Diretório do artigo
extração de evento
O evento é promover o estado de coisas e condições de mudança relacionamentos. A maioria dos atuais recursos de conhecimento existentes (como a Wikipedia, etc.) a relação entre a entidade e a descrição entidade é estático, eo evento pode ser descrito em maior granularidade, dinâmico, o conhecimento estruturado é um complemento importante recursos de conhecimento existente .
Comparado com a extração relação, extraindo a mesma necessidade evento para extrair o predicado (o predicateA) e correspondente argumentos (elementos de eventos) do texto, mas a diferença é, binário problema extração relação (binário), e geralmente dois argumentos aparecem na mesma frase, ea dificuldade de extração evento é que existem vários argumentos e modificadores (modificadores), pode ser repartido em várias frases, e alguns argumentos não são necessárias (em qualquer evento instância alguns destes serão omitidos), o que torna o bootstrapping / aprendizagem à distância / correferência torna-se muito difícil.
tarefas de extração de evento pode ser dividido em duas categorias :
identificação e evento extracção
Identificar e extrair informações de eventos e apresentadas de forma estruturada, incluindo o tempo, local de ocorrência, e os papéis envolvidos na mudança estado da ação ou evento informações associadas do texto de descrição.
detecção de eventos e de rastreamento
detecção de eventos e de rastreamento é projetado para fluir eventos de notícias de texto são organizados de acordo com os seus relatórios, de várias fontes para os meios de comunicação tradicionais de monitoramento fornece a tecnologia de núcleo para permitir que os usuários entendam a notícia e seu desenvolvimento. Especificamente, a descoberta evento e rastreamento consiste em três tarefas principais: segmentação, detecção e rastreamento, será dividido em eventos de notícias de texto, a descoberta de novos (imprevisível) evento e acompanhar o desenvolvimento dos acontecimentos relatados anteriormente.
tarefas de descoberta evento pode ser dividido em acontecimentos históricos e eventos online achado encontrados em duas formas, o ex objetivo é encontrar um evento não previamente identificados a partir de documentos de notícias classificadas segundo tempo, o último é a descoberta fluxo de notícias em tempo real em tempo real de novo evento.
Este artigo centra-se no reconhecimento do evento e extração. Primeiro, olhe para os principais conceitos relacionados:
-
Descrição do evento (Menção Event):
descrição do grupo frase evento / frase / sentença, contém um gatilho (trigger) e qualquer número de argumentos -
Gatilho evento (Gatilho Event):
descrição de evento vocabulário que melhor representa o incidente, decidiu uma característica importante da categoria de evento, geralmente um verbo ou substantivo -
elemento evento (argumento de evento)
informações importantes sobre o evento, ou seja uma entidade descrita em (menção entidade), composta principalmente de entidades, atributos, valores, etc. expressar a semântica completa de unidade de granulação-fino -
O papel dos elementos (Argumento Papel)
elementos de eventos desempenhar um papel no incidente, relações semânticas elementos e evento eventos pode ser entendida como ranhura -
O tipo de evento (tipo de evento)
reconhecimento evento e extração de entendimento
Intuitivamente, o evento pode ser entendida como a tarefa de extração de encontrar uma categoria de evento específico a partir do texto, e, em seguida, o processo de preenchimento de formulários.
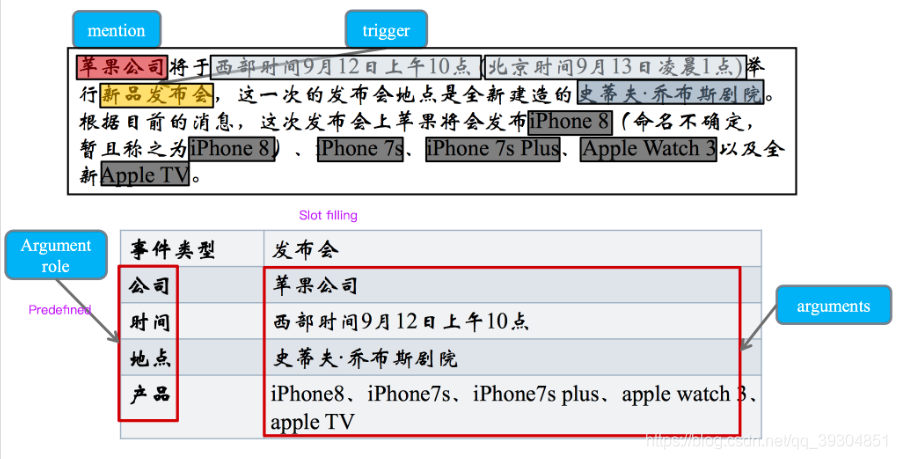
definidos pelo sistema de extracção de evento
Dado um documento de texto, um sistema de extracção evento deve prever gatilhos de eventos com sub-tipos específicos e seus argumentos para cada frase.
Dado um documento de texto, um sistema de extracção evento deve produzir a palavra evento de disparo previsto para cada frase, cada palavra contém um gatilho evento específico sub-tipo do evento e seus elementos específicos.
Em outras palavras, a tarefa mais básica de extrair seção de eventos inclui:
- Palavra disparadores de eventos de reconhecimento e tipo de evento
- Evento elemento de extração (argumento do evento), ao mesmo tempo determinar o seu papel (Role argumento)
- frase extração ou frase que descreve o evento
Claro, existem outros sub-tarefas incluem atributos de eventos de rotulagem, resolução de evento correferência e assim por diante.
Evento extraído principalmente levada a cabo em fases, geralmente a partir do classificador de disparo (disparador classificador), se não houver disparo, o disparador e o contexto em que se classifica como um recurso para determinar o tipo de evento, então o próximo passo do classificador argumento (elementos de eventos Ferre sua ), a pena para cada menção entidade (entidades envolvidas) para classificar, determinar se o argumento (elemento evento), e em caso afirmativo, determinar seu slot papel.
O método baseado na correspondência de padrões
MUCs o início, o evento governa sistemas de extração artificiais são escritos com base na árvore de sintaxe ou uma expressão regular, como CIRCO (Lehnert 1991), RAPIER (Califf & Mooney 1997), SRV (Freitag 1998), AutoSlog (Riloff 1993) , LIEP (Huffman 1995), Palka (Kim & Moldovan 1995), dE CRISTAL (Soderland et al., 1995), hasten (Krupka 1995) e assim por diante, em seguida, o modelo tem lentamente supervisionado de aprendizagem, a fase de ACE, grande a maioria dos sistemas são baseados em aprendizagem supervisionada, mas por causa da consistência da questão da rotulagem, geralmente pobre desempenho do sistema, evento ACE extracção realizada apenas uma vez, em 2005.
Primeiro, olhe para a abordagem baseada em modelo após a extração, deve ser identificado pela sintaxe básica (sintática) e restrições semânticas (restrições semânticas).
Com base no corpus anotação manual de
No início do início, o processo de criação do modelo é geralmente a partir de um grande conjunto de etiquetas, gerar modelos baseados inteiramente no corpus anotação manual, o efeito de aprendizagem é altamente dependente da anotação manual da qualidade.
AutoSlog (Riloff)
pressupostos básicos:
. A na primeira menção dos elementos de eventos para determinar a relação entre os elementos e o evento
b em torno do elemento declaração evento contém uma descrição do papel de elemento de eventos no caso de.
Para criar regras de extração de aprendizagem supervisionada e revisão manual. Por dados de treinamento foi preenchida em um bom sulco (slot cheio), a estrutura de análise sintática AutoSlog perto da fenda, a regra de extração é formada automaticamente, uma vez que o modelo gerado por este processo muito-geral, é necessário rever artificial. Formou-se essencialmente de um dicionário.
por exemplo
Ricardo Castellar, o prefeito, foi sequestrado ontem pelo FMLN.
Mayor Ricardo Castelar (Ricardo Castellar) ontem sequestrado FMLN.
Ricardo Castellar hipótese é marcado tornou-se a vítima (vítimas tinham sido rotulado), AutoSlog com base na análise de juiz Ricardo Castellar é o sujeito, e em seguida, acionar as regras relevantes do assunto (Assunto) passivo-verbo, a palavra em uma frase relacionada com enchimento para dar uma regra (vítima) foi sequestrado, então depois o texto, desde que presente sequestrada em uma configuração passiva, o que corresponde ao assunto será marcado vítima.
Contratar
pressupostos básicos: expressão da linguagem em áreas específicas de altas freqüências é contável
modo de trama e estruturas semânticas para representar uma frase num modo de extracção campo específico, através da integração de informação semântica WordNet, pode ser obtido artificial Palka efeito extracção quase puro em áreas específicas.
Com base na supervisão fraca
Demorado anotação manual, e não há consistência, e método de supervisão fraco não requerem corpus totalmente dimensionado, única corpus artificial de certos modelos de pré-selecção ou sementes desenvolvidas automaticamente pela máquina de acordo com o corpo pré-classificação ou molde semente o modo de aprendizagem.
-
TS-AutoSlog
Riloff e Shoen de 1995
AutoSlog-TS identificação não obrigatória texto, só precisa de um corpus de treinamento bom pré-classificada, a categoria está relacionada com o campo ou não relevante. Processo é para passar por cima do corpus, para cada frase nominal (com base na análise sintática para identificar) são gerados regras de extração correspondente e, em seguida, passar por cima de todo o corpo, alguns dados estatísticos relevantes gerados para cada regra, a idéia básica não está relacionado ao texto regras de extração comparados no texto relevante mais frequentemente são mais propensos a ser boas regras de extração. Suponha que os dados de treinamento associados com uma relação texto relacionado é de 1: 1, a proporção da taxa de relevância calcular uma correlação de cada um a extração regras geradas, governar o número de instâncias do número de casos em que as regras aparecem documentos relacionados / ocorre em todo o corpus, a taxa de relevância <50% das regras de extracção são descartados, as regras restantes na forma de registo classificados descendente * relevance_rate (frequência), e depois analisados manualmente. -
Os tempos de
Chai e Biermann de 1998
introduziu o conceito de arte WordNet conhecimento independente, a capacidade de generalização para melhorar o modo de aprendizagem, e manualmente ou palavra sentido regras de desambiguação, de modo que o padrão final é mais preciso -
Nexus
Piskorski et al, 2001;.... Tanev et al, 2008
corpus pré-tratados com o agrupamento -
GenPAM
Jiang de 2005
no processo de aprendizagem, o caso especial de padrão generalizado gerado, a semelhança entre o WSD conseguir modo de utilização eficaz, minimizar a intervenção manual e carga do sistema
resumo
método padrão de correspondência baseado em um melhor desempenho em áreas específicas, a representação simples conhecimento, fácil de entender e os pedidos consecutivos, mas tem um grau diferente de dependência, a cobertura pobre e portabilidade para a linguagem, as formas de arte e documentos.
O método de correspondência de padrão, a precisão do modelo é um fator importante que afeta o desempenho de todo o processo. Na prática, o método padrão de correspondência é amplamente usado, caracterizado principalmente por uma elevada precisão baixa taxa de recuperação, para melhorar a taxa de recuperação, é necessário estabelecer uma biblioteca modelo de mais completa, e em segundo lugar, método semi-supervisionado pode ser usado com o dicionário de construção do gatilho.
Com base em estatísticas - de aprendizado de máquina tradicional
Construiu um modelo estatístico baseado em método de extração de eventos podem ser divididos em duas grandes categorias de gasoduto e modelo articulação.
oleoduto
A tarefa de extração evento em um problema de classificação multi-estágio (extração gasoduto), você precisa executar a seguinte ordem de classificação:
- Evento palavra gatilho classificador (Gatilho Classificador)
para determinar se uma palavra do vocabulário evento de disparo, e categoria de evento - Elemento classificador (Argumento Classificador)
frases é se o elemento evento - O papel dos elementos classificador (Papel Classificador)
determinar os elementos categoria papel - classificação propriedade (atributo Classificador)
propriedades de evento determinação - classificador reportável (Classificador reportável-Event)
determinar instância de evento reportável existe
