anuário
================================================== =====================
Ele Zhang, anos de experiência na indústria de Internet, trabalhou como engenheiro de rede, engenheiro de integração de sistemas, operação do sistema LINUX e manutenção engenheiros
autor micro carta: zhanghe15069028807, agora habitat Jinan Lixia District
============================================= ==========================
Character Set tópico
preliminares
1, um personagem
nos Estados Unidos, 26 letras, cada letra é um personagem.
Na China, a cada caractere chinês é um personagem
2, conjunto de caracteres
coleção mais caracteres é chamado conjunto de caracteres
3, conjunto de caracteres
para a codificação de caracteres é uma coleção de conjuntos de caracteres add.
Um grupo de caracteres mais de codificação, tais como o conjunto de caracteres ASCII é o conjunto de caracteres de 26 letras. Normalmente, um conjunto de caracteres que representa um país ou uma nação. Nós também temos conjunto de caracteres chineses: GB2312 (chinês simplificado), Big5 (chinês tradicional).
Vale ressaltar que o maior conjunto de caracteres Unicode, incluindo todos os caracteres existentes.
4, o código de caracteres
para o número de conjunto de caracteres a qual cada carácter é editado codificação de caracteres.
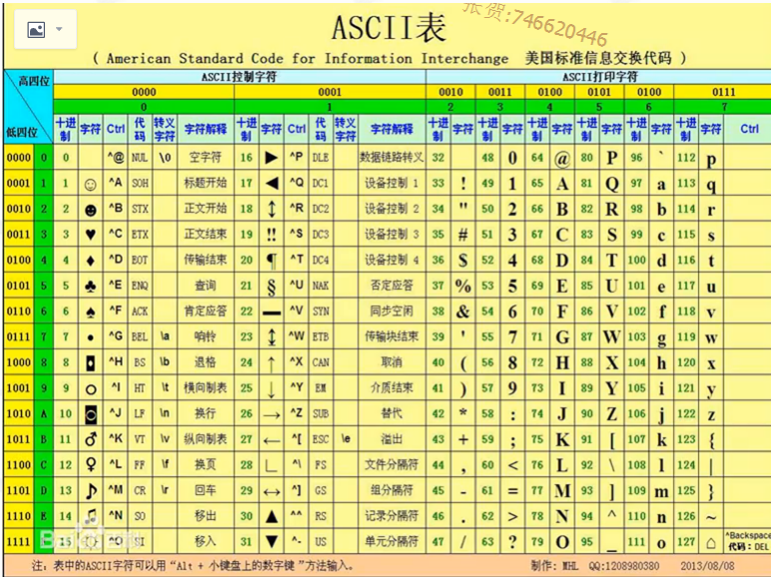
5, como armazenar caráter computador?
Quando escrevemos a Apple ---- salvar no bloco de notas dentro do computador como salvá-lo? O computador só irá salvar binário, portanto, deve ser convertida para uma maçã binário pode ser salvo, será salvo de acordo com os procedimentos estabelecidos conjunto de caracteres bloco de notas, se que é salvo de acordo com o conjunto de caracteres ASCII, fato em seguida, guardado:
01000001-- --------> a
0111 0000 -----------> o p
............
6, computador e como mostrar personagem? Por que, quando o show vai ser ilegível?
Acima de nós falamos sobre como armazenar esses personagens, há uma conversa sobre como podemos mostrar o personagem?
Salvar o bloco de notas, quando a Apple irá converter o conjunto de caracteres para binário, ele também deve mostrar conjunto de caracteres, esse conjunto de caracteres deve ser o mesmo, caso contrário, eles vão ser ilegível, o que é bem compreendida.
7, o suplemento de caracteres sequência de agrupamento ----
Para adicionar um conceito, um conjunto de caracteres pode ter várias sequências de caracteres, os chamados sequência de caracteres refere-se a um conjunto diferente de caracteres que codificam, por isso, o mesmo conjunto de caracteres, se a seqüência de caracteres não é a mesma coisa, mas também representa um conjunto de caracteres diferente.
8. Banco de dados - conjunto de caracteres e seqüência tabelas entre
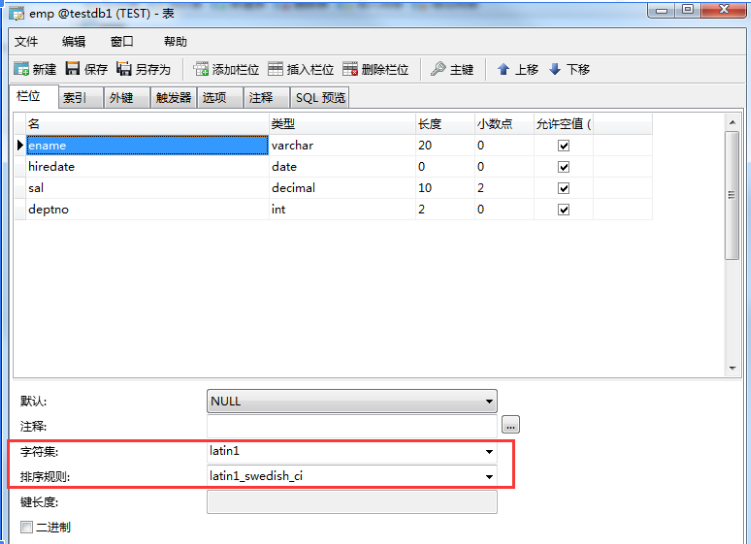
caractere final sequência ci caso insensível
ao fim da sequência de caracteres é sensível cs
Conjunto de caracteres comuns
Inglês conjunto nacional de caracteres (8 bits, o real 7)
- ASCII
Inglês conjunto de caracteres nacional definido 128 caracteres, ou seja, 7 potência de 2, mas a menor unidade de memória do computador é bytes, não bits, tanto de um.
- ASCII estendido
conjunto de caracteres ASCII estendido é uma categoria, existem latin1, ladin2, ladin5, ladin7, com base no conjunto de caracteres ASCII e estendido em um número de conjunto de caracteres latinos, o conjunto de caracteres ASCII estendido inclui o conjunto de caracteres ASCII.
Segundo, a China (16 binário)
- GBK2312
conjunto chinês caráter chinês simplificado
- BIG5
conjunto do caráter chinês Tradicional Chinesa
- GBK
Nota: chinês conjunto de caracteres classe é baseada no conjunto de caracteres nacional Inglês, o que significa que a China três caracteres grandes: GBK, BGK2312, BIG5 todo o urso com conjunto de caracteres ASCII estendido.
Em terceiro lugar, em todo o mundo
Global de Linguagem conjunto de caracteres Unicode (16)
Mas também pela evolução da UTF8 unicode
relação de inclusão
Identificador do conjunto de caracteres ASCII normal de 128 caracteres
Identificador do conjunto de caracteres ASCII estendido 256 caracteres
GBK, BGK2312, BIG5 todo o urso com conjunto de caracteres ASCII estendido.
Esse urso com os países de língua Inglês unicode conjunto de caracteres, também suportar com conjunto de caracteres chineses, é o maior conjunto de caracteres.
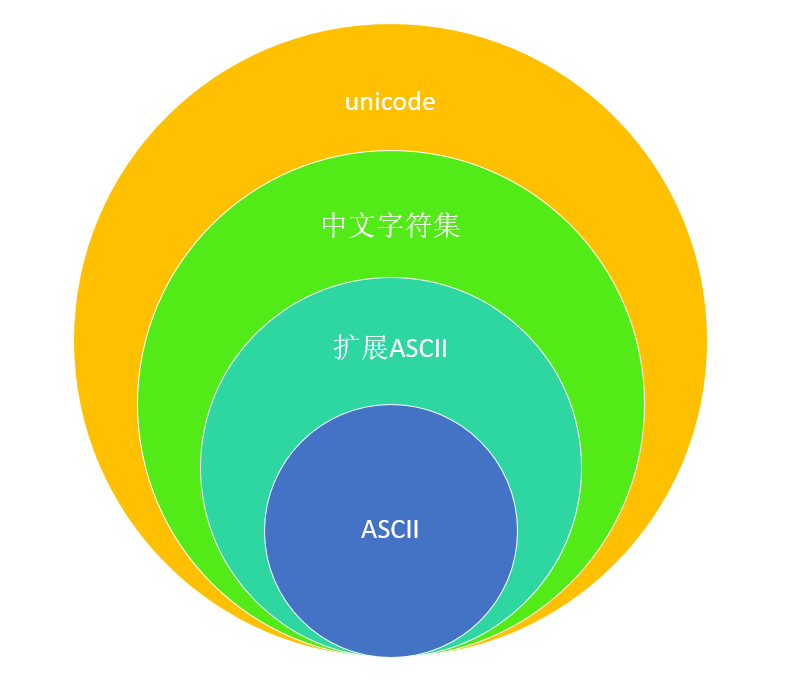
relações de conversão
relações de conversão são bastante simples, e uma ampla gama de possível transição para um pequeno intervalo, enquanto a incapacidade de pequena escala para converter uma grande variedade.
Um cliente usa o conjunto de caracteres
O servidor usa o conjunto de caracteres B
假设客户端给服务器发送消息的时候使用字符集A进行编码,当服务器收到之后能用B解码吗?可以,但是解出来是乱码!!所以就要求服务器在解码时也要使用字符集A,这样解析出来才不会有乱码。现在多数软件都是使用UTF8来进行编码,UTF8是全球范围的,也说是说解码的时候必须使用相同的字符集或者比发送者范围大的字符集。O remetente será enviado de acordo com o conjunto de caracteres do destinatário, do remetente e do receptor irá tentar usar o mesmo conjunto de caracteres ou o intervalo que o seu grande conjunto de caracteres, em seguida, o remetente sabe o destinatário como apoiar o conjunto de caracteres é? Os três disseram aperto de mão.
Mas quando a loja não é necessariamente o mesmo que usar o conjunto de caracteres do remetente é armazenado, não podem ser armazenados de acordo com outros conjuntos de caracteres, mas somente se, o destinatário deve usar o mesmo ou maior alcance do que o seu conjunto de caracteres o remetente me enviou o conteúdo é decodificado, convertido para o conjunto de caracteres seu próprio armazenamento utilizado após a decodificação, mas raramente o fazem, porque isso é muito baixa eficiência, mas uma vez que o personagem de armazenamento definido o conjunto de caracteres a ser menor do que o alcance de leitura, que embaraçosos, personagens de leitura, finalmente, ler, enquanto o conjunto de caracteres de armazenamento não podem ser armazenados, o computador aqui não é o quão inteligente, não pode ser forçado a mantê-lo armazenado, o resultado é armazenado no computador interno é ilegível.
unicode dada UTF8
unicode dois bytes, 16 bits, se o chinês ou Inglês deve representar, 16, representando 0 o suficiente, por isso é unificado formato, mas o espaço será desperdiçado em certa medida.
Se você usar unicode para escrever o programa, é impossível para compilar, e por quê? O compilador é o conjunto de caracteres ASCII, o compilador só pode compilar em Inglês, não compilação chinesa, o compilador só pode compilar conjunto de caracteres ASCII binário de 8 bits, e se dando-lhe 16 do conjunto de caracteres Unicode, não sei como ele é compilado ! Como resolver isso? Desta vez não houve UTF8, UTF8 unicode é mais flexível do que, e não como unicode como um personagem a fim de unificar tem que usar o armazenamento de 16 bits.
UTF8 para uso quando armazenar o personagem Inglês 8, memória chinês de 24 bits, é tão mágico! Na verdade, acho que também não tem a magia, apenas está em conformidade com o conjunto de caracteres ASCII UTF8 codificação única, então o compilador pode identificar o programa pelo utf8 escrito, é claro, é apenas a identificação do código escrito em Inglês, ainda não reconhece chinês .
Suponho que no bloco de notas dentro da loja Zhang, através do conjunto de caracteres ASCII é armazenada, vai ocupar 40 bits, ou seja, 5 B (bytes)
Suponhamos que o bloco de notas armazenadas dentro Zhang, pelo conjunto de caracteres Unicode é armazenado, ocupará 5 * 16 = 80, ou seja, 10 B (bytes)
Suponhamos que o bloco de notas armazenadas dentro Zhang, pelo conjunto de caracteres UTF-8 é armazenado, irá ocupar 40 'bits, isto é, 5 B (bytes)
NOTA: no final tem um espaço reservado o bloco de notas.
conjunto de caracteres mysql
#查看数据库支持的字符集
show character set; 
Também pode usar como padrão conjunto de caracteres do servidor, quando criamos o banco de dados, se você não especificar um conjunto de caracteres herdará conjunto de caracteres do servidor.
Quando criamos tabelas de dados, se você não especificar o conjunto de caracteres irá herdar o conjunto de caracteres do banco de dados.
Quando criamos uma coluna de dados, se você não especificar um conjunto de caracteres herdará tabela de conjunto de caracteres
relacionamento com o cliente e conjunto de caracteres de conexão
character_set_client se refere ao conjunto de caracteres do cliente, que é o personagem cliente defini-lo?
Depois de um tempo, nós tal via banco de dados CRT ou Xshell nós somos o cliente, pelo cliente para o servidor de comando MySQL envia codificação é latin1 através mostra a figura superiores a codificação, a codificação é conseguido através conjunto de caracteres do cliente, enviados para o servidor tempo também depende de qual personagem conjunto de caracteres conjunto character_set_connection, se os dois não são os mesmos, mas também para a conversão, mas geralmente é o mesmo, a eficiência de conversão até muito baixa.
servidor MySQL depois de ter recebido, a decodificação do conjunto de caracteres e as necessidades do cliente, também a mesma ou maior do que o intervalo, após a decodificação for concluído, a tabela de banco de dados para armazenar o tempo vai depender do conjunto de caracteres de armazenamento, se não for o mesmo, após a decodificação também recodificados.
O servidor irá acomodar conjunto de caracteres do cliente.
Visualização de conjuntos de caracteres de nível do servidor:
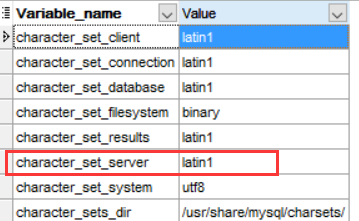
O TEST2 banco de dados recém-criado herdou latin1
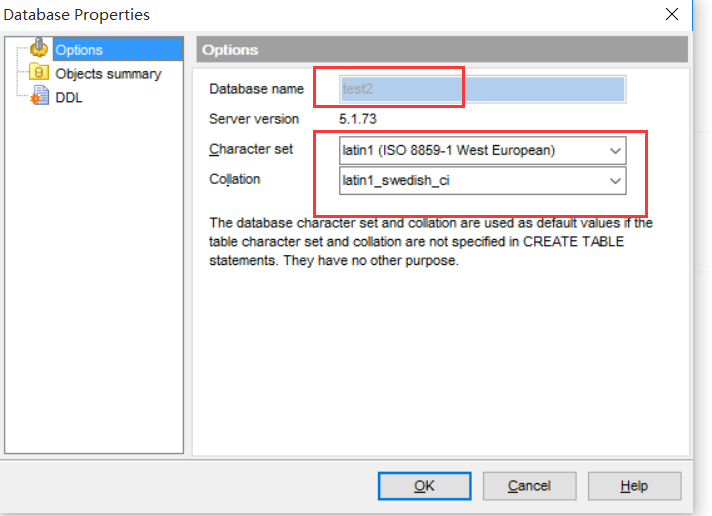
De nível de servidor conjunto de caracteres padrão é atualmente latin11, vamos alterá-lo para UTF8.
root@zhanghe ~]# vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
default-character-set=utf8 #加了这一行
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[root@zhanghe ~]# /etc/init.d/mysqld restart
mysql> show variables like 'character_set_%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | utf8 | #变了
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | utf8 | #变了
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+Novo banco de dados mostrado abaixo, torna-se um conjunto UTF8, personagem antes o banco de dados não foi alterado.
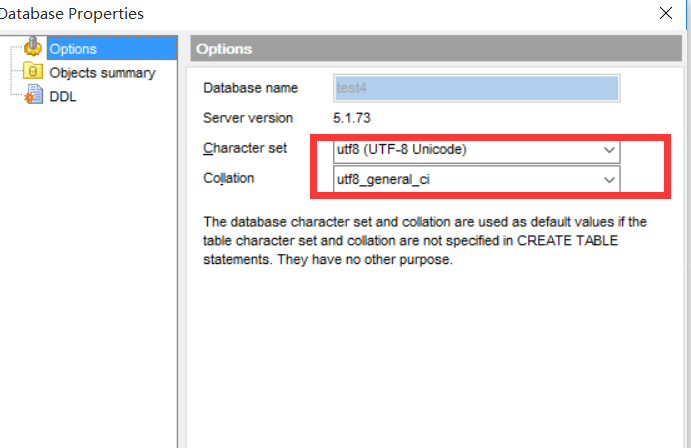
create database test5 default charset latin1; 创建数据库的时候指定字符集
create table student 创建表的时候指定字符集
(
sid INT,
sname char(10),
adress char(20) character set latin1 列也可以不继承表
)default charset utf8 指定表的字符集
alter detabase db character set 'latin1' 直接更改更改数据库的字符集是latin1
alter table student character set 'latin1' 直接更改表的字符集
alter table student change address address character char(20)) sets 'utf8' 直接更改列的字符集 Alterar o conjunto de caracteres de banco de dados padrão não tem efeito sobre o conjunto de caracteres de uma tabela existente, ele só irá afetar o conjunto de caracteres padrão da nova tabela.
resumo
Alterar conjunto de caracteres padrão da tabela, não tem efeito sobre o conjunto de caracteres agora está listado na tabela afetará somente o conjunto de caracteres padrão do add-linha.
Alterar o conjunto de caracteres de colunas, não altera os dados armazenados na coluna, agora ou nos dados armazenados anteriormente codificados conjunto de caracteres, mas você pode usar o novo conjunto de decodificação de caracteres de banco de dados, produzirá ilegível, após a inserção nas colunas de dados vai usar o novo conjunto de caracteres de memória de codificação, geralmente não facilmente mudar as colunas do conjunto de caracteres.