1. рептилии три категории:
Общие Reptile: ползать всю страницу данных
Focused гусеничный: ползет по данным фильтра скрининга, на основе содержимого локальной страницы.
Возрастающие рептилии: сайт рептилии монитор обновленные данные,
2. Что такое обнаружение UA, как взломать?
Обнаружение UA: путем получения запроса на сервер, запрос заголовка приобретения UA путем запроса, путем определения, знает ли значение UA идентичность запрошенных носителей.
Гусеничный инициировать запрашиваемую информацию, замаскированную как запрос браузера
UA представляет собой механизм обнаружения анти-подъем, анти-набор высота соответствует порталу,
Стратегия борьбы с анти-восхождение соответствует программе ползать, трещина восхождение механизм стратегия анти-анти-анти-восхождение
3. Краткие процессы шифрования по протоколу HTTPS?
ключи шифрования сертификата: открытого и закрытого ключей генерируется сервером, сервер отправляет открытый ключ центра сертификации третьей стороной, орган сертификат открытого ключа цифровой подписи, возвращается на сервер в качестве анти-поддельных этикеток, сертификаты и открытые ключи, сервер, а затем отправляется клиенту после того, как ,, аутентификация с открытым ключом шифрования, и клиент подписания цифровой зашифрованный текст на сервер после шифрования.
4. Что такое динамическая загрузка данных? Как ползание данные загружены динамически?
Ajax может загружать динамические данные, иногда некоторые вещи не WYSIWYG, Аякс данных запроса может быть отправлены.
После захвата пакетов по запросу на инструмент АЯКСА захвата пакетов, пакет включает в себя URL сбора параметров, отправляет запрос возвращает строку JSON
Аякса JSON обычно возвращает строку, она может быть и другими типами запросов.
Общие параметры и их влияние получить и пост методы 5.requests модуля?
URL, данные, PARAMS 和 заголовки
6. выпуск 1, IP был закрыт, это со своими горячими точками
Вопрос 2, страница есть проблема? Есть проблемы после 50 страницы, с помощью try..except исключить ненормальные
7. косметика системные службы управления информацией лицензии производство
Глобальный поиск:

Выберите случайный пакет, нажмите Ctrl + F Поиск один, как показано ниже
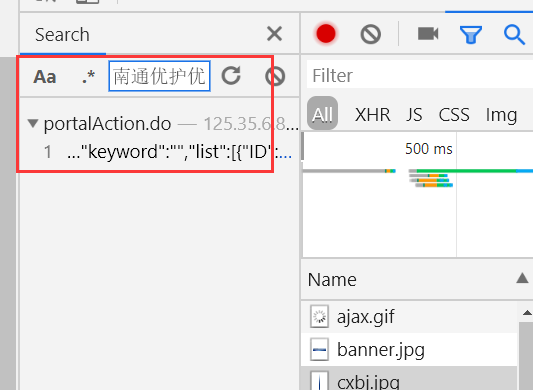
Мы видим, что пакет данных, позиция, как показано ниже:

Лучше всего глобальный поиск, чтобы найти соответствующий пакет поиска
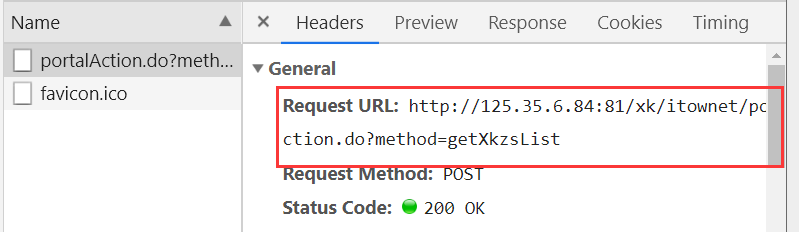
Мы видим глобальные параметры в приведенном ниже рисунке:
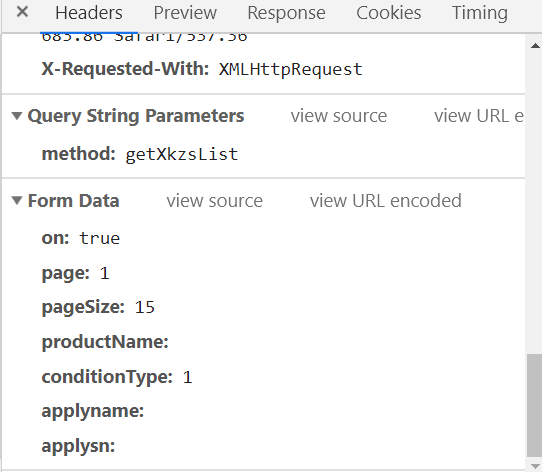
Ответ ссылается на данные отклика.

Фигура представляет собой строку JSON наш ответ, после разбора, мы видим, что идентификатор фиг.
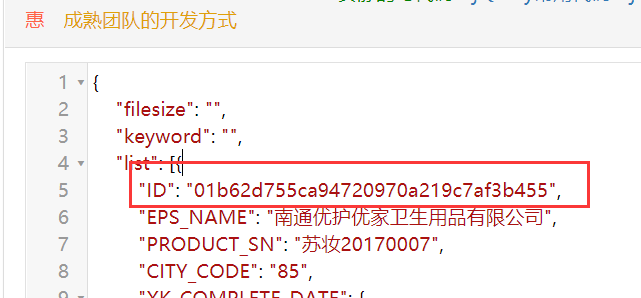
Анализ:
#搜索的地址:http://125.35.6.84:81/xk/ #Request URL: http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList #Request Method: POST # Content-Type: application/json;charset=UTF-8 #User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36 #Form Data #参数 # on: true # page: 1 # pageSize: 15 # productName: # conditionType: 1 # applyname: # applysn:
分析: (1)通过抓包工具检测出首页中的企业信息数据全部为动态加载 (2)通过抓包工具获取动态加载数据对应的ajax的数据包(url,请求参数) (3)通过对步骤2的url请求后获取的响应数据中分析出有一个特殊的字段ID(每家企业都有一个唯一的ID值) (4)从手动点击企业进入企业的详情页,发现浏览器地址栏中的url中包含了该企业的ID和固定的域名可以拼接成详情页的url (5)发现详情页的企业详情信息对应的数据值是动态加载出来的.上述我们获取详情页中的url是无用的. (6)通过抓包工具的全局搜索的功能,可以定位到企业详情信息对应的ajax数据包(url,请求参数),对应的响应数据就是最终我们想要爬取的企业详细数据. 注意:先写思路,再写程序 程序需要先一点点写,再写出全部. 写一步执行一步.
import requests headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } #第一请求的url地址 first_url='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList' ids=[] #如何爬取前10页的数据?,双击选中 for page in range(1,11): data={ "on": "true", "page": str(page), "pageSize": "15", "productName": "", "conditionType": "1", "applyname": "", "applysn": "", } #json_obj=requests.post(url=first_url,data=data,headers=headers).json() response=requests.post(url=first_url,data=data,headers=headers) #响应对象 #response.headers返回的是响应头信息(字典) if response.headers['Content-Type']=='application/json;charset=UTF-8': json_obj=response.json() for dic in json_obj['list']: ids.append(dic['ID']) #print(ids) #这个时候我们已经获取到了id detail_url='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' for _id in ids: data={ 'id':_id } company_text=requests.post(detail_url,data=data,headers=headers).text print(company_text)
抓取的数据是下面的内容: