1. Описание
Большая языковая модель (вики: LLM — большая языковая модель ) — языковая модель, характеризующаяся большим размером. Их масштаб обеспечивается ускорителями ИИ, способными обрабатывать огромные объемы текстовых данных, в основном взятых из Интернета. Искусственные нейронные сети, созданные [1], могут содержать от десятков миллионов до миллиардов весов и (предварительно) обучаются с использованием самоконтролируемого и частично контролируемого обучения. Архитектура-трансформер помогает ускорить обучение. [2] Альтернативные архитектуры включают Mixture of Experts (MoE), предложенную Google, начиная с Sparse Gated Architecture в 2017 г., [3] Gshard в 2021 г. [4] и заканчивая GLaM в 2022 г.
Как языковые модели, они работают, беря входной текст и многократно предсказывая следующую лексему или слово. [6] К 2020 году точная настройка станет единственным способом выполнения конкретной задачи моделью. Однако модели большего размера, такие как GPT-3, можно быстро разработать для достижения аналогичных результатов. [7] Считается, что они приобретают специальные знания о синтаксисе, семантике и «онтологии», присущие корпусам человеческих языков, а также о неточностях и предубеждениях, присутствующих в корпусе. [8]
2. История развития метрик
В начале 1600-х годов математик и астроном по имени Эдмунд Гюнтер столкнулся с беспрецедентными астрономическими проблемами. Для расчета сложных движений планет и предсказания солнечных затмений требуется нечто большее, чем интуиция — требуется владение сложными логарифмическими и тригонометрическими уравнениями. Итак, как и любой сообразительный новатор, Гюнтер решил построить его с нуля! Он создал аналоговое вычислительное устройство, которое со временем стало так называемой логарифмической линейкой .
Логарифмическая линейка представляет собой прямоугольный деревянный брусок длиной 30 см и состоит из двух частей: неподвижной рамы и выдвижной части. На неподвижной рамке находится фиксированная логарифмическая шкала, а на подвижной части — подвижная шкала. Чтобы использовать логарифмическую линейку, вам необходимо понимать основы логарифмов и то, как выровнять шкалы для умножения, деления и других математических операций. Вы должны сдвинуть подвижную часть, чтобы выровнять установленные числа, прочитать результат и учесть размещение десятичной точки. Ой, это действительно сложно!

Примерно 300 лет спустя, в 1961 году, корпорация Belpanch представила «ANITA Mk VII», первый настольный электронный калькулятор. В течение следующих нескольких десятилетий электронные калькуляторы стали более сложными, с дополнительными функциями. Работа, которая ранее требовала обширных ручных вычислений, резко сократила количество человеко-часов, освободив сотрудников, чтобы сосредоточиться на более аналитических и творческих аспектах своей работы. Таким образом, современные электронные калькуляторы не только изменили должностные обязанности, но и проложили путь к улучшению навыков решения задач.
Калькуляторы — это шаг вперед в том, как делается математика. Как насчет языка?
3. Измерение языка только началось
Подумайте о том, как вы генерируете предложения. Сначала нужно иметь идею. Далее нужно знать кучу слов (лексикон). Затем вам нужно уметь ставить их в правильные предложения (грамматика). Тск, это снова довольно сложно!

То, как мы генерируем языковые слова, восходит к 500 000 лет назад, когда современный Homo sapiens впервые создал язык.
Честно говоря, мы все еще живем в те дни, когда Гюнтер использовал логарифмическую линейку при построении предложений!
Если подумать, использование правильной лексики и грамматики в основном простое следование правилам. правила языка.
Это похоже на математику. Он полон правил. Отсюда я могу быть уверен, что 1+1=2 и почему калькулятор работает!
Нам нужен калькулятор, но для текста!
Да, разные языки подчиняются разным правилам, но для понимания необходимо соблюдать некоторые правила. Явное различие между языком и математикой заключается в том, что у математики есть фиксированные ответы, тогда как количество разумных слов, которые могут поместиться в предложение, может быть большим.
Попробуйте закончить следующие предложения: Я съел ________. Представьте слова, которые могут быть следующими. В английском около 10 000 слов. Многие из них доступны здесь, но определенно не все.
Ответ «черные дыры» эквивалентен утверждению 2+2=5. Кроме того, ответ «Apple» неверен. Почему? Из-за грамматики!

За последние несколько месяцев большие языковые модели (LLM) покорили мир. Одни называют это прорывом в обработке естественного языка, другие видят в этом зарю новой эры искусственного интеллекта (ИИ).
LLM отлично зарекомендовал себя в генерации текста, похожего на человеческий, поднимая планку для языковых приложений ИИ. Обладая обширной базой знаний и пониманием контекста, LLM может применяться в различных областях, от языкового перевода и создания контента до виртуальных помощников и чат-ботов поддержки клиентов.
Вопрос в том, находимся ли мы в настоящее время в точке перегиба LLM, как это было с электронными калькуляторами в 1960-х годах?
Как работает LLM, прежде чем мы ответим на этот вопрос? LLM основан на нейронной сети преобразователя для вычисления и прогнозирования следующего наиболее подходящего слова. Чтобы построить мощную нейросеть-трансформер, нужно обучить ее на большом количестве текстовых данных. Вот почему подход «предсказать следующее слово/токен» работает так хорошо: доступно множество обучающих данных. LLM принимают в качестве входных данных всю последовательность слов и предсказывают следующее наиболее вероятное слово. Чтобы понять, что, скорее всего, произойдет дальше, они в качестве разминки проглатывают всю Википедию, затем обращаются к грудам книг и, наконец, ко всему Интернету.
Ранее мы установили, что языки содержат правила и шаблоны. Модель неявно изучает эти правила, проходя через все эти предложения, которые она будет использовать для выполнения задачи предсказания следующего слова.
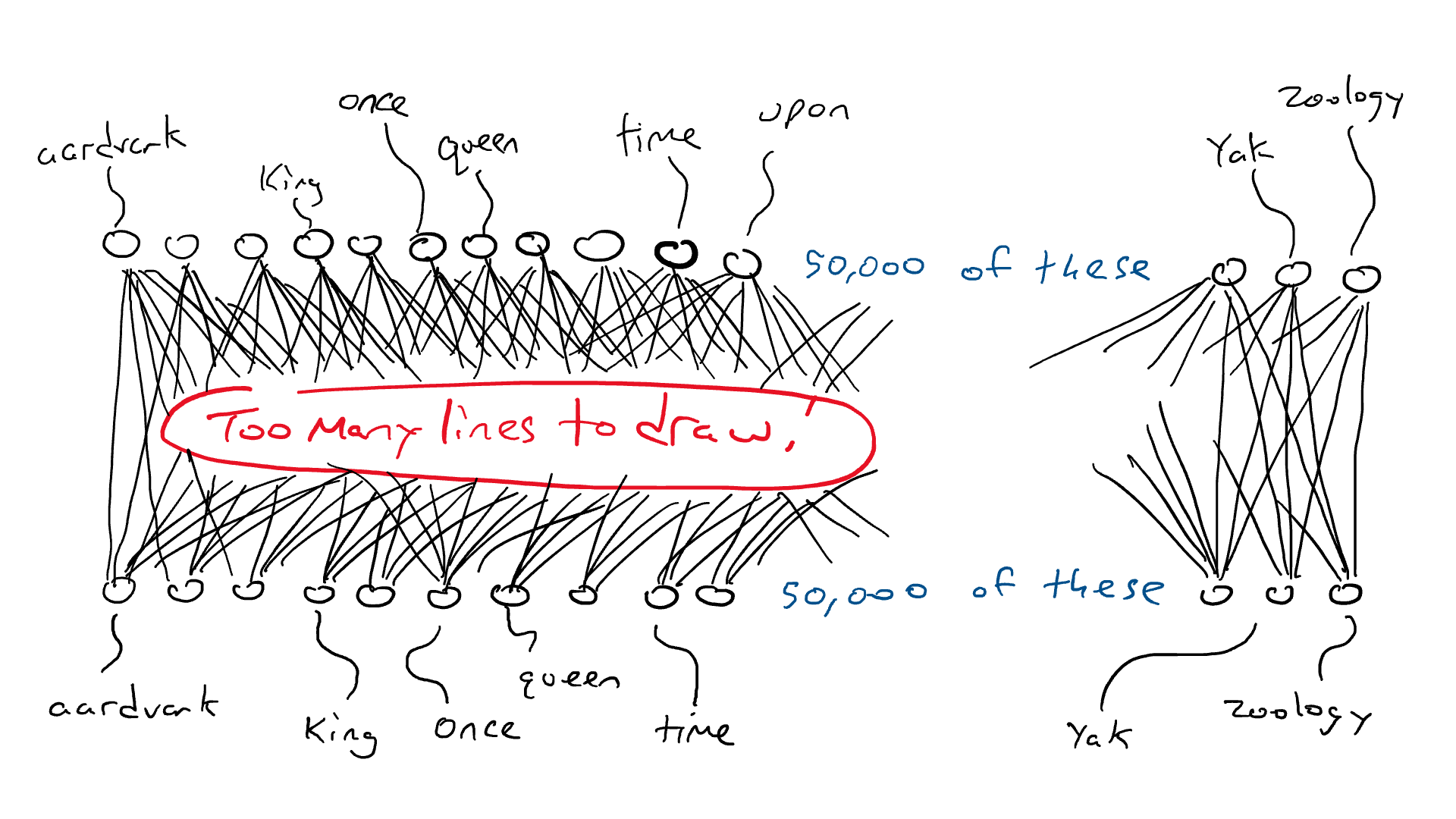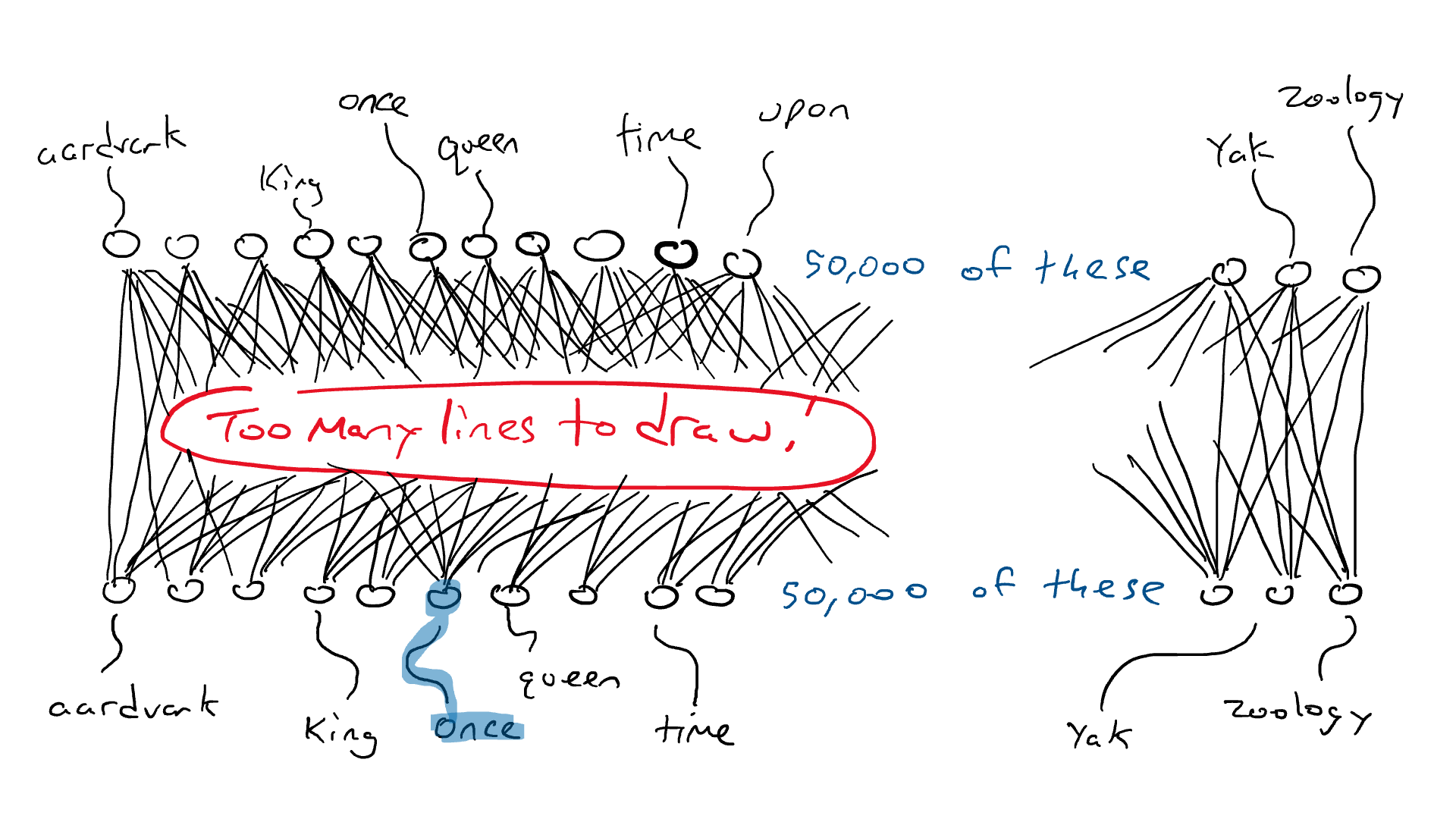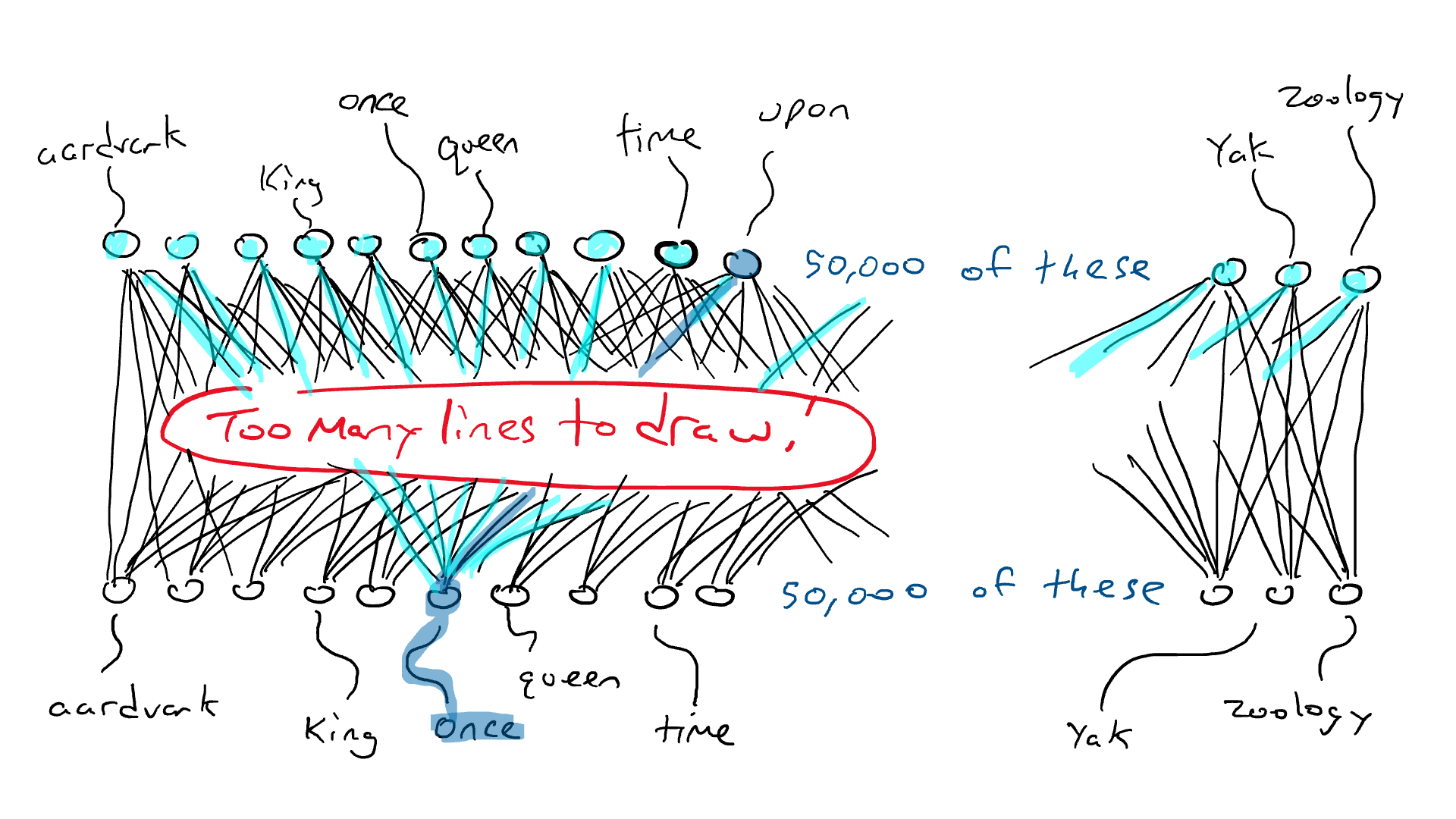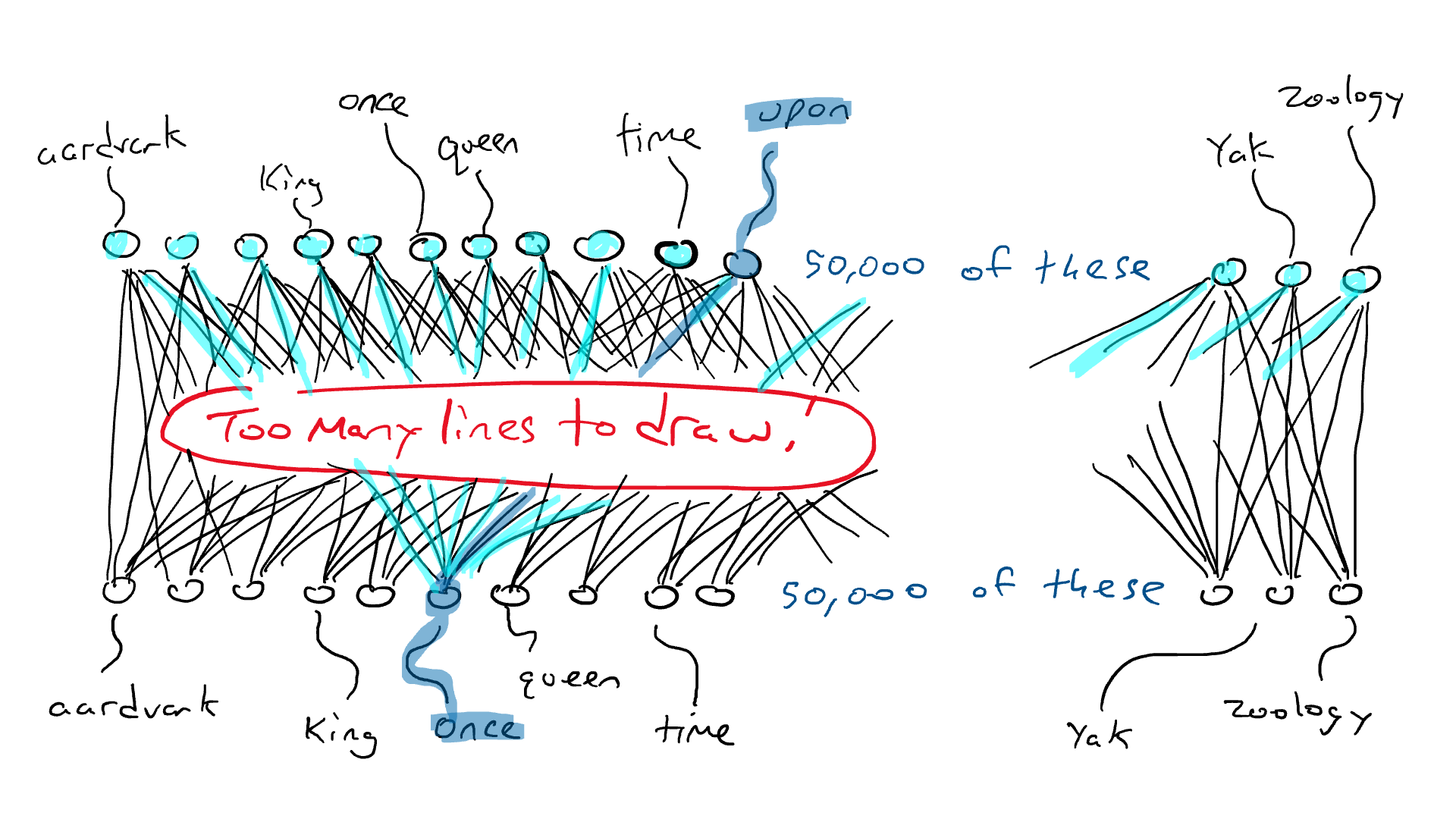
После существительного в единственном числе увеличивается вероятность того, что следующим словом будет глагол, оканчивающийся на «s». Точно так же шансы увидеть такие слова, как «делает» и «почему», увеличиваются при чтении Шекспира.
Во время обучения модель изучает эти языковые шаблоны и в итоге становится экспертом!
Но достаточно ли? Достаточно ли выучить языковые правила?

Отсюда и самофокус. Проще говоря, само-внимание — это метод, используемый LLM для понимания связи между разными словами в предложении или фрагменте текста. Точно так же, как вы сосредотачиваетесь на разных частях истории, чтобы понять ее, само-внимание позволяет LLM придавать больший вес определенным словам в предложении при обработке информации. Таким образом, модель может лучше понимать общий смысл и контекст текста , а не просто слепо предсказывать следующее слово на основе правил языка.

Если LLM — это калькулятор слов, который просто предсказывает следующее слово, как он может ответить на все мои вопросы?
Когда вы просите большую языковую модель сделать что-то умное — и это работает — есть большая вероятность, что вы просите ее сделать что-то, что она видела в тысячах примеров. Даже если вы придумаете что-то действительно уникальное, например:
«Напиши мне стихотворение о том, как косатка ест курицу»
В волнах, незримое зрелище, косатка охотится, стремительна и резка, а в царстве океана начинается танец, и по воле курицы побеждает косатка.
Он бьет добычу своими мощными челюстями, его перья развеваются, он дрейфует естественным образом, сплетая историю, в которой жизнь и смерть сливаются воедино.
~ чат
Очень мило, правда? Благодаря своему механизму внутреннего внимания он может эффективно смешивать и сопоставлять соответствующую информацию для создания правдоподобных и последовательных ответов.
Во время обучения LLM учатся распознавать закономерности, ассоциации и отношения между словами и фразами в данных, с которыми они сталкиваются. В результате этого обширного обучения и тонкой настройки LLM могут проявлять новые свойства, такие как способность выполнять языковой перевод, обобщение, ответы на вопросы и даже творческое письмо. Эти функции часто выходят за рамки явного программирования в модели и могут быть весьма блестящими!
Умны ли большие языковые модели?
Электронные калькуляторы существуют уже более шестидесяти лет. Сам инструмент совершенствовался как на дрожжах, но он никогда не считался умным. Почему?
Тест Тьюринга. Тест Тьюринга — это обманчиво простой метод определения того, обладает ли машина интеллектом, подобным человеческому: если машина может поддерживать разговор с человеком способом, неотличимым от человеческого, считается, что она обладает человеческим интеллектом.
Калькулятор никогда не тестировался Тьюрингом , потому что он не общается на том же языке, что и люди, а только на языке математики. С другой стороны, LLM производит человеческий язык. Весь его учебный процесс вращается вокруг имитации человеческой речи. Поэтому неудивительно, что он может «разговаривать с людьми так, как неотличимы от людей».
Поэтому использовать слово «интеллект» для описания LLM немного сложно, потому что нет четкого консенсуса относительно того, что на самом деле означает интеллект. Один из способов понять, является ли что-то разумным, — это сделать что-то интересное, полезное и не очень очевидное. LLM попадает в эту категорию. К сожалению, я совершенно не согласен с этой интерпретацией.
Я определяю интеллект как способность расширять границы знания.
На момент написания этой статьи машины, обученные предсказывать следующую лексему/слово, все еще не в состоянии масштабировать границы знаний.
Однако он может интерполировать данные, на которых он был обучен. Нет явного понимания логики, лежащей в основе слов, и не существует дерева знаний. Поэтому он никогда не сможет генерировать необычные мысли и делать скачки в понимании. Он всегда даст связный ответ, что-то среднее.

Мы должны думать о LLM больше как о словесном калькуляторе. Никогда полностью не доверяйте свое мышление языковым моделям.
В то же время мы можем чувствовать себя все более подавленными и незначительными, поскольку эти модели растут в геометрической прогрессии. Решение этой проблемы состоит в том, чтобы всегда проявлять любопытство к, казалось бы, несвязанным идеям. Идеи, которые на первый взгляд кажутся бессвязными, но обретают смысл благодаря нашему взаимодействию с окружающей средой. Цель — жить на острие знаний, создавая и соединяя новые точки.
Если вы работаете на этом уровне, технология во всех ее формах, будь то калькулятор или большая языковая модель, становится инструментом, который вы можете использовать, а не экзистенциальной угрозой, о которой вам нужно беспокоиться.