JVM
A figura a seguir mostra a estrutura do JDK (da Internet).
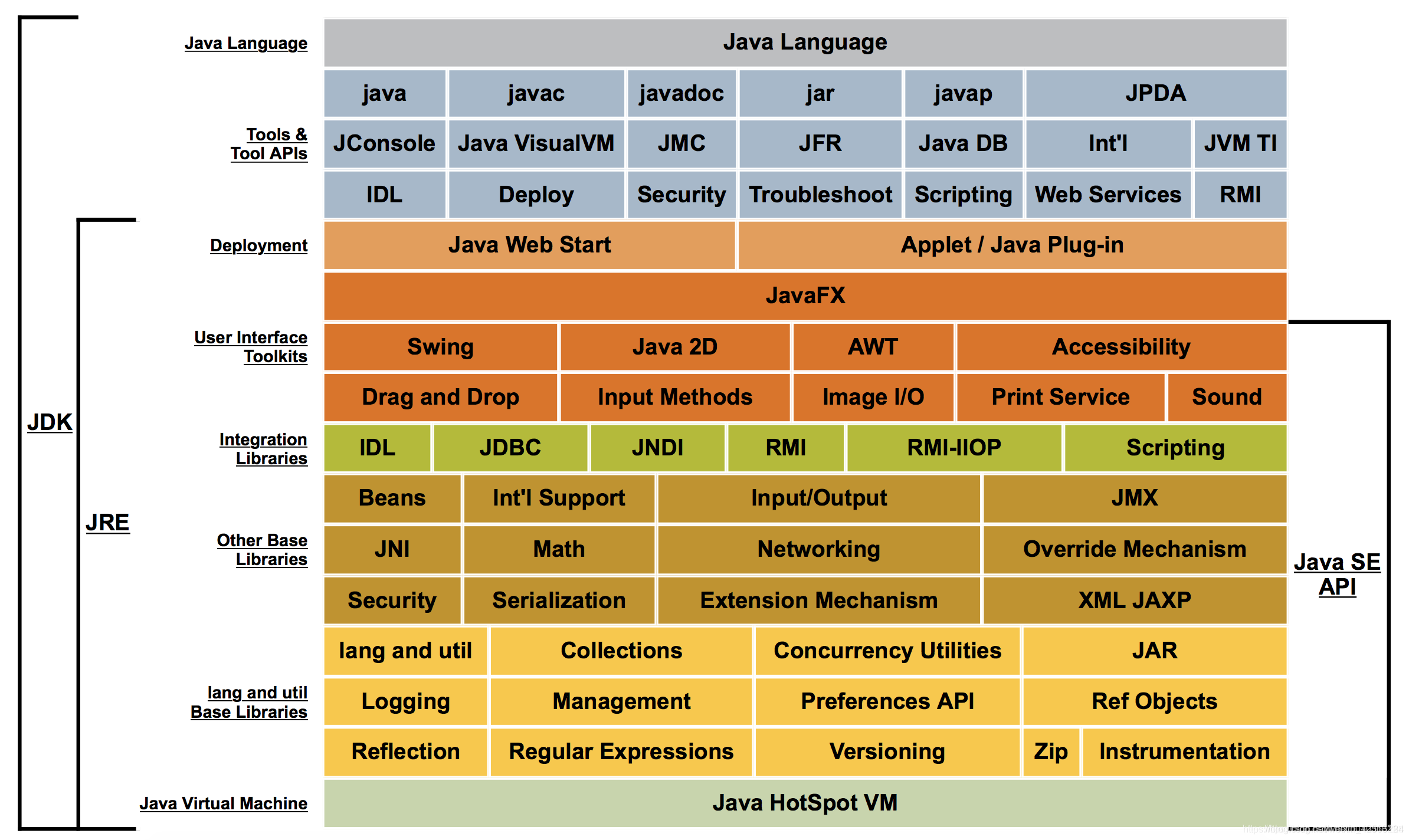
Versões diferentes do JDK têm JREs diferentes. O JVM analisará o mesmo arquivo de bytecode em uma
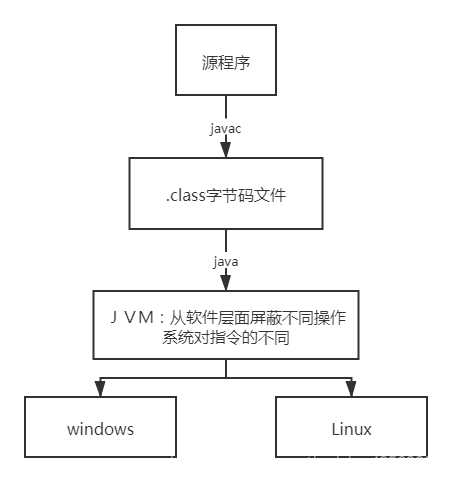
estrutura de JVM 01 binária reconhecida por sistemas diferentes :
Introduzido pelo seguinte código:
public class Demo {
public static final double PI = 3.14;
static Circle circle = new Circle();
public static void main(String[] args) {
Demo demo = new Demo();
int c = demo.calculate();
System.out.println(c);
}
public static int calculate() {
int a = 2;
int b = 3;
int c = (a + b) * 2;
return c;
}
}
class Circle{
private double radius;
public Circle() {
this(1.0);
}
public Circle(double radius){
this.radius=radius;
}
}
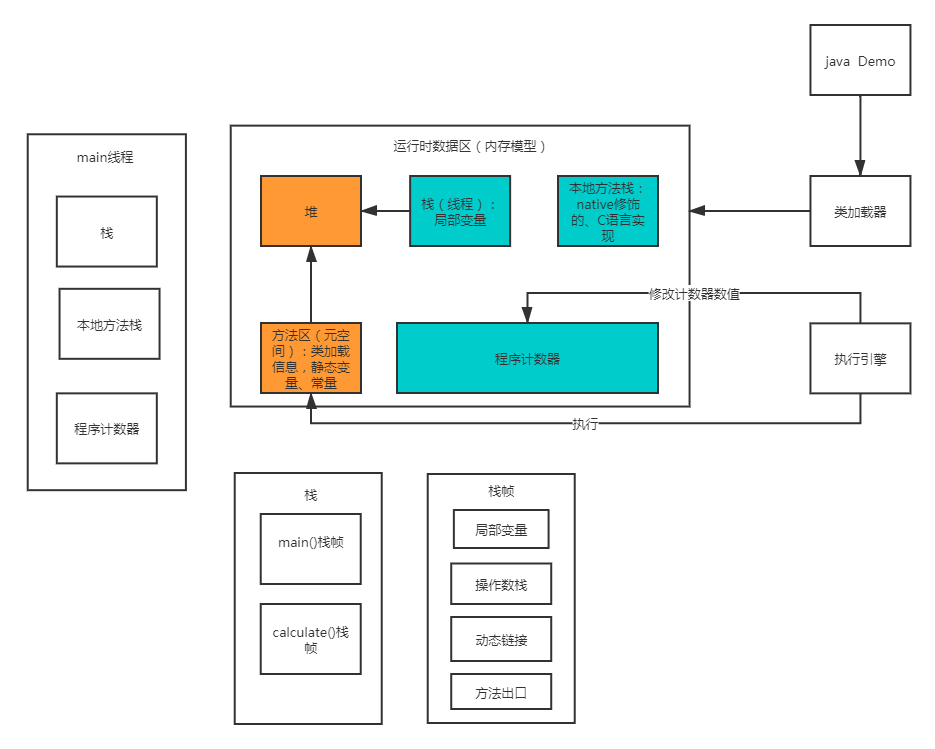
Para entender melhor o frame da pilha, podemos visualizar o arquivo bytecode do Demo por meio da linha de comando:
javap -c Demo.class > Demo.txt//-c 为反汇编,可将字节码文件编译成更加容易理解的文件,并写入到 Demo.txt文件中
Compiled from "Demo.java"
public class Demo {
public static final double PI;
static Circle circle;
public Demo();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: new #2 // class Demo
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: pop
10: invokestatic #4 // Method calculate:()I
13: istore_2
14: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
17: iload_2
18: invokevirtual #6 // Method java/io/PrintStream.println:(I)V
21: return
public static int calculate();
Code:
0: iconst_2
1: istore_0
2: iconst_3
3: istore_1
4: iload_0
5: iload_1
6: iadd
7: iconst_2
8: imul
9: istore_2
10: iload_2
11: ireturn
static {};
Code:
0: new #7 // class Circle
3: dup
4: invokespecial #8 // Method Circle."<init>":()V
7: putstatic #9 // Field circle:LCircle;
10: return
}
O manual de instruções da JVM pode bater papo em particular e vou enviá-lo para você (grátis)
Estrutura de heap:
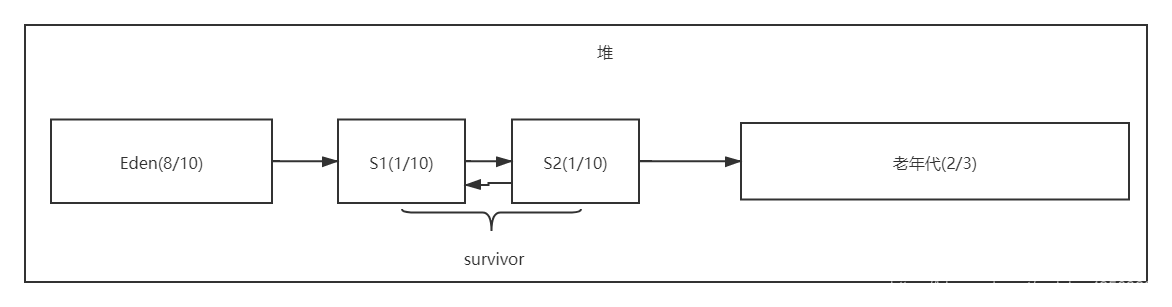
Descrição : O motivo da geração de gerações é melhorar a eficiência da alocação de objetos e coleta de lixo. Novos objetos serão colocados no Eden Park. Quando o Eden Park estiver cheio, o mecanismo de execução executará a coleta de lixo, ou seja, GC jovem ou menor GC, os objetos sobreviventes são colocados em S1. Quando o Eden Park estiver cheio novamente, GC menor será executado novamente. Desta vez, o lixo no Eden Park e S1 é coletado e os objetos sobreviventes em ambas as áreas são colocados em S2 novamente , E a idade geracional do objeto em S1 é +1. Quando o Eden Park está cheio novamente, os objetos sobreviventes no Eden Park e S2 são colocados em S1, e a idade geracional do objeto em S2 é +1; Quando a idade geracional de um objeto chegar aos 15, ele será colocado na velhice. Quando a velhice estiver cheia, o GC completo será executado. O consumo do sistema é muito alto. Você deve tentar evitar o GC cheio e fazer isso uma vez por dia, uma semana e um mês. Normalmente, existem muitas regras para fazer os objetos entrarem diretamente na velhice, como uma delas: quando o tamanho do objeto sobrevivente no Éden for maior que 50% de S1, ele entrará diretamente na velhice.
Noções básicas de ajuste de JVM
Ao entrar na versão java,

haverá dois mecanismos diferentes, cliente ou servidor.O mecanismo do cliente é mais baseado em aplicativos de desktop e o espaço alocado é relativamente menor do que o do servidor.No entanto, o mecanismo do servidor irá desperdiçar espaço. O mecanismo pode ser modificado em jre.
Pontos que podem ser ajustados para JVM:
- Escolha o cliente ou o mecanismo do servidor
- Para a alocação do tamanho do heap, ajuste manualmente os parâmetros.
Por exemplo: -Xms: tamanho inicial do heap
-Xmx: tamanho máximo do heap
-XX: Novo tamanho: n: define o tamanho da geração jovem - A escolha do coletor de lixo
Coletor de lixo na JVM:

A conexão significa que o coletor pode ser usado junto
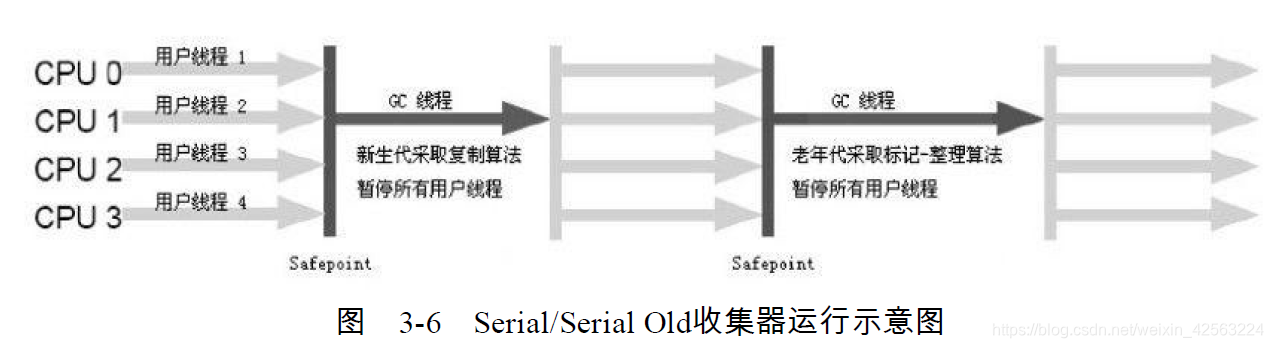
Coletor serial: O único coletor secundário é um coletor serial, STW (pare o mundo): pause todo o encadeamento durante a coleta. (A imagem vem da Internet)
Observação A
nova geração usa o algoritmo de replicação, enquanto a geração anterior usa o algoritmo de acabamento
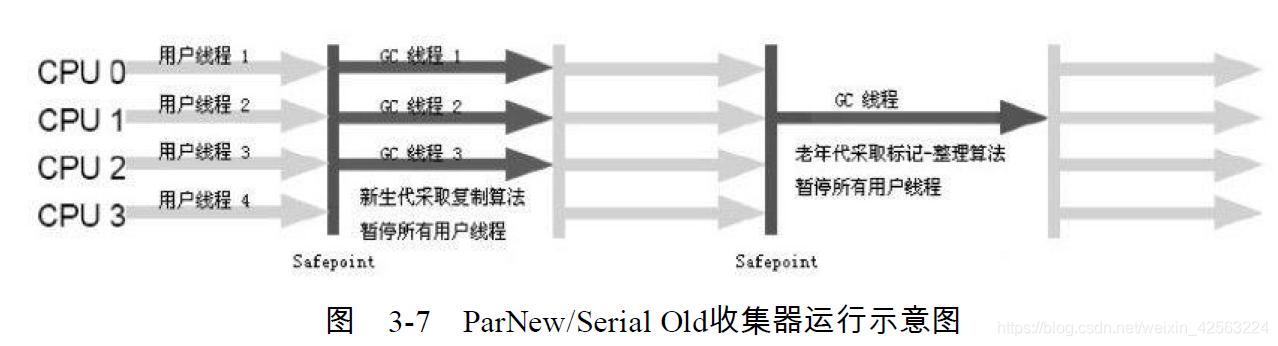
parNew coletor: o coletor paralelo é o coletor padrão do CMS. A CPU de vários núcleos pode mostrar a capacidade, e os efeitos de núcleo único e serial são os mesmos. (A imagem vem da Internet)
Paralelo: Melhore a taxa de transferência Taxa de transferência do
sistema = tempo de execução do código / (tempo de execução do código + tempo de coleta de lixo)
Coletor CMS: coleta de lixo e execução simultânea de threads de usuário
G1: Tanto o lixo da nova geração quanto o da velha geração podem ser reciclados
Algoritmos de coleta de lixo comumente usados
1. Contagem de referência:
Se um objeto tiver uma referência, aumentará em 1 e, se for menor, será reduzido em 1. Se for 0, será reciclado.A desvantagem é que não pode resolver o problema das referências circulares.
2. Copiar algoritmo:
Dividido em duas áreas iguais, apenas copie o objeto que está sendo processado, a cópia pode ser organizada de forma ordenada no passado, não há fragmentação do espaço, desvantagem: precisa do dobro do espaço
3. Algoritmo de marcação clara:
No primeiro estágio, todos os objetos referenciados são marcados a partir do nó raiz referenciado e, no segundo estágio, todo o heap é percorrido e os objetos marcados são limpos. Esse algoritmo precisa suspender todo o aplicativo e, ao mesmo tempo, vai gerar fragmentação da memória.
4. Algoritmo de classificação e marcação:
Este algoritmo é uma otimização de mark-sweep. Depois que o método mark-sweep é usado para limpar, os objetos sobreviventes são pressionados em uma área na pilha e organizados em ordem, o que resolve o problema de fragmentação de memória de mark-sweep e o espaço para atribuição. problema.
As notas acima são minhas próprias notas sobre a JVM. Elas estão incompletas e serão aprimoradas gradualmente no futuro!
Vamos!