摘要
本文提出了一个新的网络架构,融合特征提取,序列模型和转录为一个统一的架构。相比于之前的场景文本识别,本问提出的方法有4个特别的地方:1.端到端的训练;2.可以处理任意长度的序列;3.不受限于预定的词汇(不基于词典)4.更高效更小的模型。
引言
在现实世界中,像场景文本,手写数字以及音乐符号倾向于以序列的形式出现,不像一般的物体都是单个出现。因此文字识别很自然的作为序列识别问题。另外一个序列识别问题是其长度不固定,大多数DCNN不能直接应用于序列预测,因为DCNN模型经常处理固定的输入和输出。
而深度学习的另外一个重要分支RNN主要用来处理序列问题。RNN的一个优势是不需要训练和测试过程中图像的每个元素位置。然而输入图像转换为图像特征序列的前处理步骤通常是必须的。
本文的创新点主要就是将文字作为序列问题来进行识别。我们将提出的方法作为CRNN。对于序列识别问题,CRNN拥有几个明显的优势,1.可以直接从序列标签学习;2.和DCNN一样从图像数据学习特征;3.和RNN相同可以产生序列标签;4.不受文字的长度限制;5.获得了更好的性能在场景文本识别;6.参数更少,模型更小。
网络架构
整个网络架构如下图所示

自底向上分别由卷积层,循环网络层,翻译层三个部分组成。底层的卷积层从输入图像提取特征序列;上面的循环网络对每一帧的特征序列做预测。 顶层的翻译层用来产生标签结果。虽然CRNN是由几个不同的部分组成,却能用一个损失函数来训练。
特征序列提取
底层的卷积层是标准的CNN和最大池化组成。在输入网络之前,所有的图像放缩到相同的高度,然后通过卷积层提取特征序列向量。每个特征图的特征向量是自左向右生成。
emsp;由于对局部区域卷积层、最大池化、激活函数等操作,他们固定的翻译。因此,每一列的特征图对应原始图像的矩形区域,此区域也是自左向右相对应。如图2所示,每个特征序列的向量与一个区域相关联。

由于CNN的鲁棒性,易训练等特点,它被广泛用于各种视觉任务。然而这些方法提取整体图像的特征表示,然后提取局部特征识别每一个序列的组成部分。由于CNN要求固定的输入,因此不适合不固定长度的序列物体。在CRNN中,我们将深度特征转变为序列表示来固定序列物体的长度。
序列标签
循环网络层在特征序列x = x1, . . . , xT对每一帧xt预测一个标签分布yt。循环网络有三个优势。首先,RNN对于序列有很强捕获信息的能力,对于图像序列识别问题用内容线索是更加稳定。拿场景文本识别举例,宽字符可能需要几个连续的帧来描述。除此之外,一些模糊的字符是不容识别的。第二,RNN可以反向传播误差,这使得CNN和RNN可以在一个统一的网络训练。第三,RNN可以操作任意长度的序列。
传统的RNN单元在输入和输出之间有自连接隐藏层。每当在序列中收到xt,他用非线性函数(利用xt和ht-1作为输入)更新中间状态ht,ht=g(xt,ht-1)。然后预测yt是基于ht。然而传统的RNN单元会有梯度消失的问题,这限制了内容的变化,会增加训练过程的负担。LSTM则解决了这个问题。LSTM包含记忆细胞还有三个分别是输入、输出、忘记门。记忆细胞存储过去的内容,输入输出门允许细胞长的时间段内存储内容。同时记忆的内容可以被忘记门清除掉。这种特殊的设计允许LSTM捕获长范围的内容。
LSTM是定向型的,仅用过去的内容,然而基于图像的序列,内容来自两个方向是有用的,互补的。因此我们结合两个LSTM,一个向前,一个向后融合成一个双向的LSTM.而且多个双向的LSTM可以叠加,最终成为深度双向的LSTM如图3所示。深层的网络结构可以获得更高抽象水平的表达,在识别任务上获得了很大的改善。
在循环网络层,误差在相反的方向传播。

在循环网络层的底部,传播误差的序列聚合成特征图,将转换特征图为特征序列的操作转换,反馈给卷积层。实际上,我们创造了一个自定义网络层,叫做“Map-to-Sequence”,作为连接CNN和RNN的中间部分。
翻译
翻译是指将每一帧预测为序列标签的过程。从数学层面讲,翻译是将最大概率的结果与每一帧联系在一块。事实上,有两个翻译的模型,一个是不需要词典的,一个是基于词典的。我们引入条件概率来定义CTC,标签序列l对应每一帧的预测y = y1, . . . , yT ,它忽视了每个标签的位置。我们用负似然概率作为目标函数来训练网络,我们仅需要对应的图像和序列标签。避免了单个字符的位置。条件概率简单描述如下:输入序列y = y1, . . . , yT ,T是序列长度。yt是L的概率分布,L包含了任务中的所有标签。序列到序列的映射函数B被定义在序列π ∈ LT,B通过移除相同的元素以及空白进而映射π到l。
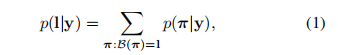
直接计算等式1是不可行的由于累加大的数字,然而它可以通过前-后向传播算法高效的计算。
不基于字典翻译
 在这个模型中,序列l如等式1定义的有最高概率的输出为预测。由于没有易处理的算法能精确的获取结果,l是近似的获得。
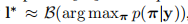
基于字典翻译
在基于字典的模式中,每个测试样例与一个字典D联系起来。通过选择字典中高概率的匹配作为序列结果。然而对于较大的字典,如5w的字典,将是非常耗时的选择。为了解决这个问题,我们使用上一节介绍的非字典方法进行翻译。
网络训练
训练输入是图像和对应的序列标签,目标函数是最小化负的对数似然函数。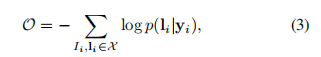
yi是预测的序列结果。整个网络用SGD来训练。通过反向传播算法来计算梯度。在翻译层误差反向传播通过正向反馈算法(论文15描述的),在循环层,反向传播通过BPTT来计算误差。我们用ADADELTA来更新学习率,该方法比动量方法收敛要快。
实验
为了验证提出的CRNN的有效性,我们在标准数据集上做了文本识别和音符识别。
对于所有的场景文本识别任务,我们用合成的数据集Synth作为训练数据集。该数据集包含8百万训练图片以及对应的标注。在该数据集上训练,然后在其他数据集上测试而且没有进行任何的微调,但依然表现的很好。
实验详情
网络配置如下图所示:

整体架构基于VGG,为了适合识别英文文本做了微调,在第三和第四最大池化层,采用12的矩形池化窗口而不是传统的正方形。
整个网络不仅有深度卷积层,还有循环网络层,这使得网络难以训练,我们发现BN策略对训练这样深度的网络非常有用。两个BN层被插入第五和第六个卷积层。用了BN后,训练过程极大的加速。我们用Torch7框架实现了整个网络,实验在K40GPU,64G内存上进行,网络训练用ADADELTA,参数ρ设置为0.9。在整个训练过程中所有的图像固定尺寸到10032来加速训练过程。整个训练用时50个小时达到收敛。测试图片固定高的尺寸为32.宽随着高自动放缩,但至少是100px。