
Адрес статьи : https://arxiv.org/abs/2307.03109
Адрес Github : https://github.com/MLGroupJLU/LLM-eval-survey
1. История
С появлением ChatGPT и GPT-4 модели больших языков (LLM) набирают популярность как в академических кругах, так и в промышленности, в основном благодаря их беспрецедентной производительности в различных приложениях . Поскольку LLM продолжают играть важную роль в исследованиях и повседневном использовании, их оценка становится все более важной. За последние несколько лет люди провели много исследований LLM с разных точек зрения (таких как задачи естественного языка, рассуждения, надежность, надежность, медицинские приложения и этические соображения и т. д. ), как показано на рисунке 2 ниже:
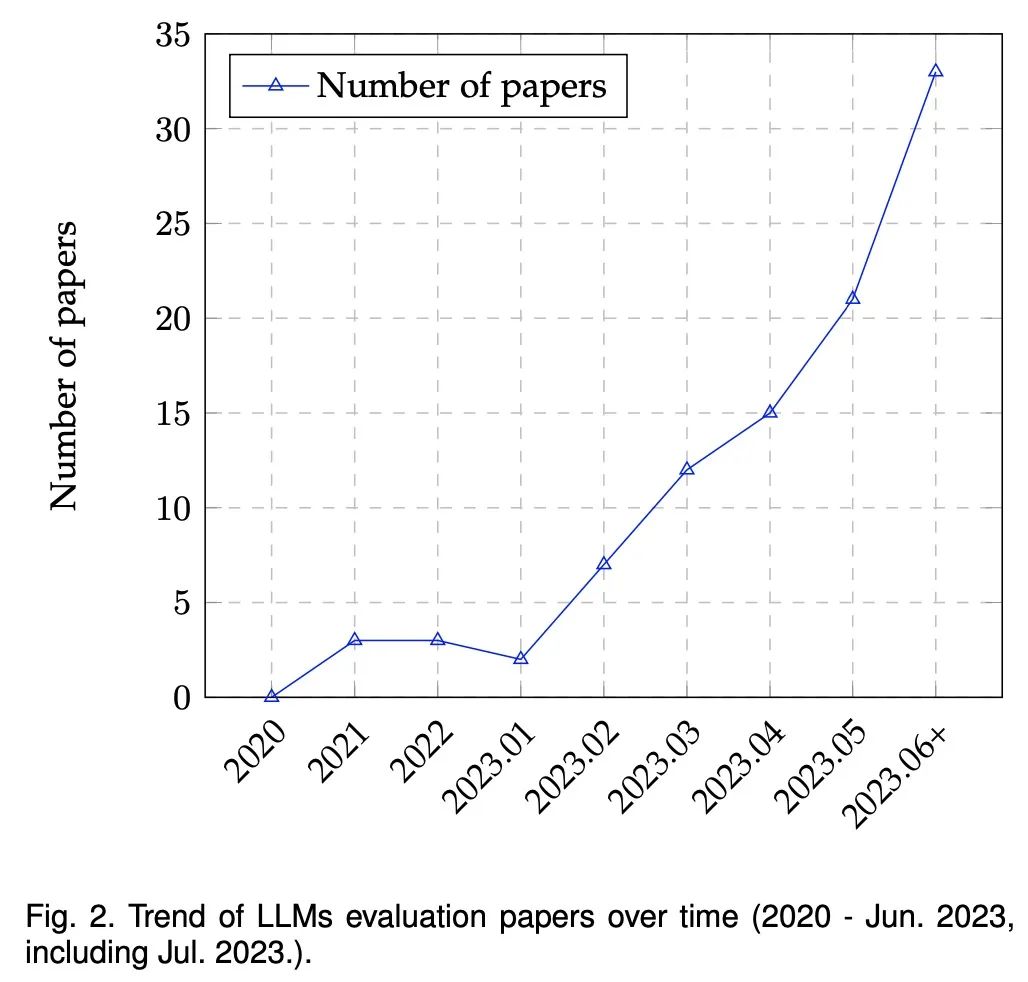
Несмотря на многочисленные усилия, всеобъемлющий обзор всего спектра оценок все еще отсутствует. Кроме того, продолжающаяся эволюция LLM представляет новые аспекты оценки, тем самым бросая вызов существующим протоколам оценки и усиливая потребность в тщательных, многогранных методах оценки. Хотя существующие исследования, такие как (Bubeck et al., 2023), утверждают, что GPT-4 можно считать искрой AGI, другие ставят это под сомнение из-за искусственного характера его методов оценки.
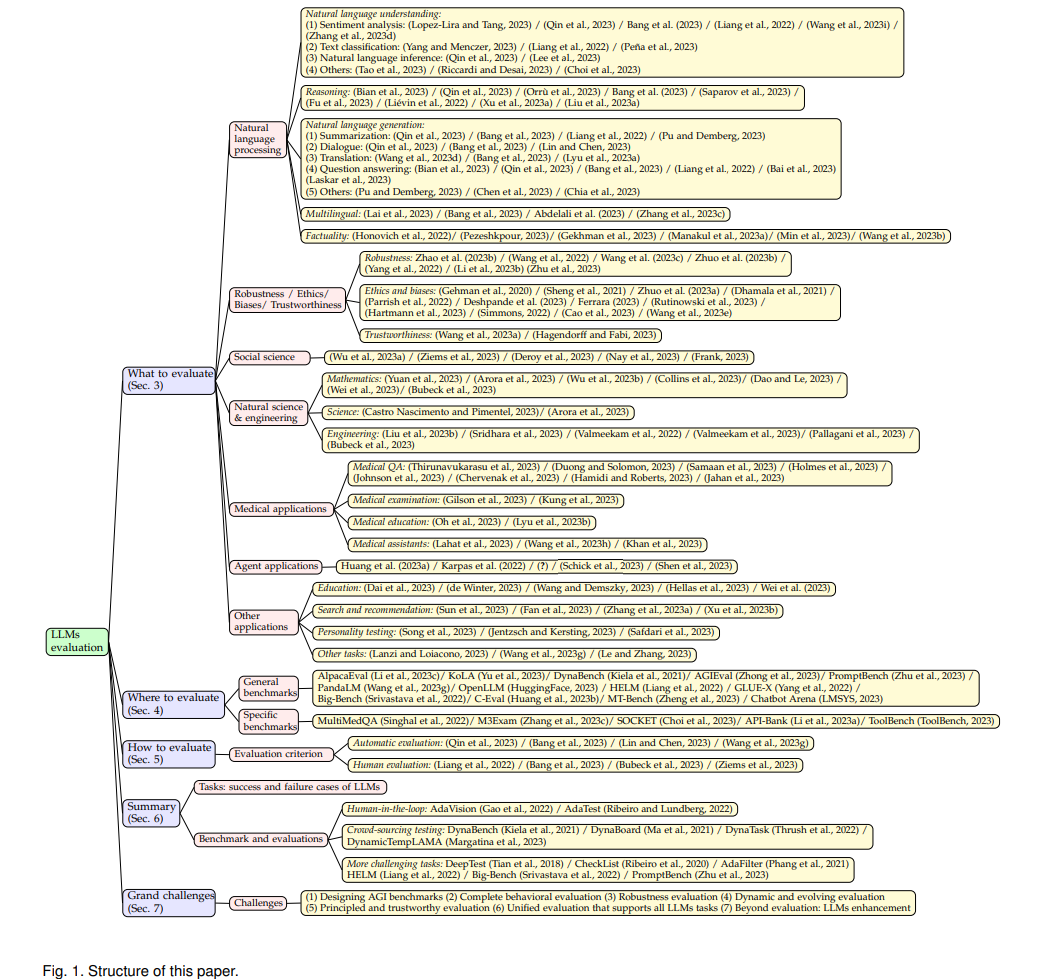
В этом документе представлен всесторонний обзор этих методов оценки LLM с упором на три основных аспекта: что оценивать, где оценивать и как оценивать . Во-первых , представлен обзор с точки зрения задач оценки, включая общие задачи обработки естественного языка, рассуждения, медицинские приложения, этику, образование, естественные и социальные науки, агентские приложения и другие области. Во-вторых , вопросы «где» и «как» оцениваются путем углубления в методы оценки и контрольные показатели, которые являются ключевыми компонентами оценки эффективности LLM. Затем суммируются случаи успеха и неудачи LLM в различных задачах. Наконец , обсуждаются некоторые будущие проблемы для оценки LLM.
2. Базовые знания больших языковых моделей
Языковые модели (LM) — это вычислительные модели, способные понимать и генерировать человеческий язык. LM обладают преобразующей способностью предсказывать вероятность последовательностей слов или генерировать новый текст с учетом входных данных. Модели N-грамм являются наиболее распространенным типом LM, которые оценивают вероятности слов на основе предшествующего контекста. Однако LM также сталкиваются с проблемами, такими как проблема редких или невидимых слов, проблема переобучения и сложность фиксации сложных языковых явлений. Параметры традиционных LM невелики, а модель после GPT-3 доказывает, что появляются модели с параметрами более 10B (хотя в некоторых работах доказано, что это может быть проблема дизайна Prompt, но способность модели к обобщению действительно намного сильнее, чем у предыдущей модели), такие как GPT-3, InstructGPT и GPT-4 и т. д., их основным модулем является модуль самоконтроля в Transformer, который является основным строительным блоком для задач языкового моделирования. Преобразователи произвели революцию в области NLP, обрабатывая последовательные данные более эффективно, чем RNN и CNN, обеспечивая распараллеливание и фиксируя удаленные зависимости в тексте.
Ключевой особенностью LLM является обучение на основе контекста, когда модель обучается генерировать текст на основе заданного контекста или реплики. Это позволяет LLM генерировать более согласованные и контекстно-зависимые ответы, что делает их подходящими для интерактивных и диалоговых приложений. Обучение с подкреплением на основе обратной связи с человеком (RLHF) — еще один ключевой аспект LLM. Этот метод включает в себя точную настройку модели с использованием обратной связи, созданной человеком, в качестве вознаграждения, что позволяет модели учиться на своих ошибках и со временем улучшать свою производительность.
В авторегрессионных языковых моделях, таких как GPT-3 и PaLM, при заданной последовательности контекста X задача LM направлена на предсказание следующей лексемы y. Модель обучается путем максимизации вероятности последовательности токенов, обусловленной контекстом, т. Е. P (y | X) = P (y | x1, x2, ..., xt-1), где x1, x2, ..., xt-1 — токены в контекстной последовательности, а t — текущая позиция. Используя цепное правило, условную вероятность можно разложить на произведение условной вероятности каждого токена с учетом его предыдущего контекста, т. Е.
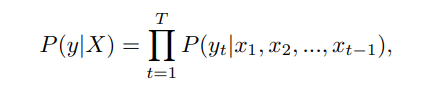
где T — длина последовательности. Таким образом, модель авторегрессивно предсказывает каждый токен в каждом месте, создавая полную последовательность текста. Обычным подходом к взаимодействию с LLM является разработка подсказок, когда пользователи разрабатывают и предоставляют конкретные тексты подсказок, чтобы помочь LLM генерировать желаемые ответы или выполнять определенные задачи. Это широко применяется в существующей работе по оценке. Люди также могут участвовать во взаимодействии вопросов и ответов, когда они задают вопросы модели и получают ответы, или участвуют в диалоговых взаимодействиях, когда они общаются с LLM на естественном языке.
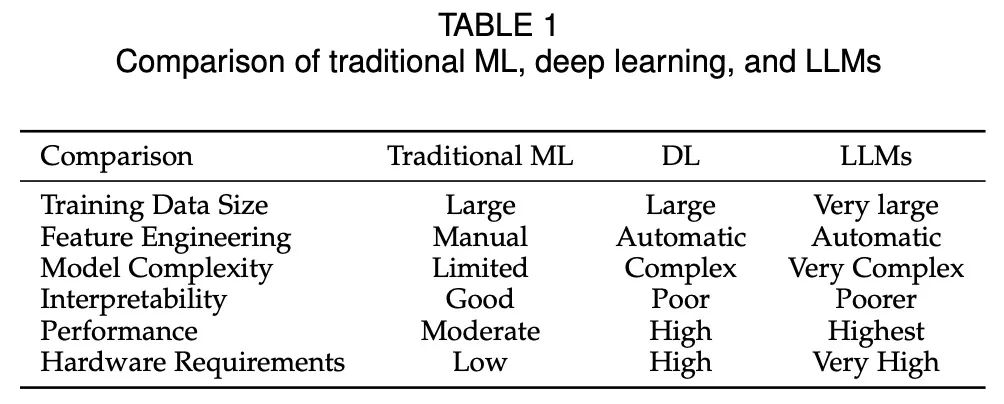
В целом, LLM произвели революцию в NLP благодаря своей архитектуре Transformer, контекстному обучению и возможностям RLHF, и они перспективны в различных приложениях. В таблице 1 представлено краткое сравнение традиционного машинного обучения, глубокого обучения и LLM.
3. Что оценивать
На каких задачах мы должны оценивать производительность LLM? В этом разделе мы разделяем существующие задачи на следующие категории: задачи обработки естественного языка, этика и предвзятость, медицинские приложения, социальные науки, естественнонаучные и инженерные задачи, агентские приложения (с использованием LLM в качестве агентов) и другие.
3.1 Задачи обработки естественного языка
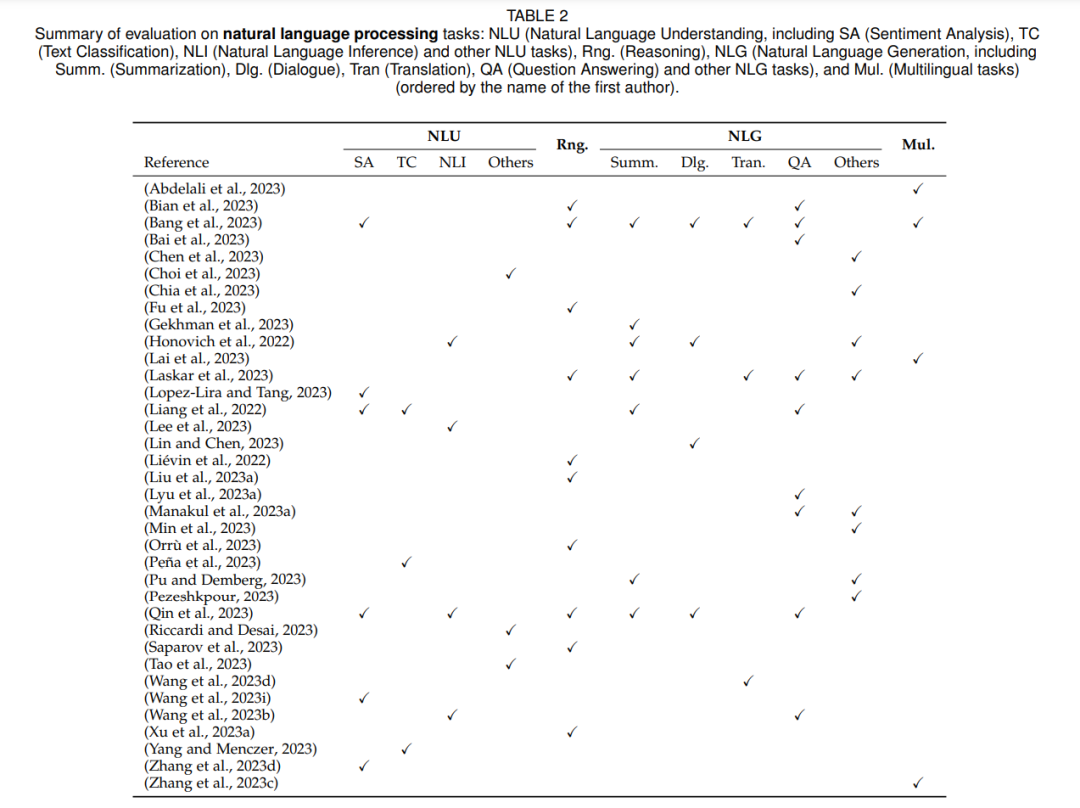
Первоначальная цель больших языковых моделей заключалась в повышении производительности задач обработки естественного языка, включая понимание естественного языка, вывод, генерацию, многоязычные задачи и аутентичность естественного языка. Поэтому большинство оценочных исследований в основном сосредоточены на задачах на естественном языке. Результаты оценки представлены в Таблице 2 ниже:
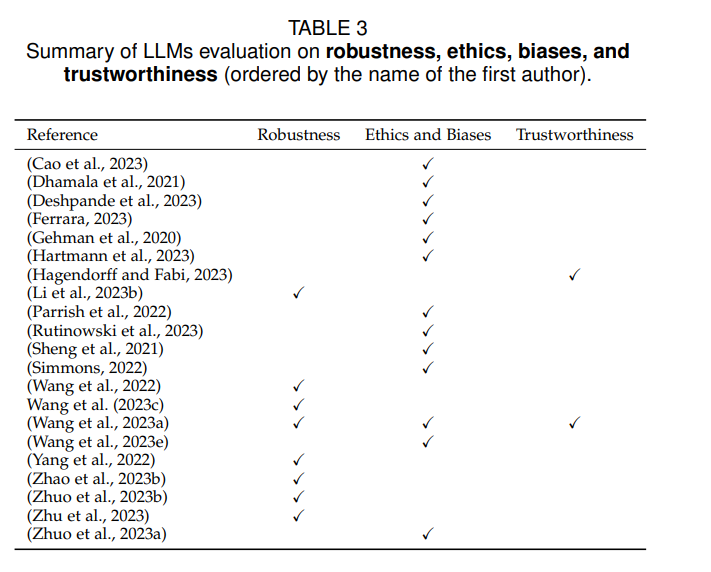
3.2 Надежность, этичность, предвзятость и надежность
Оценка LLM включает такие ключевые аспекты, как надежность, этичность, предвзятость и надежность. Эти факторы приобретают все большее значение при всесторонней оценке эффективности LLM.
3.3 Социальные науки
Социальные науки включают изучение человеческого общества и индивидуального поведения, включая экономику, социологию, политологию, право и другие дисциплины. Оценка эффективности LLM в социальных науках важна для академических исследований, разработки политики и решения социальных проблем. Такие оценки могут помочь улучшить применимость и качество моделей в социальных науках, улучшить понимание человеческих обществ и способствовать социальному прогрессу.
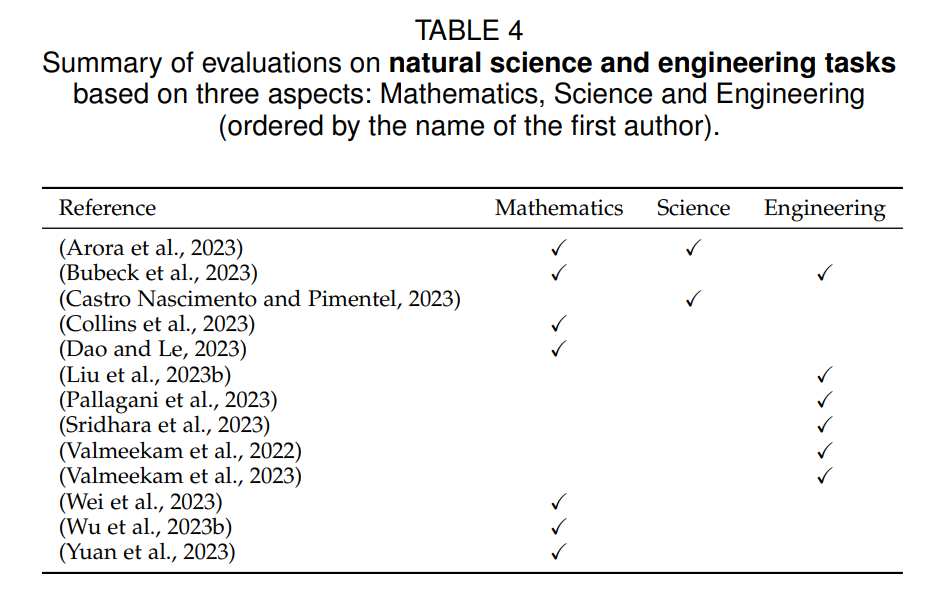
3.4 Естественные науки и инженерия
Оценка эффективности LLM в области естественных и инженерных наук может помочь в применении и развитии научных исследований, развитии технологий и инженерных исследованиях.
3.5 Медицинское применение
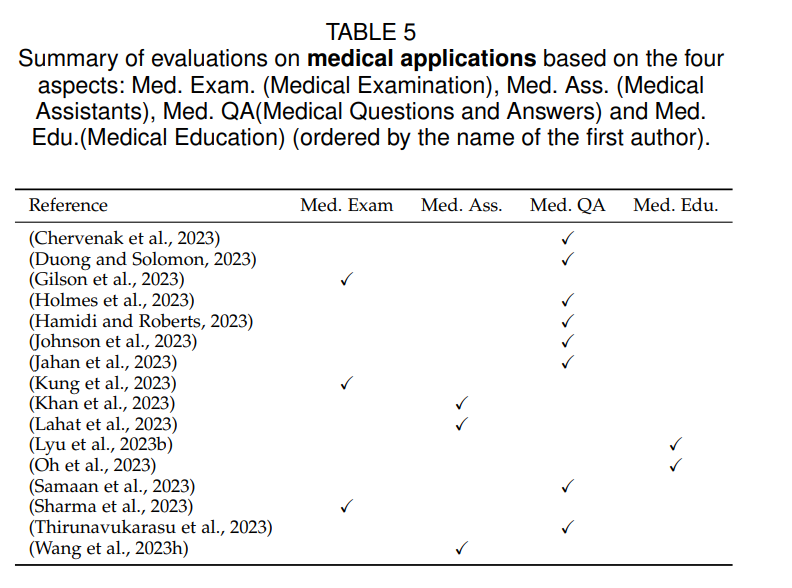
В последнее время большое внимание уделяется применению LLM в области медицины. В этом разделе мы рассмотрим существующую работу по применению LLM в медицинских приложениях. В частности, мы сгруппировали их по четырем аспектам, показанным в Таблице 5: ответы на медицинские вопросы, медицинский осмотр, медицинская оценка и медицинское образование.
3.6 Прокси-приложение
LLM ориентированы не только на общие языковые задачи, их можно использовать как мощные инструменты в различных областях. Оснащение LLM внешними инструментами может значительно расширить возможности модели. Например, КОСМОС-1, который может понимать общие закономерности, следовать инструкциям для обучения и учиться в зависимости от контекста. Карпас и др. подчеркивают, что крайне важно знать, когда и как использовать эти внешние символические инструменты, и что это знание определяется возможностями LLM, особенно когда эти инструменты могут работать надежно. Кроме того, два других исследования, Toolformer и TALM, изучают возможность использования инструментов для расширения языковых моделей. Toolformer использует обучающий подход для определения наилучшего использования конкретного API и интегрирует полученные результаты в последующие прогнозы токенов. TALM, с другой стороны, сочетает неразличимые инструменты с текстовыми подходами к расширению языковых моделей и использует итеративный метод, называемый «самостоятельная игра», управляемый минимальными демонстрациями инструментов. Шен и др. предложили инфраструктуру HuggingGPT, которая использует LLM для соединения различных моделей ИИ (таких как Hugging Face) в сообществе машинного обучения с целью решения задач ИИ.
3.7 Другие приложения
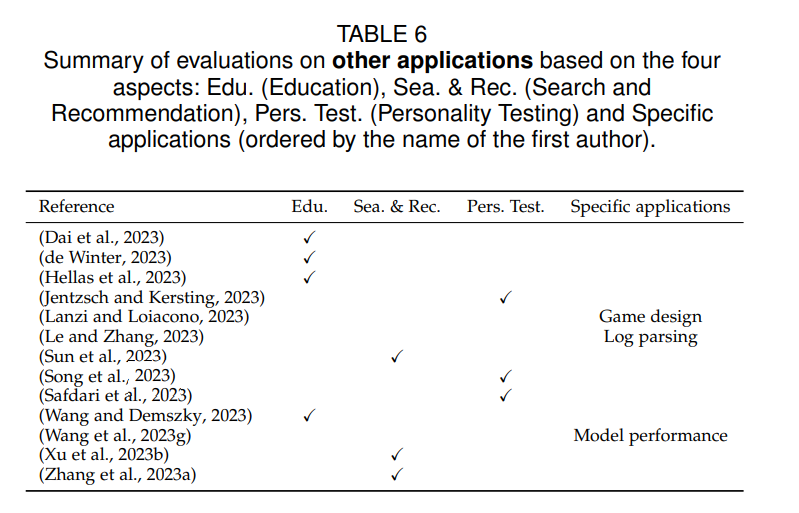
В дополнение к вышеуказанным классификациям LLM оценивались в ряде других областей, включая образование, поиск и рекомендации, личностное тестирование и конкретные приложения, среди прочего.
4. Где оценивать: наборы данных и контрольные показатели
Набор оценочных данных для тестирования LLM используется для тестирования и сравнения производительности различных языковых моделей в различных задачах, как показано в разделе 3. Эти наборы данных, такие как GLUE и SuperGLUE, предназначены для моделирования реальных сценариев обработки языка и охватывают различные задачи, такие как классификация текста, машинный перевод, понимание прочитанного и создание диалогов. В этом разделе обсуждается не какой-либо отдельный набор данных для языковых моделей, а сравнительные тесты для LLM. Поскольку тесты для LLM развиваются, мы перечисляем 19 популярных тестов в Таблице 7.5. Каждый эталон фокусируется на различных аспектах и критериях оценки, внося ценный вклад в соответствующую область. Для лучшего обобщения мы разделим эти тесты на две категории: тесты для общих языковых задач и тесты для конкретных последующих задач.

5. Как оценить
В этом разделе мы представляем два распространенных метода оценки: автоматическую оценку и оценку человеком. На самом деле, классификация «как оценивать» также неопределенна. Наша классификация основана на возможности автоматического расчета критериев оценки. Если она может быть рассчитана автоматически, мы классифицируем ее как автоматизированную оценку, в противном случае это человеческая оценка.
5.1 Автоматическая оценка
Автоматическая оценка больших языковых моделей является распространенным и, вероятно, самым популярным методом оценки, обычно использующим стандартные метрики или индикаторы и инструменты оценки для оценки производительности модели, такие как точность, BLEU, ROUGE, BERTScore и т. д. Например, мы можем использовать баллы BLEU для количественной оценки сходства и качества сгенерированного моделью текста с справочным текстом в задачах машинного перевода. Действительно, в большинстве существующих методов оценки используется этот протокол оценки из-за его субъективности, автоматического расчета и простоты. Поэтому большинство детерминированных задач, таких как понимание естественного языка и математические задачи, обычно используют этот протокол оценки. По сравнению с оценкой вручную, автоматическая оценка не требует участия человека, что снижает затраты на оценку и занимает меньше времени. Например, и Бэнг и др. оба используют автоматические методы оценки для оценки большого количества задач. В последнее время, с развитием LLM, некоторые передовые методы автоматической оценки также предназначены для помощи в оценке. Лин и Чен предложили LLM-EVAL, унифицированный многомерный метод автоматической оценки для открытого диалога с LLM. PandaLM обеспечивает воспроизводимую автоматическую оценку языковых моделей, обучая LLM в качестве «арбитра», который используется для оценки различных моделей. Из-за большого количества автоматизированных оценочных работ мы не будем подробно их рассматривать. Принцип автоматической оценки на самом деле такой же, как и в других процессах оценки модели ИИ: мы просто используем некоторые стандартные метрики для расчета некоторых значений по этим метрикам, которые служат индикаторами производительности модели.
5.2 Человеческая оценка
Возможности LLM превзошли стандартные показатели оценки общих задач на естественном языке. Поэтому в некоторых нестандартных ситуациях, когда автоматическая оценка неприменима, человеческая оценка становится естественным выбором. Например, в задачах открытого поколения встроенных мер подобия, таких как BERTScore, недостаточно, и оценка человека более надежна. В то время как некоторые задачи генерации могут использовать некоторый протокол автоматической оценки, в этих задачах предпочтительна оценка человеком, потому что генерация всегда может быть лучше, чем наземная правда. Человеческая оценка LLM - это способ оценить качество и точность результатов, полученных с помощью модели, с участием человека. По сравнению с автоматической оценкой ручная оценка ближе к реальному сценарию приложения и может обеспечить более полную и точную обратную связь. При ручной оценке LLM оценщикам (например, экспертам, исследователям или обычным пользователям) обычно предлагается оценить результаты, полученные с помощью модели. Например, Зимс и др. использовали экспертные аннотации для генерации. При оценке человека Лян и др. выполнили оценку человеком сценариев обобщения и дезинформации 6 моделей, а Банг и др. оценили задачу рассуждения по аналогии. Новаторская оценочная работа, проведенная Бубеком и др., использовала GPT-4 для проведения серии тестов на людях, и они обнаружили, что GPT-4 работает близко или даже превосходит человеческие возможности при выполнении множества задач. Эта оценка требует, чтобы оценщики фактически тестировали и сравнивали производительность моделей, а не просто оценивали модели с помощью автоматизированных показателей оценки. Следует отметить, что даже человеческая оценка может иметь высокую дисперсию и нестабильность, что может быть связано с культурными и индивидуальными различиями Peng et al. В практических приложениях эти два метода оценки будут рассмотрены и взвешены в соответствии с реальной ситуацией.
6. Резюме
В этом разделе обобщаются случаи успеха и неудачи LLM в различных задачах.
6.1 В каких областях LLM могут преуспеть?
- LLM демонстрируют умение генерировать текст, создавая беглые и точные лингвистические выражения.
- LLM преуспевают в понимании языка и способны решать такие задачи, как анализ тональности и классификация текста.
- LLM обладают сильным контекстуальным пониманием и способны генерировать последовательные ответы, соответствующие входным данным.
- LLM продемонстрировали впечатляющую производительность в нескольких задачах обработки естественного языка, включая машинный перевод, генерацию текста и задачи ответов на вопросы.
6.2 При каких обстоятельствах LLM могут выйти из строя?
- LLM могут демонстрировать смещение и неточность во время генерации, что приводит к смещению вывода.
- LLM ограничены в своей способности понимать сложные логические и логические задачи, и в сложных средах часто возникают путаница или ошибки.
- LLM сталкиваются с ограничениями при работе с большими наборами данных и долговременной памятью, что может создавать проблемы при обработке длинного текста и задач, связанных с долгосрочными зависимостями.
- LLM имеют ограничения в интеграции информации в реальном времени или динамической информации, что делает их менее подходящими для задач, требующих актуальных знаний или быстрой адаптации к изменяющимся условиям.
- LLM очень чувствительны к сигналам, особенно состязательным сигналам, которые запускают новые оценки и алгоритмы для повышения их надежности.
- В области суммирования текста можно заметить, что LLM могут демонстрировать неудовлетворительную производительность по конкретным метрикам оценки, что может быть связано с внутренними ограничениями или недостатками этих конкретных метрик.
- LLM не могут достичь удовлетворительной производительности при выполнении контрфактических задач.
7. Основные проблемы
Оценка как новая дисциплина: наш обзор оценок больших моделей вдохновил нас на переработку многих аспектов. В этом разделе мы представляем следующие 7 больших задач.
- Разработка контрольных показателей AGI: что такое надежные, заслуживающие доверия и вычисляемые показатели оценки, которые правильно измеряют задачи AGI?
- Разработка контрольных показателей AGI для поведенческих оценок: помимо стандартных задач, как можно измерить AGI для других задач, таких как взаимодействие с роботом?
- Оценка надежности: текущая большая модель не устойчива к подсказке ввода, как построить лучший критерий оценки надежности?
- Оценка динамической эволюции: возможности больших моделей постоянно развиваются, а также существует проблема запоминания обучающих данных. Как разработать более динамичный и эволюционный метод оценки?
- Надежная оценка: как убедиться, что разработанные критерии оценки заслуживают доверия?
- Поддержка унифицированной оценки всех задач больших моделей: оценка больших моделей не является конечной точкой, как интегрировать схему оценки с последующими задачами, связанными с большими моделями?
- Помимо простой оценки: улучшение больших моделей: после оценки преимуществ и недостатков больших моделей, как разработать новые алгоритмы для повышения их производительности в определенных аспектах?
8. Заключение
Оценка имеет далеко идущие последствия и стала критически важной для развития моделей ИИ, особенно больших языковых моделей. В этом документе представлен первый обзор, в котором представлен всесторонний обзор оценки LLM по трем параметрам: что оценивать, как оценивать и где оценивать. Наша цель — улучшить понимание текущего состояния LLM путем инкапсуляции задач оценки, протоколов и контрольных показателей, прояснить их сильные и слабые стороны, а также предоставить информацию для будущих улучшений LLM. Наш обзор показывает, что современные LLM несколько ограничены во многих задачах, особенно в задачах логического вывода и надежности. В то же время потребность в адаптации и развитии современных систем оценки остается очевидной для обеспечения точной оценки внутренних возможностей и ограничений LLM. Мы определяем несколько серьезных проблем, которые должны быть решены в будущих исследованиях, с надеждой, что LLM смогут постепенно улучшать свои услуги человечеству.