Após pequena para que todos possam trazer um rastreador web Python e extração de informações (exemplos para explicar). Xiao Bian sinto muito bem, agora para que todos possam compartilhar, mas também para ser uma referência. Venha e veja, juntamente seguir Xiaobian
arquitetura curso:
1, os pedidos frame: páginas de rastreamento automático e HTML pedido apresentado à rede automaticamente
2, robots.txt: web critérios de exclusão rastreador
3, quadro BeautifulSoup: análise de página HTML
4, quadro Re: quadro regular, página de informação chave extrato
5, quadro Scrapy: princípio rastreador web introduzido quadro réptil profissional introduzido
理念: O site é o API ...
linguagem Python comumente usado ferramentas de IDE
Ferramentas de texto IDE:
IDLE, Notepad ++, Texto Sublime, Vim e Emacs, Atom, Komodo Edit
Ferramentas de integração IDE:
PyCharm, Asa, PyDev & Eclipse, Visual Studio, Anaconda & Spyder, Canopy
· IDLE é um nível de entrada comum autoria ferramentas que vem com o padrão Python, que inclui um arquivo interativo de duas maneiras. Adequado para programas mais curtos.
· Sublime O texto é projetado para programadores de terceiros para desenvolver ferramentas de programação específicas que podem melhorar a experiência de programação com uma variedade de estilos de programação.
· Wing é Wingware fornecido pelo IDE empresa cobra, rica em recursos de depuração, com controle de versão, versão de sincronização, adequado para pessoas a se desenvolver. Adequado para escrever grandes programas.
· Visual Studio é a manutenção da Microsoft, você pode escrever Python configure PTVs, meio ambiente, principalmente baseado no Windows, ricos recursos de depuração.
· Eclipse é uma fonte aberta ferramentas de desenvolvimento IDE, pode ser escrito em Python, configurando PyDev, mas o processo de configuração é complexo e exige um certo grau de experiência em desenvolvimento.
· PyCharm em Community Edition e Professional Edition, Community Edition gratuito, simples e altamente integrado, adequado para a preparação de projetos mais complexos.
Adequado para computação científica, análise de dados IDE:
· Canopy é mantido pela empresa cobra ferramenta Enthought que suporta cerca de 500 bibliotecas de terceiros, desenvolvimento de aplicativos para computação científica.
· Anaconda é uma fonte aberta livre, suporta quase 800 bibliotecas de terceiros.
Os pedidos Obtendo biblioteca
Os pedidos de instalação:
biblioteca de pedidos é agora reconhecido como o melhor web crawling Python bibliotecas de terceiros, recursos simples simples.
Site Oficial: http: //www.python-requests.org
Encontrar "cmd.exe", executar como administrador, digite na linha de comando: "\ Windows \ System32 C" : "pip instalar pedidos" para ser executado. 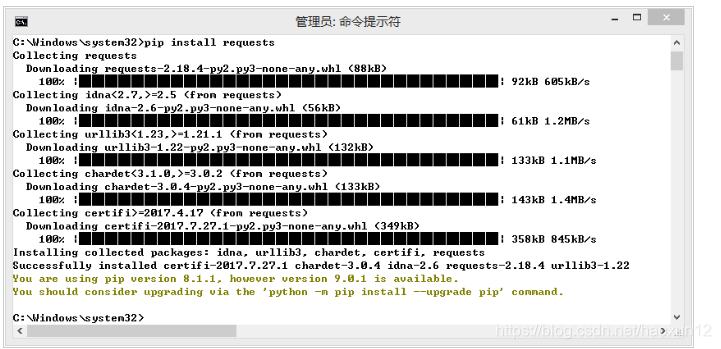
Use IDLE Teste solicitações de biblioteca:
>>> import requests
>>> r = requests.get("http://www.baidu.com")#抓取百度页面
>>> r.status_code
>>> r.encoding = 'utf-8'
>>> r.text
Os pedidos Biblioteca 7 principal método 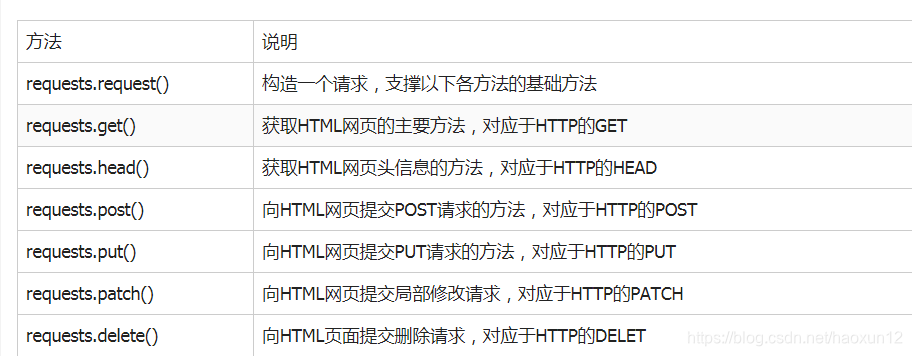
método get ()
r = requests.get (URL)
método get () para construir uma solicitação de objeto de solicitação de recursos para o servidor, o servidor retorna um objeto Response compreende o recurso.
requests.get (url, params = None, ** kwargs)
url: url tem a intenção de obter links para páginas
params: parâmetros extras no formato url, dicionário ou fluxo de bytes, opcionais
** kwargs: parâmetros de controle 12 acesso
Dois objetos importantes solicitações de biblioteca
· Solicitação
· Resposta: objeto de resposta contendo o conteúdo de répteis retorno
atributos do objeto Response
r.status_code: HTTP solicitação retorna um status 200 indica conexão bem-sucedida, 404 representa um fracasso
r.text: HTTP conteúdo cadeia de resposta, ou seja, o conteúdo da página url correspondente
r.encoding: que codifica o conteúdo correspondente do cabeçalho HTTP de adivinhar
r.apparent_encoding: que codifica o conteúdo correspondente a partir da análise de conteúdo (codificação alternativa)
r.content: forma binária de um conteúdo da resposta HTTP
r.encoding: Se cabeçalho conjunto de caracteres não existe, a codificação é considerado como ISO-8859-1.
r.apparent_encoding: analisar o conteúdo da página pode ser visto como codificação alternativa r.encoding.
código de resposta:
r.encoding: suposição do cabeçalho HTTP na codificação de conteúdo de resposta; se cabeçalho conjunto de caracteres não existe, a codificação é considerado como ISO-8859-1, r.text para o conteúdo da web de exposição de acordo r.encoding
r.apparent_encoding: analisados com base na codificação do conteúdo da página pode ser visto como uma alternativa r.encoding
páginas rastreadas quadro código genérico
Os pedidos anormais biblioteca 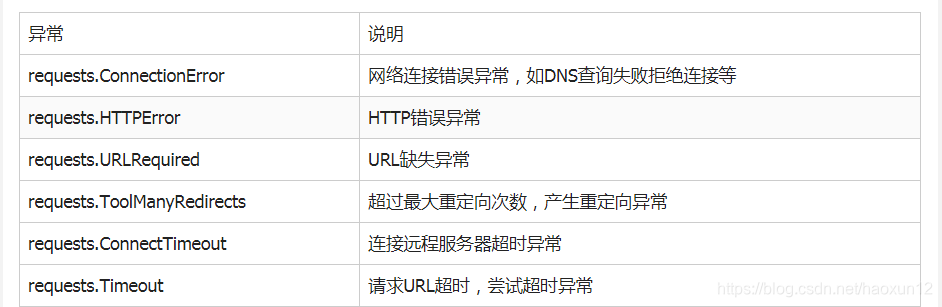
exceção Response
r.raise_for_status (): Se não 200, uma anormalidade requests.HTTPError;
No método para determinar o r.status_code interior é igual a 200, se nenhuma instrução adicional que facilita o uso de manipulação de exceção try-excepto
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
quadro de código comum, permite que o usuário rastreamentos web se torna mais eficiente, estável e confiável.
protocolo HTTP
HTTP, Hypertext Transfer Protocol, Hypertext Transfer Protocol.
HTTP baseia-se num modo de "pedido e resposta", sem estado protocolo da camada de aplicação.
protocolo HTTP usa a URL como identificação localizar recursos de rede.
formato de URL: http: // host [: port] [caminho]
· Anfitrião: Internet nome de domínio anfitrião legal ou endereço IP
· Porta: número da porta, o número da porta padrão é 80
· caminho: o caminho do recurso solicitado
HTTP URL de compreender:
URL é de acesso Internet recursos de caminho através do protocolo HTTP, uma URL correspondente a um recurso de dados.
a operação do protocolo HTTP sobre os recursos de 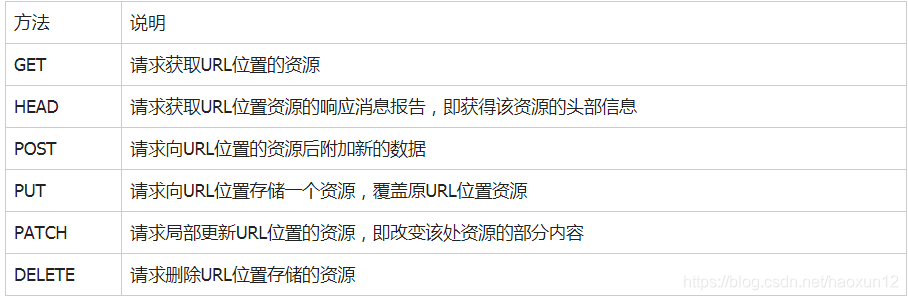
compreensão da diferença entre PATCH e PUT
Suponha que um conjunto de dados de localização URL UserInfo, incluindo UserID, UserName, 20 campos.
Demanda: o usuário para modificar o username, o outro inalterado.
* O uso de remendo, submetido UserName única solicitação de atualização parcial ao URL.
* Use PUT, todos os 20 campos devem ser submetidos ao URL, campo descompromissado é removido.
A principal vantagem do PATCH: poupar largura de banda de rede
Solicita método analítico principal Biblioteca
requests.request (método, url, ** kwargs)
· Método: pedido modo, o correspondente get / put / postar 7 tipos
例: r = requests.request ( 'Opções', url, ** kwargs)
· Url: url tem a intenção de obter links para páginas
· ** kwargs: parâmetros de controle de acesso, um total de 13, são opcionais
params: dicionário ou sequência de bytes adicionado à URL como parâmetros;
kv = {'key1':'value1', 'key2':'value2'}
r = requests.request('GET', 'http://python123.io/ws',params=kv)
print(r.url)
'''
http://python123.io/ws?key1=value1&key2=value2
'''
Dados: dicionário, uma sequência de bytes ou um objecto de ficheiro, como o conteúdo do Pedido;
JSON: os dados JSON-formatado, como o conteúdo do pedido;
cabeçalhos: dicionário, HTTP cabeçalho personalizado;
hd = {'user-agent':'Chrome/10'}
r = requests.request('POST','http://www.yanlei.shop',headers=hd)
cookies: um dicionário ou Cookiejar, Request do cookie;
auth: tuplas, autenticação HTTP apoio;
arquivos: uma transferência dicionário, arquivo;
fs = {'file':open('data.xls', 'rb')}
r = requests.request('POST','http://python123.io/ws',files=fs)
timeout: definir o tempo limite, em segundos;
proxies: um dicionário, defina o servidor de proxy de acesso, você pode aumentar a autenticação de login
allow_redirects:, o padrão é True, o interruptor de redirecionamento Verdadeiro / Falso;
transmitir: Verdadeiro / Falso, o padrão é True, acesso imediato a downloads de conteúdo mudar;
verificar: o padrão é True, interruptor verdadeiro / falso, certificado SSL autenticação;
cert: caminho do certificado SSL local
#方法及参数
requests.get(url, params=None, **kwargs)
requests.head(url, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.delete(url, **kwargs)

rastreador Web causou problemas
assédio desempenho:
Limitado ao nível eo propósito da escrita, o rastreador web será um grande servidor web sobrecarga de recursos
risco legal:
Dados no servidor tem propriedade, após a obtenção de dados para crawlers lucro vai trazer risco legal.
Perda de privacidade:
crawlers pode ter a capacidade de quebrar através de um controle de acesso simples, o acesso aos dados protegidos de modo que a divulgação da privacidade pessoal.
limite de Web Crawler
· Revisão Fonte: User-Agent para determinar restrições
visita de inspecção cabeçalho do protocolo HTTP campo User-Agent, o valor em resposta ao acessar um navegador ou amigável-rastreador.
· Anúncio: acordo Raízes
Todos website disse rastejar répteis táticas, répteis cumprir os requisitos.
acordo robots
Protocolo de exclusão de robôs critérios de exclusão crawlers
Papel: website informando web crawler que páginas podem ser rastreados e quais não.
Forma: arquivo robots.txt no diretório raiz do site.
Caso: acordo Jingdong Robots
http://www.jd.com/robots.txt
# 注释:*代表所有,/代表根目录
User-agent: *
Disallow: /?*
Disallow: /pop/*.html
Disallow: /pinpai/*.html?*
User-agent: EtaoSpider
Disallow: /
User-agent: HuihuiSpider
Disallow: /
User-agent: GwdangSpider
Disallow: /
User-agent: WochachaSpider
Disallow: /
contrato de uso de robôs
Rastreador: robots.txt identificação automática ou manual, em seguida, o conteúdo de rastreamento. 
Encadernação: protocolo Robots é recomendada, mas não obrigatória, o rastreador web pode não seguir, mas há riscos legais.
Solicita combate rastreador Biblioteca Web
1, commodities Jingdong
import requests
url = "https://item.jd.com/5145492.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
2, a mercadoria Amazon
# 直接爬取亚马逊商品是会被拒绝访问,所以需要添加'user-agent'字段
import requests
url = "https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv = {'user-agent':'Mozilla/5.0'} # 使用代理访问
r = requests.get(url, headers = kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(t.text[1000:2000])
except:
print("爬取失败"
3, palavras-chave Baidu / busca 360 submetidas
Motor de busca de palavras-chave submeter interface
· Baidu palavras-chave interfaces:
http://www.baidu.com/s?wd=keyword
· 360 Interfaces Palavras-chave:
http://www.so.com/s?q=keyword
# 百度
import requests
keyword = "Python"
try:
kv = {'wd':keyword}
r = requests.get("http://www.baidu.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
# 360
import requests
keyword = "Python"
try:
kv = {'q':keyword}
r = requests.get("http://www.so.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
4, o quadro rede de rastreamento e armazenamento
Rede formato de link da imagem:
http://www.example.com/picture.jpg
National Geographic:
http://www.nationalgeographic.com.cn/
Selecione um link de imagem:
http://image.nationalgeographic.com.cn/2017/0704/20170704030835566.jpg
图片爬取全代码
import requests
import os
url = "http://image.nationalgeographic.com.cn/2017/0704/20170704030835566.jpg"
root = "D://pics//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
5, a atribuição de endereços IP de consulta automática
www.ip138.com IP inquérito
http://ip138.com/ips138.asp?ip=ipaddress
http://m.ip138.com/ip.asp?ip=ipaddress
import requests
url = "http://m.ip138.com/ip.asp?ip="
ip = "220.204.80.112"
try:
r = requests.get(url + ip)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1900:])
except:
print("爬取失败")
# 使用IDLE
>>> import requests
>>> url ="http://m.ip138.com/ip.asp?ip="
>>> ip = "220.204.80.112"
>>> r = requests.get(url + ip)
>>> r.status_code
>>> r.text
Finalmente, eu recomendo uma reunião boa reputação python [ clique para entrar ], há um monte de veteranos habilidades de aprendizagem, experiência, habilidades de entrevista, experiência de trabalho e outros share de aprendizagem, quanto mais cuidadosamente preparado a informação introdutória base zero em dados reais do projeto todos os dias programadores Python explicar o timing da tecnologia, a partilha de alguns métodos de aprendizagem ea necessidade de prestar atenção aos pequenos detalhes
que essa extração rastreador web e informações Python (exemplos para explicar) é pequena série de compartilhar todo o conteúdo de toda a
