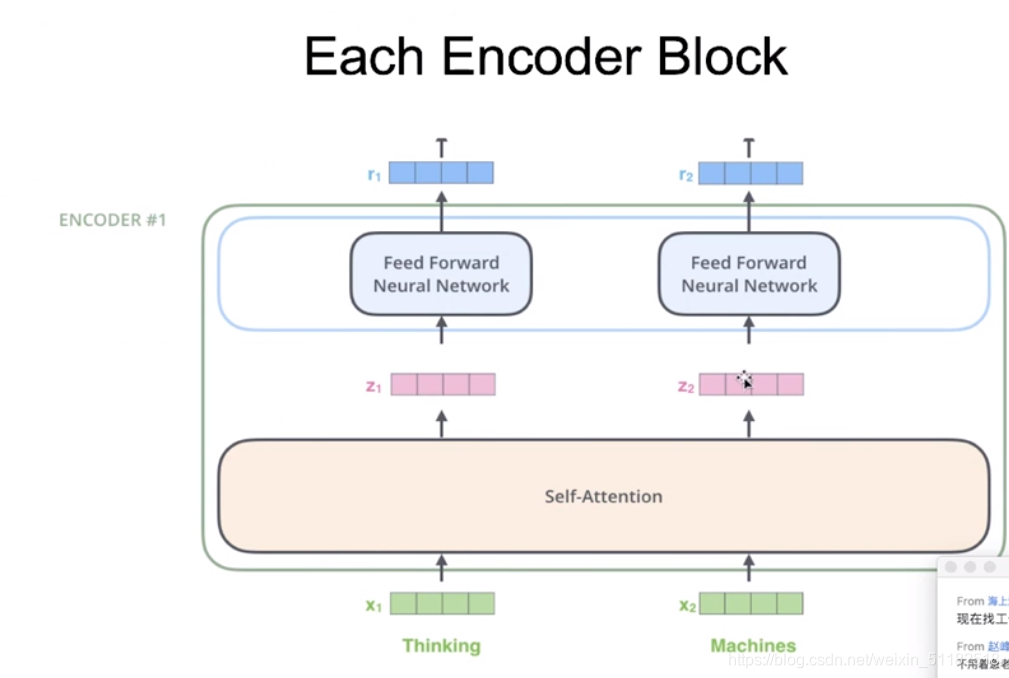
每个encoder:self-attention+feed forward
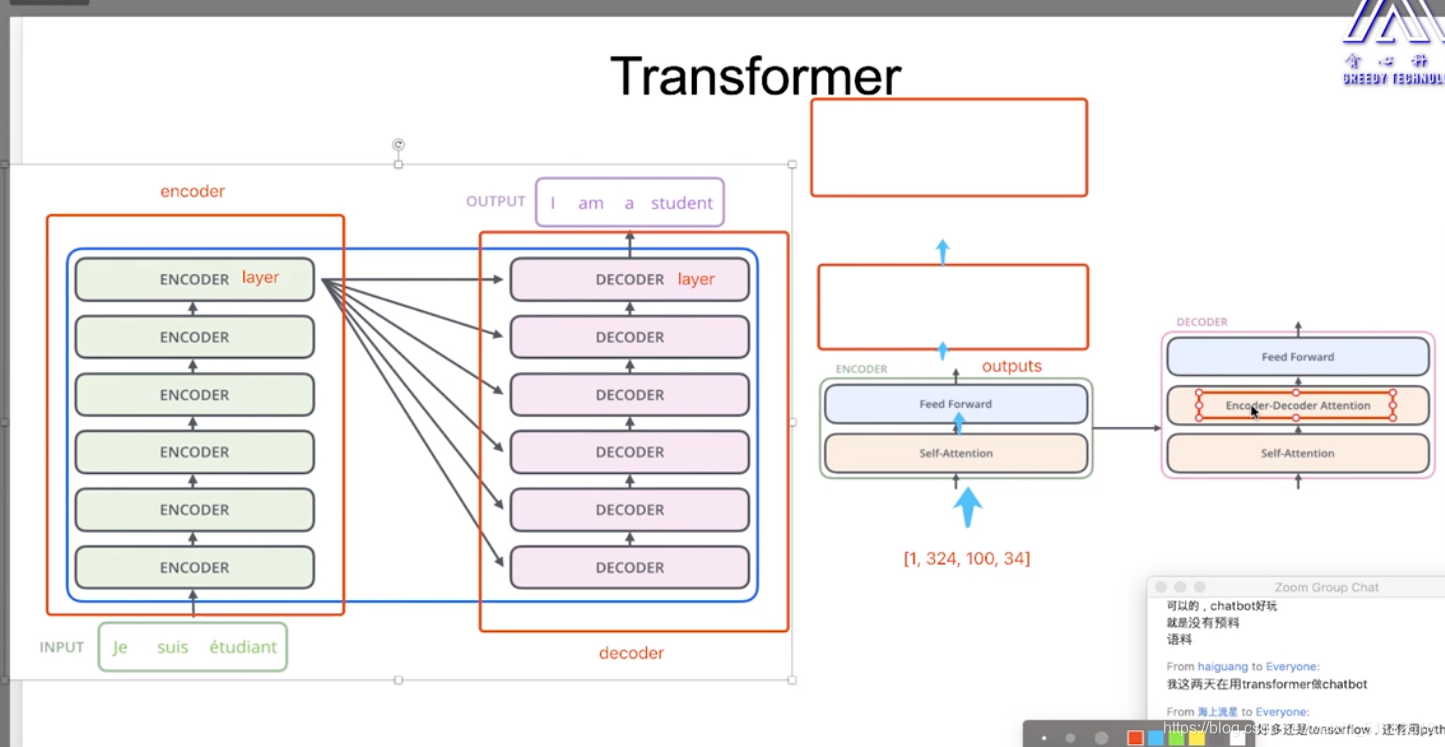
1.3 Encoder结构

1.4 Decoder 结构
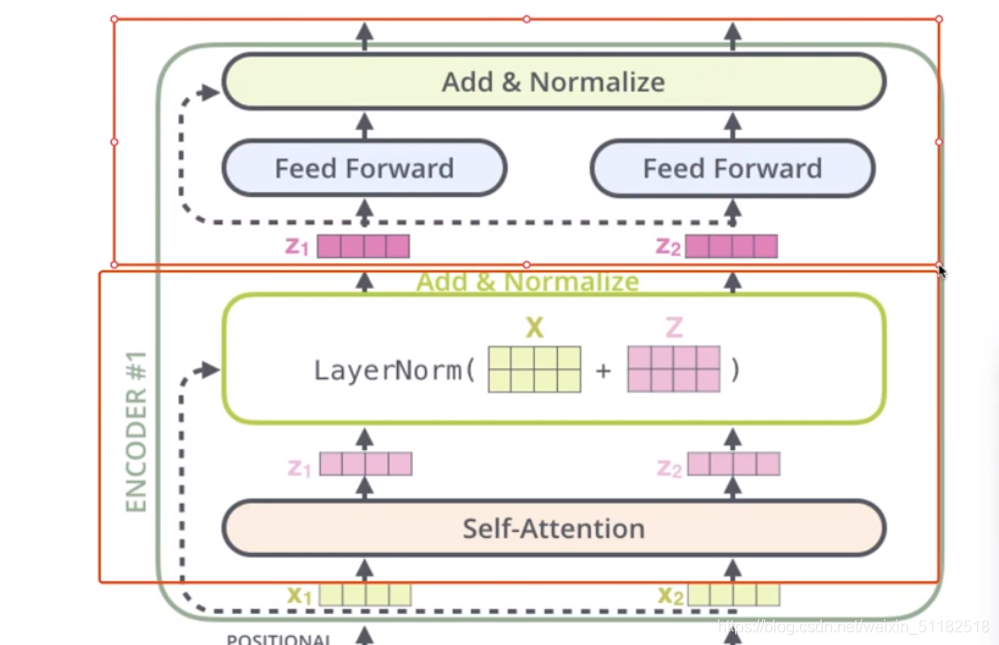
1.5 Each encoder block
Self-attention:q,k,v
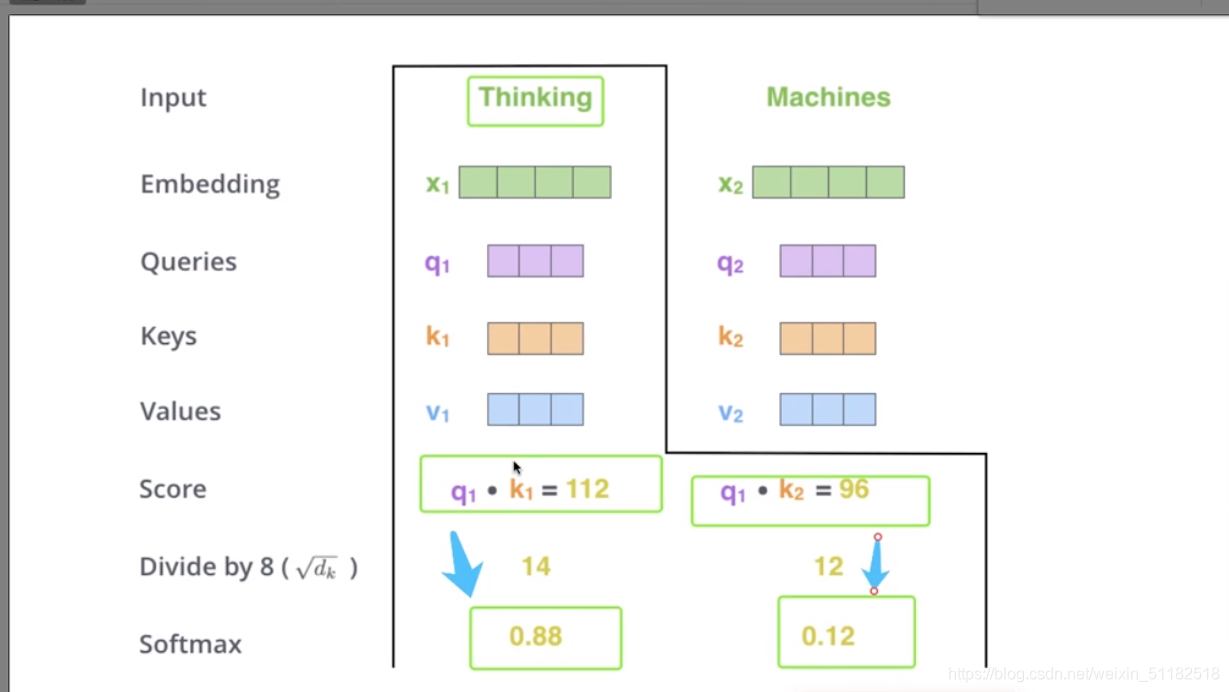
针对thinking这个单词,计算每个词对于它的依赖性的权值的过程。
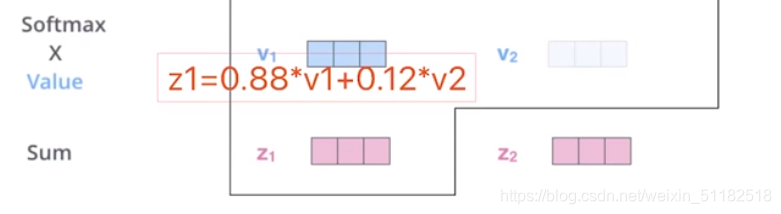
在self-attention的计算中,把一句话的每个词当作平等的关系计算它们之间的相关性。

通过self-attention可以计算每两个词之间的相关性,颜色越深代表相关性越强。
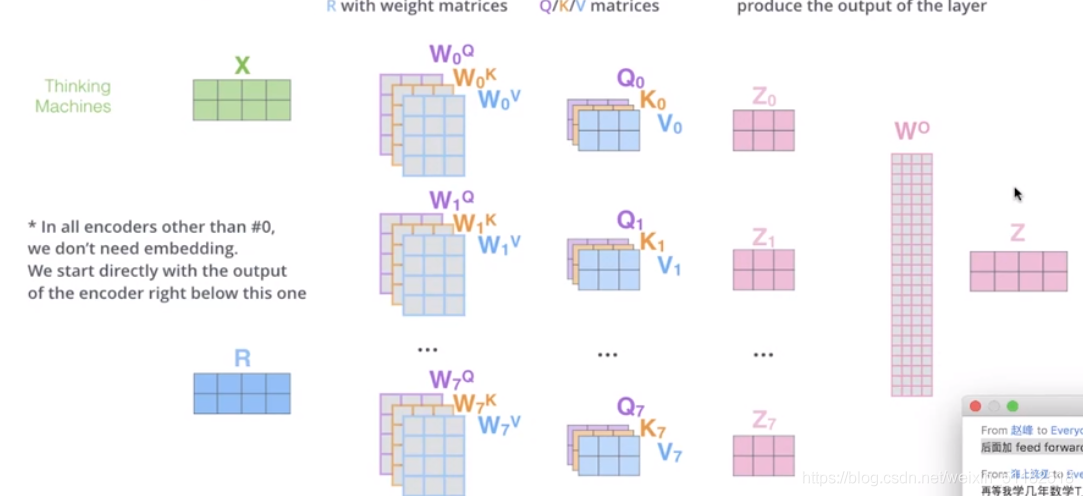
Multi-head attention 同时定义多个q,k,v矩阵。

最终的输出的是每一组q,k,v拼接起来的向量:z1+z2+z3+z4+z5+Z6+Z7,再定义一个w0,使其降维成z。
1.6 Encoder layer 部分代码

流程:经过attention layer,经过feedforward net
定义multi head attention & feed forward network


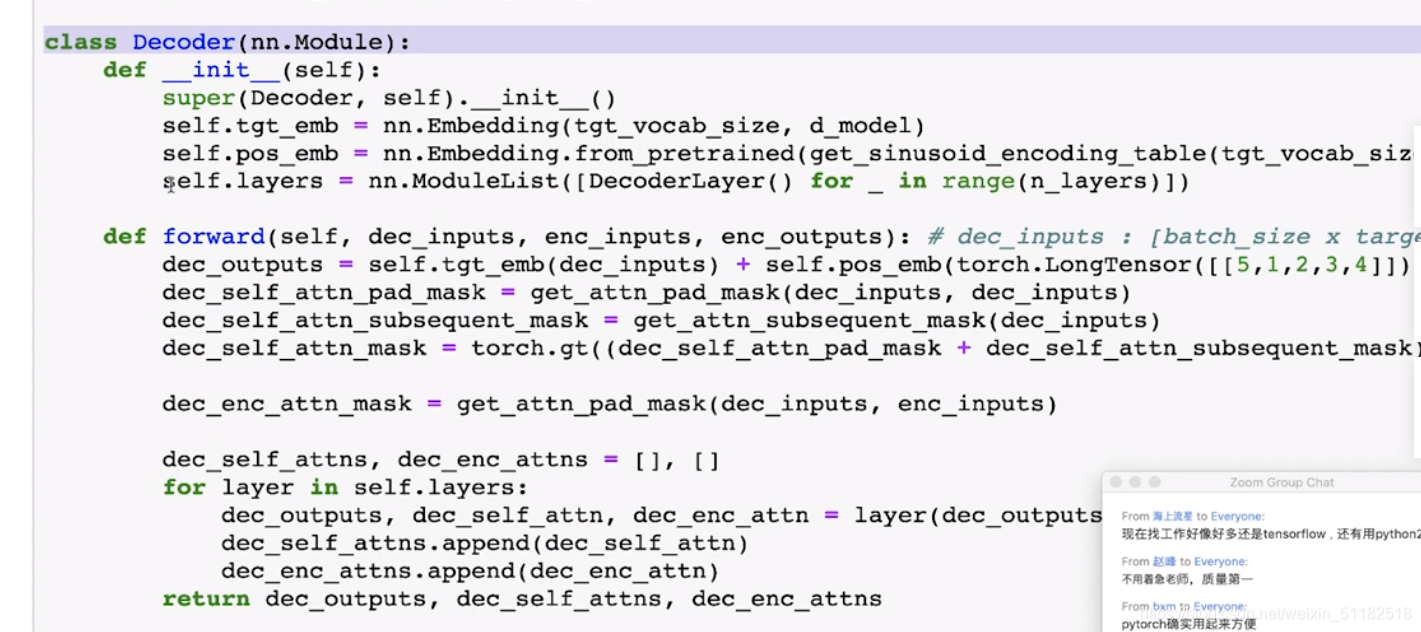
2、decoder 端
self-attention+encoder/decoder attention+feedforward
2.1 DecoderLayer

2.2 encoder-decoder attention

enocer-decoder attention使用的是encoder的output+decoder的output

3、BERT
3.1 Pretraining embedding
- Word2vec。问题:单词在不同场景下语义不同,embedding应该也不一样。
- Context representation
3.2 Learn contextualized embedding
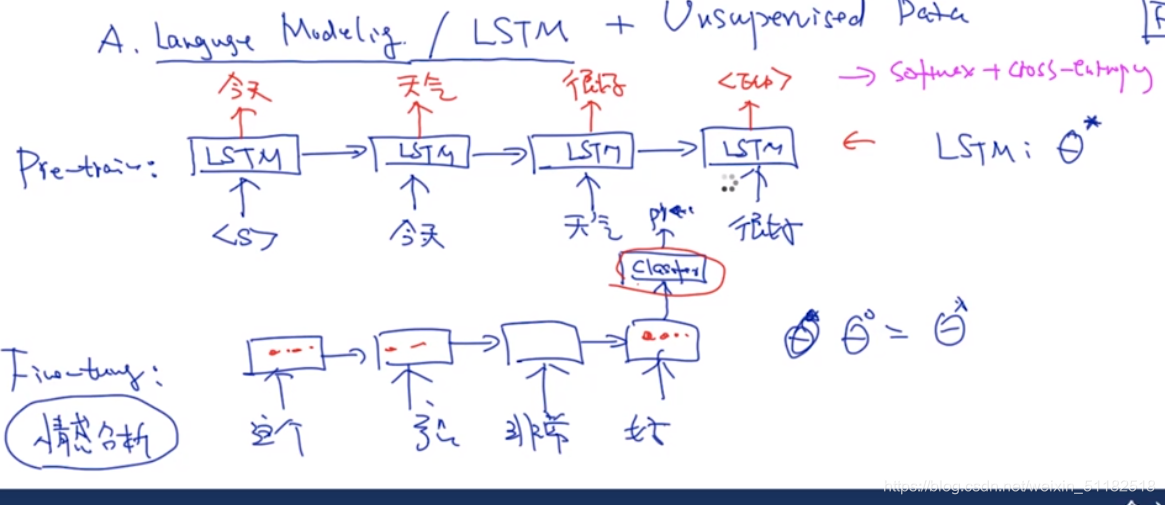
Language model/LSTM+ unsupervised data:给定当前单词,预测下一个单词
pretraining+fine tuning:预训练一个模型,拿到一个新的task,微调参数,使得模型可以在new task上得到好的结果
3.3 回顾language model
语言模型一般是单向的,优点是比较适合生成单词。但当目的是:想学习出最好的单词表示法(在上下文中),比如学习w2在整句话中的含义,需要观察整个句子的单词。
如何改进语言模型?
1)bidirectional LSTM:相当于训练了两个模型。

2)Fully bidirectional context embedding
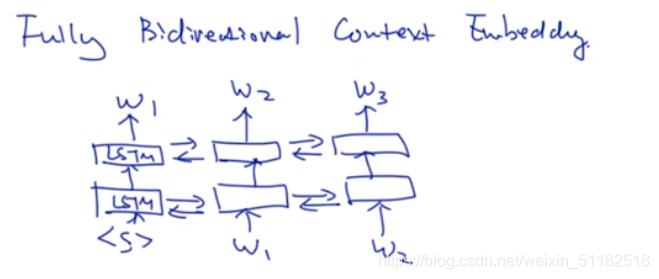
为什么language model 要设计成单向?
计算的便利性。
3.4、Masked language model
把一些单词随机的去掉,去掉的单词加入特殊符号,任务变成通过一层模型,输入带特殊符号的句子,预测出那些被去掉的单词。使用交叉熵计算loss进行优化。
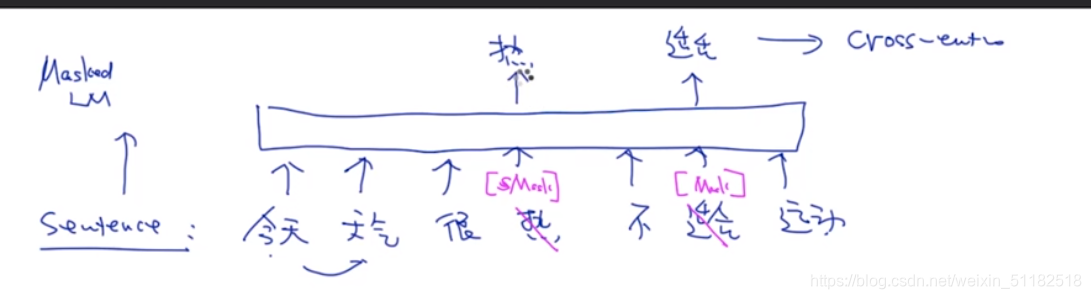
masked language model 预测的是被masked 的位置,计算loss只计算被标记的单词。
为什么要这么做?
为了让模型更加稳定:add noise(drop out 也属于add noise的方法),希望模型在加入noise后也能有很好的表现
De-noising auto-encoder:输入的向量加入一些噪声输入到encoder,通过学习使得decoder依然可以很好的复原未加入噪声的图片。
masked language model存在的问题
domain的不匹配,测试数据是不包含mask的
如何解决:
3.5 Masked language model in BERT
masked language model+transformer.
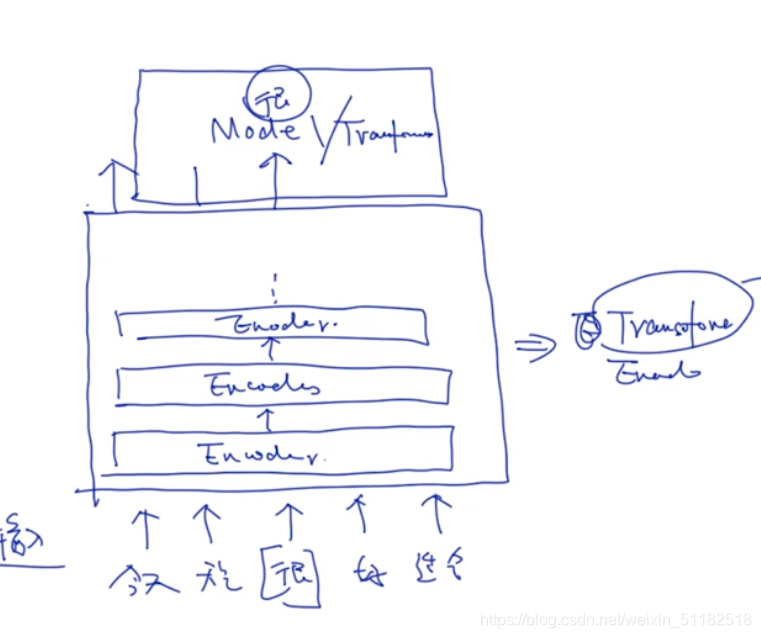
4、BERT: Masked+Transformer
4.1 Transformer 用于二分类的情感分析

加入一个cls,得到的c用于做classifier
4.2 Transformer 用于匹配两个sentence的关系
如果两个sentence是连续的,classifier输出1
如果sentence不是上下文关系,classifier输出0
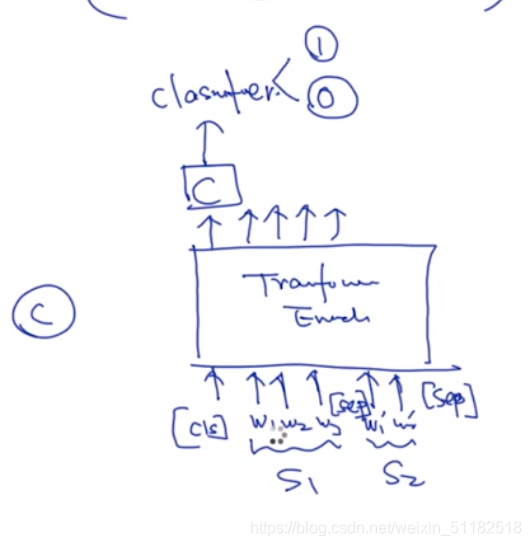
4.3 Bert 的loss
classifier的loss+masked部分的loss
5、Bert的训练过程
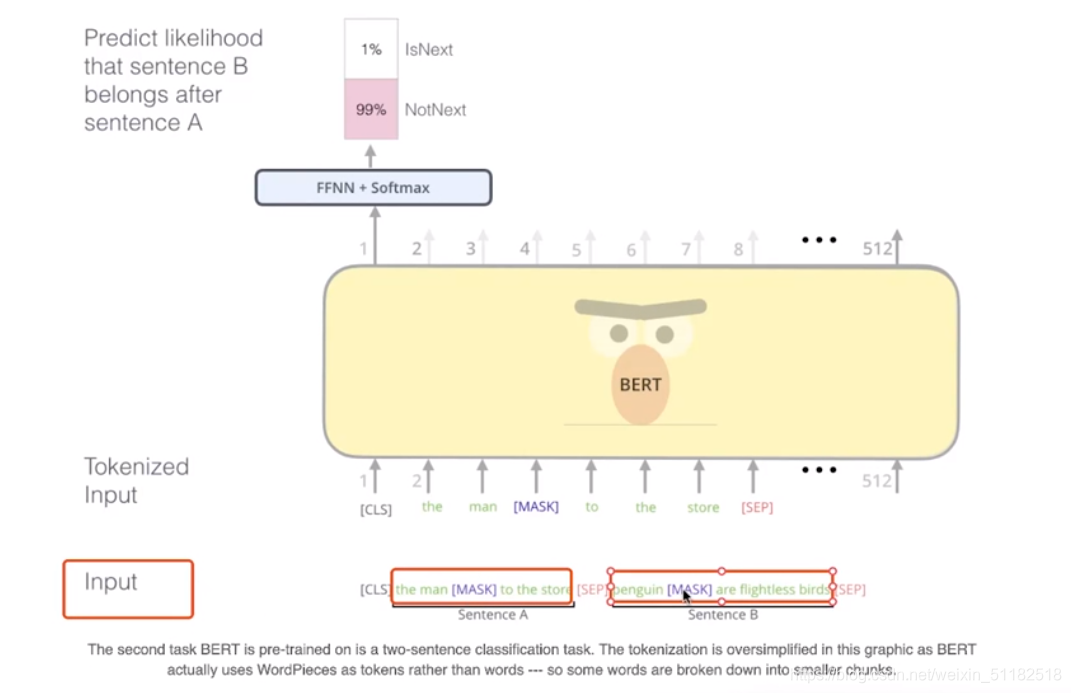
classifier:判断两个sentence是否是连续的文本。
Bert 代码
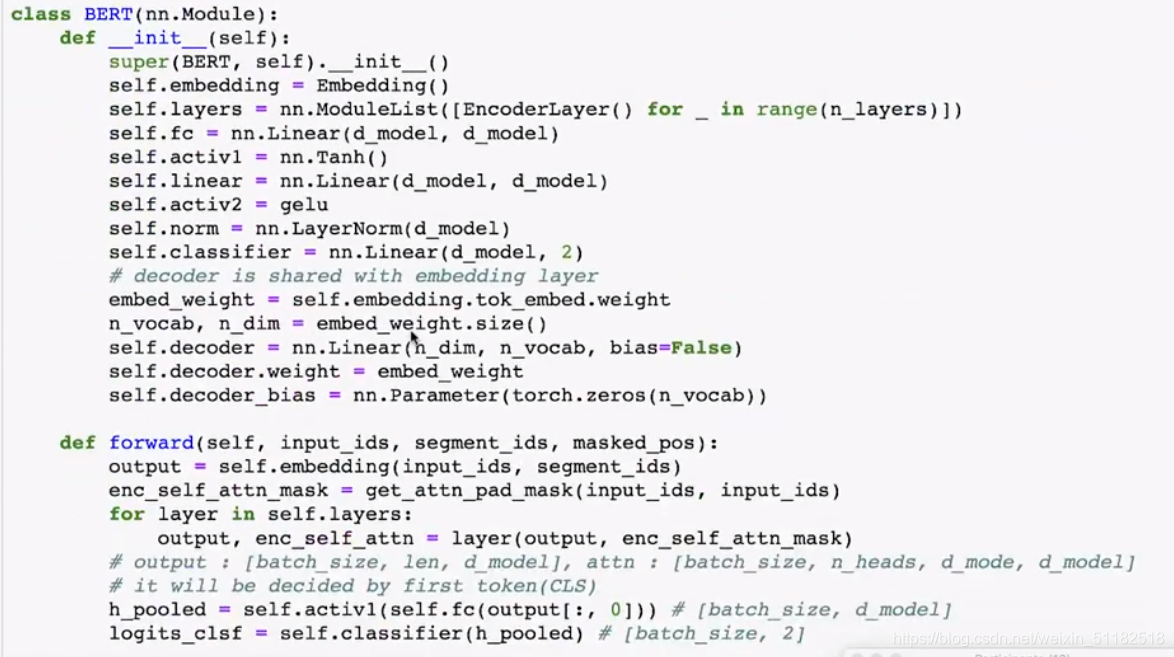
Bert的forward:
1、对单词做embedding, 三个部分的embedding
- token embedding 单词信息
- position embedding 位置信息
- segment embedding 单词出现在sentence1还是sentence2
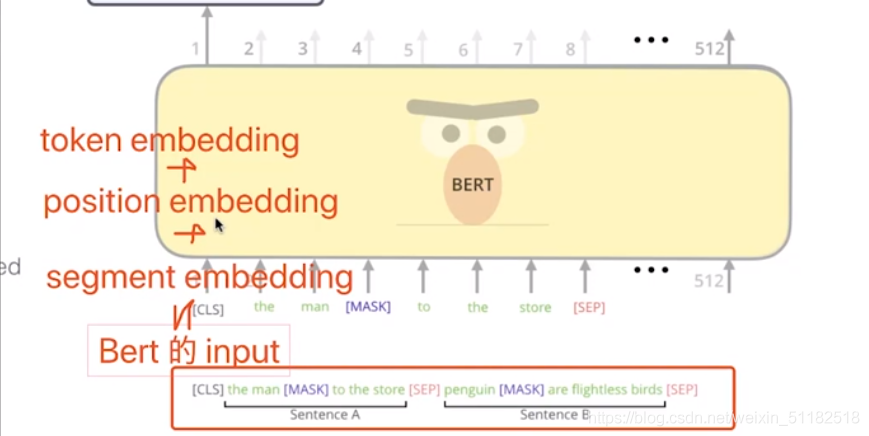
embedding部分:

2、做mask,将embedding输入进n层的layers
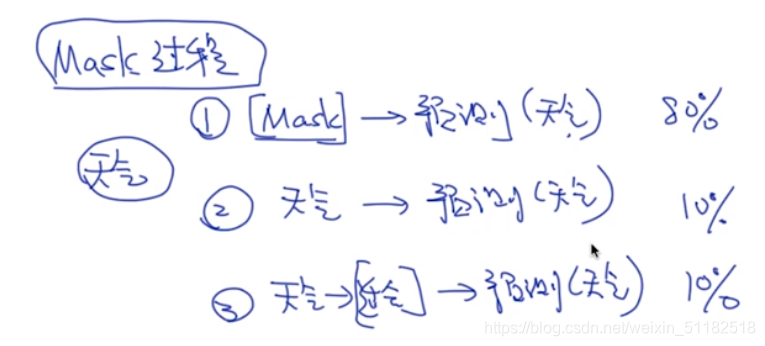
3、Mask LM

80%的概率,单词要mask掉
10的概率:单词要被替换到其他的单词