BERT 的优缺点:
优点:
- 1、考虑双向信息(上下文信息)
- 2、Long term dependency
缺点: - 1、测试数据没有masked,训练和测试数据不匹配
- 2、缺乏生成能力
- 3、针对每个mask预测时,没有考虑相关性。类似朴素贝叶斯
Auto-regressive LM 的优缺点:经典的Language mode
从左到右的语言模型
优点:
- 1、具备生成能力
- 2、考虑了词之间的相关性
- 3、无监督学习
- 4、严格的数据表达式
缺点: - 1、单向的
- 2、离得近的单词未必有关系
- 3、看不到很远的单词
ELMO
单向 LSTM x2
XLNet的改进思路:
根据bert和lm的缺点,改进的点
- 具备生成能力
- 双向学习能力
- 不出现discrepancy
LM+NADE:使得语言模型具备双向的能力
Transformer-XL:使得模型具备对于不固定长度的seq学习的能力
LM的目标函数

对于第t个单词,使用前t-1个单词去预测第t个单词产生的概率
使用了softmax
BERT的目标函数
给定unmasked词,预测masked部分的词

Question: LM 如何改造成考虑到上下文(左边/右边)
引入 permutation language model
不关心变量的顺序,对每个变量做排列组合,统计所有单词可能产生的语序。
当考虑了所有可能性考虑的时候,相当于考虑到了w3之外的所有单词
把w3放在不同位置,再对每一个情况,把w1、w2和w4排列组合:
考虑了4!=24个语言模型

使用permutation 的 LM 的目标函数:

取得是所有排列组合集合的期望。
对于每一种情况的w的位置t,每一次也只考虑t前面的单词。
对于在一个seq的某个位置预测一个词,目标:找到一个词,使得它在seq中经过所有排列组合后的概率的期望值最大。
- 因为n!的模型数量太多,所以需要采样
- predict last few tokens


输入的顺序不变,通过mask矩阵实现n!的language model 类型
Transformer-XL
对于时序类模型优缺点的分析:
1)Transformer的缺点?
没有考虑语序:通过加入position embedding 解决
计算量大,参数量大,每一个encoder都需要保存q,k,v计算的矩阵信息。在bp中还需要使用这些参数。out of memory error
如何解决?:
把很长的文本的内容拆成多个模块,很多segments。

step 1: 将长的sequence拆分成很多小的sequence
step 2: 循环输入这些segements
问题:分割后的segment无法拼在一起
解决:将每个segment作为RNN每个时刻的输入,每个RNNcell 都是一个处理segment的transformer

但是,与传统RNN不同的是,对于memory的传递并非是参与乘以一个memory的weight,而是直接使用concatenation


Scoring matrix,单词与其他词之间的相关性。

如何让t+1时刻获得t-1时刻的信息?
concate more segments for inputs of each RNNCell

a:i和j单词之间的相关性
b:i和j位置之间的相关性
c:i单词和j位置之间的相关性,根据第i个单词的embedding和j单词的位置信息。
d:i位置和j单词的相关性。
如何将position encoding从绝对的位置关系,转变为相对位置关系
即,不在乎具体的位置,只考虑位置之间的关系。
改造后:使用相对位置信息,并对k进行改造。


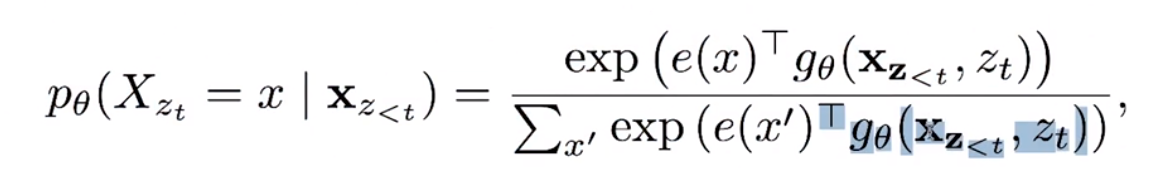
加入一个对于当前单词位置的参数 z t z_t zt