分类目录:《深入理解深度学习》总目录
相关文章:
· BERT(Bidirectional Encoder Representations from Transformers):基础知识
· BERT(Bidirectional Encoder Representations from Transformers):BERT的结构
· BERT(Bidirectional Encoder Representations from Transformers):MLM(Masked Language Model)
· BERT(Bidirectional Encoder Representations from Transformers):NSP(Next Sentence Prediction)任务
· BERT(Bidirectional Encoder Representations from Transformers):输入表示
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[句对分类]
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[单句分类]
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[文本问答]
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[单句标注]
· BERT(Bidirectional Encoder Representations from Transformers):模型总结与注意事项
BERT的作者认为,使用自左向右编码和自右向左编码的单向编码器拼接而成的双向编码器,在性能、参数规模和效率等方面,都不如直接使用深度双向编码器强大,这也是BERT使用Transformer Encoder作为特征提取器,而不使用自左向右编码和自右向左编码的两个Transformer Decoder作为特征提取器的原因。既然无法使用标准语言模型的训练模式,BERT借鉴完形填空任务和CBOW的思想,采用MLM方法训练模型。具体而言,就是随机取部分词(用替换符[MASK]代替)进行掩码操作,让BERT预测这些被掩码词,以 P ( w i ∣ w 1 , w 2 , ⋯ , w n ) P(w_i|w_1, w_2, \cdots, w_n) P(wi∣w1,w2,⋯,wn)为目标函数优化模型参数(仅计算被掩码词的交叉熵之和,将其作为损失函数)。通过根据上下文信息预测掩码词的方式,BERT具有了基于不同上下文提取更准确的语义信息的能力。
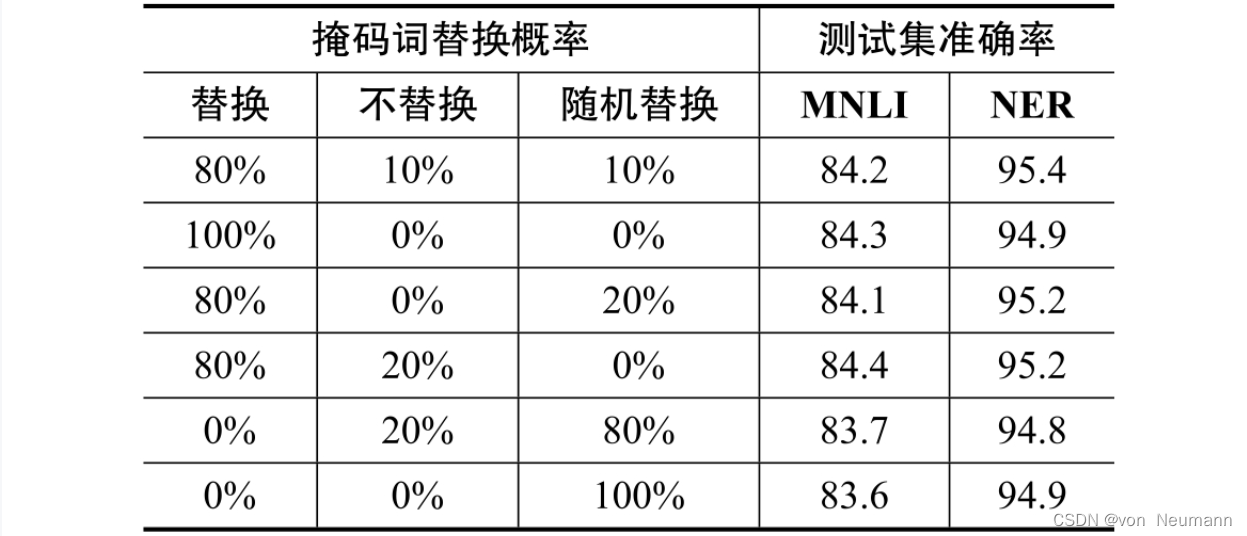
在训练中,掩码词被替换成[MASK]的概率是15%。一个句子中的掩码词可能有多个,假设词 A A A和词 B B B均为掩码词,则预测掩码词 B B B时,参考的上下文中,词 A A A的信息是缺失的( A A A已经被替换成了[MASK],故原有语义信息丢失)。如此设计MLM的训练方法会引入弊端:在模型微调训练阶段或模型推理阶段,输入的文本中不含[MASK],即输入文本分布有偏,继而产生由训练与预测数据偏差导致的性能损失。考虑到此弊端,BERT并不总是用[MASK]替换掩码词,而是按照一定的比例选取替换词。选取15%的词作为掩码词后,这些掩码词有三类替换选项。假设训练文本为“地球是太阳系八大行星之一”,现在需要将“太阳系”设置为掩码词,则替换规则如下:
- 在80%的训练样本中,需要用
[MASK]作为替换词:“地球是[MASK]八大行星之一” - 在10%的训练样本中,不需要对被替换词做任何处理,例如:“地球是太阳系八大行星之一”
- 在10%的训练样本中,需要从模型词表中随机选择一个词作为替换词,例如:“地球是苹果八大行星之一”
让一小部分替换词保持原样是为了缓解训练文本与预测文本的偏差带来的性能损失,让另一小部分替换词被替换为随机词,是为了让BERT学会根据上下文信息自动纠错。假设没有随机替换选项,BERT在遇到非[MASK]词时,直接选择与输入词相同的词,将会得到最优的交叉熵。通过采用掩码词随机替换的策略,强制BERT综合上下文信息整体推测预测词,从数学角度看,避免了BERT通过“偷懒”的方式获得最优目标函数的隐患。简言之,使用根据概率选取替换词的MLM训练方法增加了BERT的鲁棒性和对上下文信息的提取能力。这个概率分配比例并不是随机设计的,而是BERT在预训练过程中尝试了各种配置比例,通过测试对比得到的最优结果。在替换词配置比例的测试中,选取两个下游任务作为测试标准,测试结果如下图所示。结果表明,替换比例为8∶1∶1时,能得到性能最好的预训练语言模型。除此之外,采用MLM的训练方法,每次只对输入文本的15%的词进行训练,而GPT可以对输入文本的每个词都做交叉熵。虽然BERT比GPT的训练效率低了很多,但从下图的结果来看,MLM训练方法可以让BERT获得超出同期所有预训练语言模型的语义理解能力,牺牲训练效率是值得的。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.