anuário
Em K8S Todos os objetos são chamados de recursos, tais como: vagem, serviço, etc.
recursos pod
recipiente pod é a menor unidade no K8S na frente mencionadas, K8S suporte a recursos avançados de auto-cura, expansão flexível e assim por diante, por isso, se você simplesmente executar docker negócios em K8S nó é nenhuma maneira de apoiar esses recursos avançados, deve ser personalizado , então, é este pod funcionários personalizou uma boa suportes de contentores recursos avançados, quando se inicia um pod, haverá pelo menos dois recipientes pod容器``和业务容器, tráfego de contentores irá partilhar mais do que um recipiente pod (um recipiente de coleção), seguida pod em um recipiente namespace rede compartilhada,
Pod classificação contentor
- Infrastructure Container: Recipiente base, manutenção de todo o espaço da rede Pod
- InitContainers: recipiente de inicialização, antes do negócio recipiente começou
- Contentores: negócio recipiente, iniciadas em paralelo
O significado da existência Pod: a existir fechar aplicativos
- interação arquivo entre as duas aplicações
- Duas aplicações requerem comunicação através 127.0.0.1 ou socker
- Duas aplicações requerem frequente ocorrência de chamadas
estratégia puxando espelho
imagePullPolicy
1、ifNotPresent:默认值,镜像在宿主机上不存在时才拉取
2、Always:每次创建Pod都会重新拉取一次镜像
3、Never:Pod永远不会主动拉取这个镜像 1.pod operações básicas
// 指定yaml文件创建pod
kubectl create -f [yaml文件路径]
// 查看pod基本信息
kubectl get pods
// 查看pod详细信息
kubectl describe pod [pod名]
// 更新pod(修改了yaml内容)
kubectl apply -f [yaml文件路径]
// 删除指定pod
kubectl delete pod [pod名]
// 强制删除指定pod
kubectl delete pod [pod名] --foce --grace-period=02.pod yaml perfil
apiVersion: v1
kind: Pod
metadata:
name: nginx01
labels:
app: web
spec:
containers:
- name: nginx01
image: reg.betensh.com/docker_case/nginx:1.13
ports:
- containerPort: 80Pod das relações com controladores
- controladores de: administração de objeto e operação do recipiente sobre um cluster
- por
label-selectorassociada - Pod aplicado pelo controlador para conseguir a operação e manutenção, tal como estiramento, laminagem de actualização.
controlador de cópia RC
copiar replicação do controlador de controlador, aplicação de hospedagem após Kubernetes, Kubernetes necessidade de assegurar que as aplicações podem continuar a executar, este é o conteúdo do trabalho RC, ele irá garantir que nenhum Kubernetes tempo em ambos um número especificado de Pod está sendo executado. Nesta base, RC também oferece algumas funcionalidades avançadas, tais como um upgrade, rollback atualização sem interrupção e assim por diante.
ReplicaSet recomendada (referido como RS) na nova versão do Kubernetes no lugar de ReplicationController
1. Crie um rc
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 2
selector:
app: myweb
template:
metadata:
labels:
app: myweb
spec:
containers:
- name: nginx01
image: reg.betensh.com/docker_case/nginx:1.13
ports:
- containerPort: 80Por padrão, pod名ele será rc名+随机值composto da seguinte forma:
[root@k8s-master01 rc]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myweb-0lp57 1/1 Running 0 45s
myweb-zgfcf 1/1 Running 0 45sRC para controlar o pod por tag selector (etiquetas), o nome do RC deve ser o mesmo nome e no seletor de tags
[root@k8s-master01 rc]# kubectl get rc -o wide
NAME DESIRED CURRENT READY AGE CONTAINER(S) IMAGE(S) SELECTOR
myweb 2 2 2 12m nginx01 reg.betensh.com/docker_case/nginx:1.13 app=myweb2.RC atualização sem interrupção
Nós já criou uma versão v1 de http-servidor no ambiente K8S vagem, como fazer se quisermos fazer uma versão atualizá-lo? É o pod originais parou, e depois usar a nova imagem para puxar um novo pod-lo, isso seria claramente inadequada.
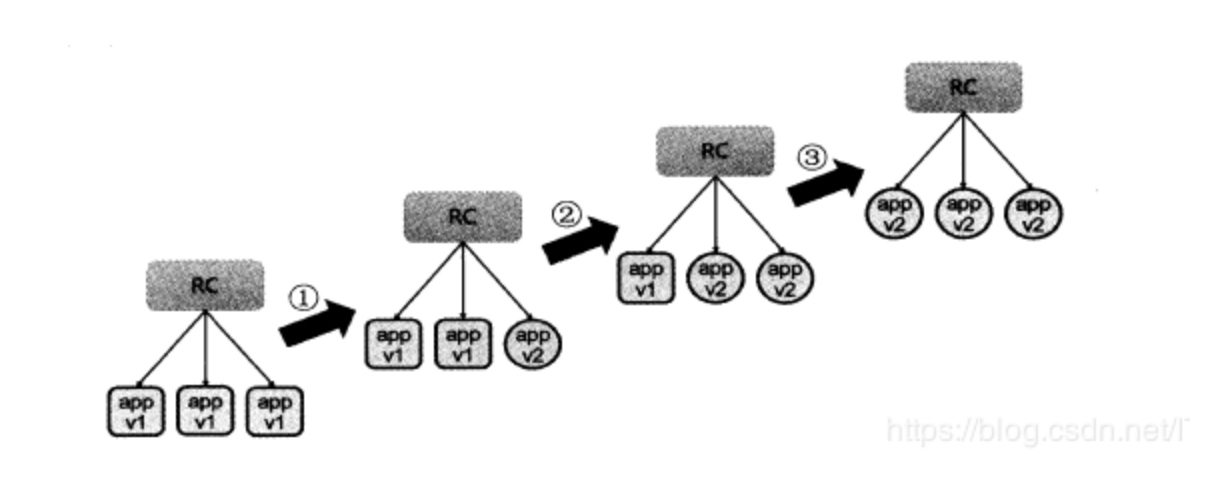
kubectl rolling-update myweb -f nginx_rc_v2.yaml --update-period=30s3.RC rolando fallback
suposições myweb agora atualizar para myweb2, bug apareceu, então forçado a interromper a atualização
kubectl rolling-update myweb -f nginx_rc_v2.yaml --update-period=50sEntão back roll para a versão myweb myweb2
kubectl rolling-update myweb myweb2 --rollback implantação de recursos
implantação é também uma forma de manter pod altamente disponível, não é, obviamente, a implantação por RC também introduziu dele?
Porque os resolve implantação de um ponto de dor de RC, quando o recipiente atualização de versão RC, o rótulo vai mudar, então svc de rótulos ou o original, então você precisa modificar manualmente a configuração arquivos svc.
Implantação de Pode ReplicaSetacima, para proporcionar uma indicação definida no método de fórmula (declarativa), usado para substituir anterior ReplicationControllerpara facilitar a aplicação de gestão.
Você só precisa Deploymentdescrever você quer 目标状态o que é que Deployment controllerirá ajudá-lo Pode ReplicaSeto estado real de mudança para o seu 目标状态. Você pode definir um novo Deploymentpara criar ReplicaSetou excluir existente Deploymente criar um novo para substituir. Que Deploymenté 管理多个ReplicaSet, como mostrado abaixo:
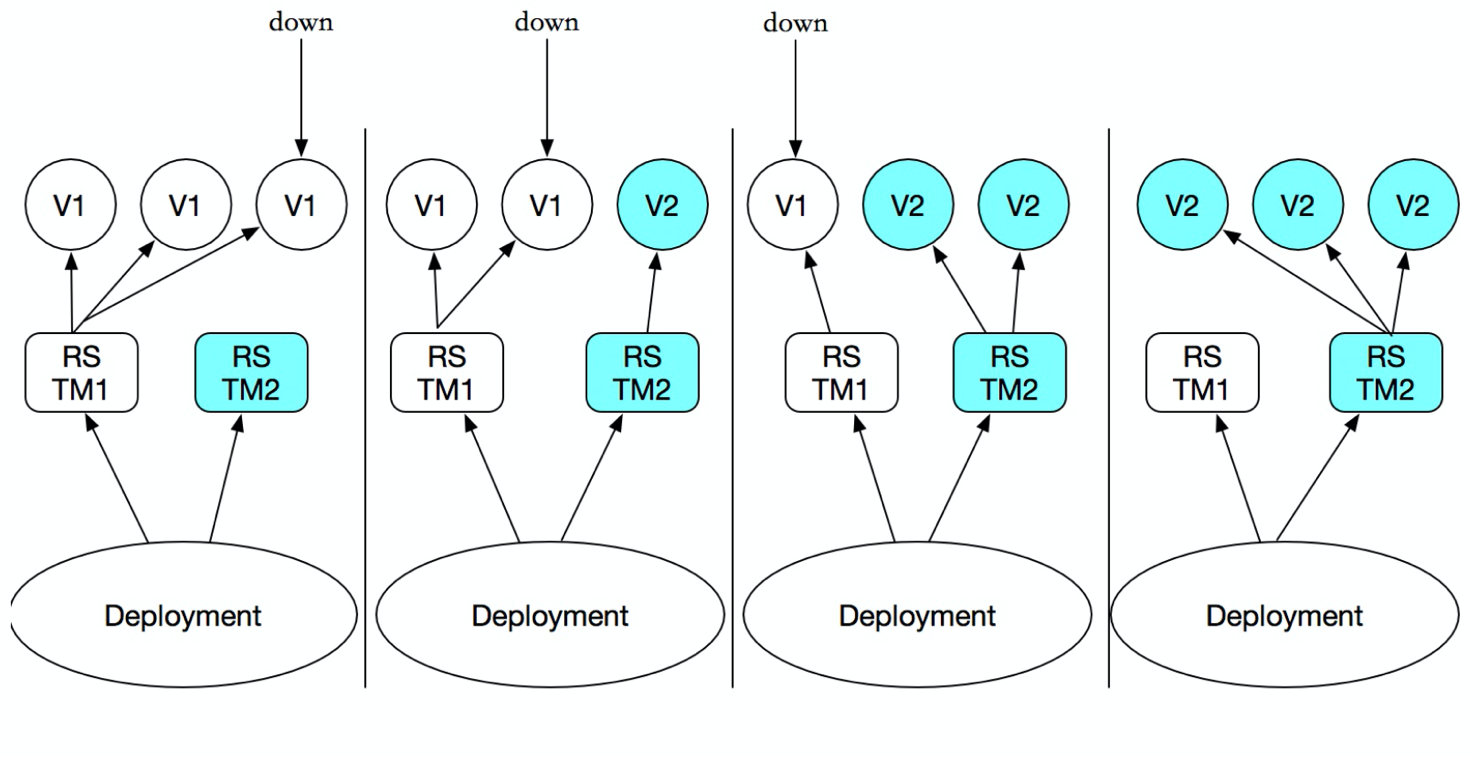
Embora ReplicaSet pode ser usado de forma independente, mas recomenda-se usar a implantação de gerir automaticamente ReplicaSet, então não há necessidade de se preocupar com com outras incompatibilidades mecanismos
1. Criar uma implantação
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.13
ports:
- containerPort: 80
// 启动
[root@k8s-master01 deploy]# kubectl create -f nginx_deploy.yamlVer estado de inicialização implantação
implantação irá iniciar um rs, em seguida, iniciar vagem
[root@k8s-master01 deploy]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-fcfcc984f-t2bk4 1/1 Running 0 33s
pod/nginx-deployment-fcfcc984f-vg7qt 1/1 Running 0 33s
pod/nginx-deployment-fcfcc984f-zhwxg 1/1 Running 0 33s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deployment 3/3 3 3 33s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-deployment-fcfcc984f 3 3 3 33s2. serviço associado
kubectl expose deployment nginx-deployment --port=80 --type=NodePortVer svc
[root@k8s-master01 deploy]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16h
nginx-deployment NodePort 10.96.171.141 <none> 80:31873/TCP 25sendereço Svc e acesso à porta
[root@k8s-master01 deploy]# curl -I 10.0.0.33:31873
HTTP/1.1 200 OK
Server: nginx/1.13.12
Date: Thu, 14 Nov 2019 05:44:51 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Mon, 09 Apr 2018 16:01:09 GMT
Connection: keep-alive
ETag: "5acb8e45-264"
Accept-Ranges: bytesatualização 3.deployment
// 直接编辑对应deployment,并修改镜像版本
kubectl edit deployment nginx-deployment
// 通过 set image 发布新的镜像
kubectl set image deploy nginx-deployment nginx-deployment=nginx:1.174.deployment rollback
// 回滚到上一级版本
kubectl rollout undo deployment nginx-deployment
// 回滚到指定版本
kubectl rollout undo deployment nginx-deployment --to-revision=1
// 查看当前deploy历史版本
kubectl rollout history deployment nginx-deploymentA versão de linha de comando para conseguir liberação
# kubectl run nginx --image=nginx:1.13 --replicas=3 --record
# kubectl rollout history deployment nginx
deployment.extensions/nginx
# kubectl set image deployment nginx nginx=nginx:1.15 Serviço Headless
Em K8S, do jeito que queremos para acessar o serviço através de um nome que é Deploymentpara adicionar uma camada em cima Service, para que possamos Service nameacessar o serviço, e aquilo que é o princípio e CoreDNSrelevante, ele será Service nameanalisado em Cluster IP, portanto, visitou Cluster IPquando em por IP de cluster para balanceamento de carga do tráfego em toda 各个PODa parte superior. Acho que a questão é CoreDNSse ele vai resolver diretamente o nome de POD, o serviço no Serviço, não é possível porque existem IP Cluster Service, diretamente CoreDNS resolvido, então como ele pode fazer para resolver POD, um grande levantou gado você pode usar Headless Service, por isso temos de explorar o que é Headless Service.
Headless ServiceÉ uma espécie de Service, exceto que define spec:clusterIP: None, ou seja, não precisa Cluster IP的Service.
Nós primeiro pensar Service的Cluster IPdas obras: a Servicepode corresponder a múltiplos EndPoint(Pod), cliento acesso é Cluster IPatravés iptablesdas regras ir Real Server, de modo a alcançar o equilíbrio de carga. operação específica é a seguinte:
1, WEB-demo.yaml
#deploy
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: web-demo
namespace: dev
spec:
# 指定svc名称
serviceName: web-demo-svc
replicas: 3
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: 10.0.0.33/base_images/web-demo:v1.0
ports:
- containerPort: 8080
resources:
requests:
memory: 1024Mi
cpu: 500m
limits:
memory: 2048Mi
cpu: 2000m
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 3
successThreshold: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /hello
port: 8080
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 1
successThreshold: 1
timeoutSeconds: 5
---
#service
apiVersion: v1
kind: Service
metadata:
name: web-demo-svc
namespace: dev
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
clusterIP: None
selector:
app: web-demoVer svc, encontrou ClusterIPcomoNone
$ kubectl get svc -n dev | grep "web-demo-svc"
web-demo-svc ClusterIP None <none> 80/TCP 12spod cria ordem
$ kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
web-demo-0 1/1 Running 0 7m2s
web-demo-1 1/1 Running 0 6m39s
web-demo-2 1/1 Running 0 6m15sFaça logon no interior do Cluster pod
$ kubectl exec -it web-demo-0 sh -n dev
/ # nslookup web-demo-svc
Name: web-demo-svc
Address 1: 10.244.2.67 web-demo-0.web-demo-svc.dev.svc.cluster.local
Address 2: 10.244.3.12 web-demo-2.web-demo-svc.dev.svc.cluster.local
Address 3: 10.244.1.214 web-demo-1.web-demo-svc.dev.svc.cluster.localResumo: dns acessado através, retorna uma lista de vagens de back-end
StatefulSet
Em primeiro lugar, Deploymenta fim Pod apenas serviço de apátrida, e não há indiferenciado, a ordem entre o apoio StatefulSet pluralidade Pod, para cada Pod tem seu próprio número, necessitem de acesso a outro e fazer a distinção entre o armazenamento persistente
pod sequencial
1, sem cabeça-service.yaml
apiVersion: v1
kind: Service
metadata:
name: springboot-web-svc
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
clusterIP: None
selector:
app: springboot-web2, statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: springboot-web
spec:
# serviceName 该字段是告诉statefulSet用那个headless server去保证每个的解析
serviceName: springboot-web-svc
replicas: 2
selector:
matchLabels:
app: springboot-web
template:
metadata:
labels:
app: springboot-web
spec:
containers:
- name: springboot-web
image: 10.0.0.33/base_images/web-demo:v1.0
ports:
- containerPort: 8080
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 3
successThreshold: 1
timeoutSeconds: 5Ver pod
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
springboot-web-0 1/1 Running 0 118s
springboot-web-1 1/1 Running 0 116sDigite um pod, e visitar outro pod pelo nome pod
$ kubectl exec -it springboot-web-0 sh
/ # ping springboot-web-1.springboot-web-svc
PING springboot-web-1.springboot-web-svc (10.244.2.68): 56 data bytes
64 bytes from 10.244.2.68: seq=0 ttl=62 time=1.114 ms
64 bytes from 10.244.2.68: seq=1 ttl=62 time=0.698 msarmazenamento persistente
é automaticamente criado com base em pvc pod
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-demo
spec:
serviceName: springboot-web-svc
replicas: 2
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: springboot-web
spec:
containers:
- name: springboot-web
image: 10.0.0.33/base_images/nginx:1.13
ports:
- containerPort: 8080
volumeMounts:
- name: data
mountPath: /
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
storageClassName: glusterfs-storage-class
resources:
requests:
storage: 1GiDaemonSet
DaemonSet em Kubernetes1.2 nova versão de um objetos de recurso
DaemonSetEle permite que 所有(或者一些特定)的Nodeos nós 仅运行一份Pod. Quando um nó de cluster é adicionado aos Kubernetes, Pod será (DaemonSet) programado para ser executado no nó, quando o nó é removido Kubernetes cluster é (DaemonSet) agendada Pod será removido se você excluir DaemonSet, com tudo isso DaemonSet vagens relacionados serão excluídos.
Ao executar o aplicativo usando Kubernetes, precisamos de um monte de tempo 区域(zone)ou 所有Nodeem execução 同一个守护进程(pod), por exemplo, a cena seguinte:
- Cada nó de execução em um daemon armazenamento distribuídos, tais como glusterd, cef
- colector Run Log em cada nó, por exemplo fluentd, logstash
- operação de aquisição de monitorização de terminal em cada nó, por exemplo prometheus nó exportador, collectd etc.
Pod DaemonSet de expedição e RC é semelhante, com excepção de que o algoritmo de escalonamento sistema construído em cada nó de agendamento, ou pode ser utilizado NodeSelector NodeAffinity pod na definição para especificar uma gama que satisfaça a condição de agendamento Nó
formato de arquivo de recurso DaemonSet
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:Os exemplos que se seguem são definidos como o início de cada nó num filebeatrecipiente, em que as montagens hospedeiras do directório "/ var / log / mensagens"
$ vi k8s-log-filebeat.yaml
apiVersion: v1
kind: ConfigMap # 定义一个config文件内容
metadata:
name: k8s-logs-filebeat-config
namespace: kube-system
data:
# 填写filebeat读取日志相关信息
filebeat.yml: |-
filebeat.prospectors:
- type: log
paths:
- /messages
fields:
app: k8s
type: module
fields_under_root: true
output.logstash:
# specified logstash port (by default 5044)
hosts: ['10.0.0.100:5044']
---
apiVersion: apps/v1
kind: DaemonSet # DaemonSet 对象,保证在每个node节点运行一个副本
metadata:
name: k8s-logs
namespace: kube-system
spec:
selector:
matchLabels:
project: k8s
app: filebeat
template:
metadata:
labels:
project: k8s
app: filebeat
spec:
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:6.8.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 500Mi
securityContext:
runAsUser: 0
# 进行实际挂载操作
volumeMounts:
# 将configmap里的配置挂载到 /etc/filebeat.yml 文件中
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
# 将宿主机 /var/log/messages 路径挂载到 /messages中
- name: k8s-logs
mountPath: /messages
# 定义卷
volumes:
- name: k8s-logs
hostPath:
path: /var/log/messages
type: File
- name: filebeat-config
configMap:
name: k8s-logs-filebeat-configO DeamonSet criado usando kubectl comando create
$ kubectl create -f k8s-log-filebeat.yaml
configmap/k8s-logs-filebeat-config created
daemonset.apps/k8s-logs createdVerifique o criado DeamonSet e Pod, pode ser visto em cada nó cria um Pod
$ kubectl get ds -n kube-system | grep "k8s-logs"
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
k8s-logs 2 2 0 2 0 <none> 2m15s
$ kubectl get pods -n kube-system -o wide | grep "k8s-logs"
k8s-logs-gw4bs 0/1 Running 0 87s <none> k8s-node01 <none> <none>
k8s-logs-p6r6t 0/1 Running 0 87s <none> k8s-node02 <none> <none>Na versão 1.6 mais tarde na Kubernetes, DaemonSet pode executar uma atualização sem interrupção, essa atualização de um modelo DaemonSet quando a cópia antiga Pod será eliminado automaticamente, enquanto nova cópia Pod é criado automaticamente, desta vez estratégia de atualização DaemonSet (Actualização da) é RollingUpdate, como segue:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: k8s-logs
namespace: kube-system
spec:
updateStrategy:
type: RollingUpdateActualização da Outro valor é OnDelete, isto é, somente quando apagar manualmente o Pod copiar DaemonSet criada uma nova cópia Pod será criado para fora, se você não definir o valor Actualização da, em seguida, em versões posteriores do 1,6 Kubernetes será a configuração padrão RollingUpdate (atualização sem interrupção).
Recursos de serviços
Nós todos sabemos que em Kubernetes para Pod unidade mínima de agendamento, e sua característica é a incerteza, que vai ser destruído a qualquer momento e re-criar incerteza levará cada Pod será implantado em diferentes N pelo agendador um nó nó, isso fará com que o endereço Pod ip vai mudar;
Por exemplo, cena web é dividido em backend front-end, as necessidades de front-end para recursos chamada de back-end, se o backend de Pod nascido de chumbo incerteza para um endereço IP diferente, de modo a frente definitivamente não é fazer endereço IP para a comutação automática de back-end de conexão, por isso precisamos de encontrar Pod Serviço e obter seu endereço IP.
relacionamento Pod com o Serviço
- Pod evitar o contacto perdida., Pod obter informações (via a etiqueta-selector associado)
- Pod define um conjunto de políticas de acesso (balanceamento de carga TCP / UDP 4 camadas)
- Apoiar ClusterIP, NodePort e LoadBalancer três tipos
- Servidor implementações subjacentes iptables e há dois tipos de modos de rede IPVS
Cada aplicação está associada a um serviço
Tipo de serviço
- ClusterIP: Por padrão, uma distribuição dentro do cluster pode acessar o IP virtual (VIP)
- NodePort: atribuir uma porta como uma entrada em cada nó de acesso externo
- LoadBalancer: trabalhar em um provedor de nuvem específica, como Google Cloud, AWS, OpenStack
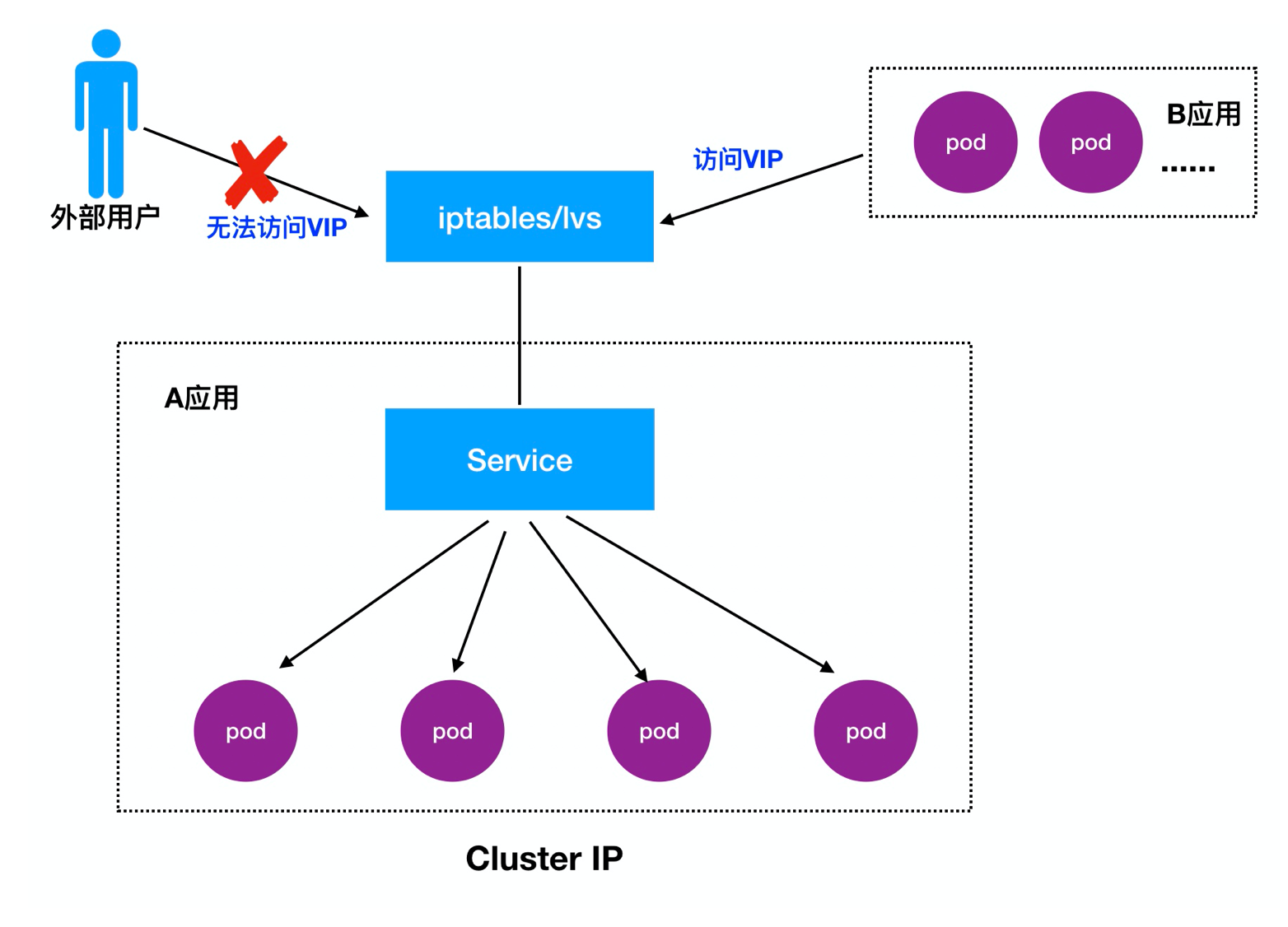
Detalhado 1.Cluster IP:
IP do cluster, também conhecida como VIP, principal realização de visitas entre diferentes Pod
type: NodePort
ports:
- port: 80
targetPort: 80
protocol: TCPAbrir proxy de acesso
do proxy kubectl para permitir o acesso de rede externa K8S serviço de ClusterIP
kubectl proxy --address='0.0.0.0' --accept-hosts='^*$' --port=8009
http://[k8s-master]:8009/api/v1/namespaces/[namespace-name]/services/[service-name]/proxyDetalhes: https: //blog.csdn.net/zwqjoy/article/details/87865283
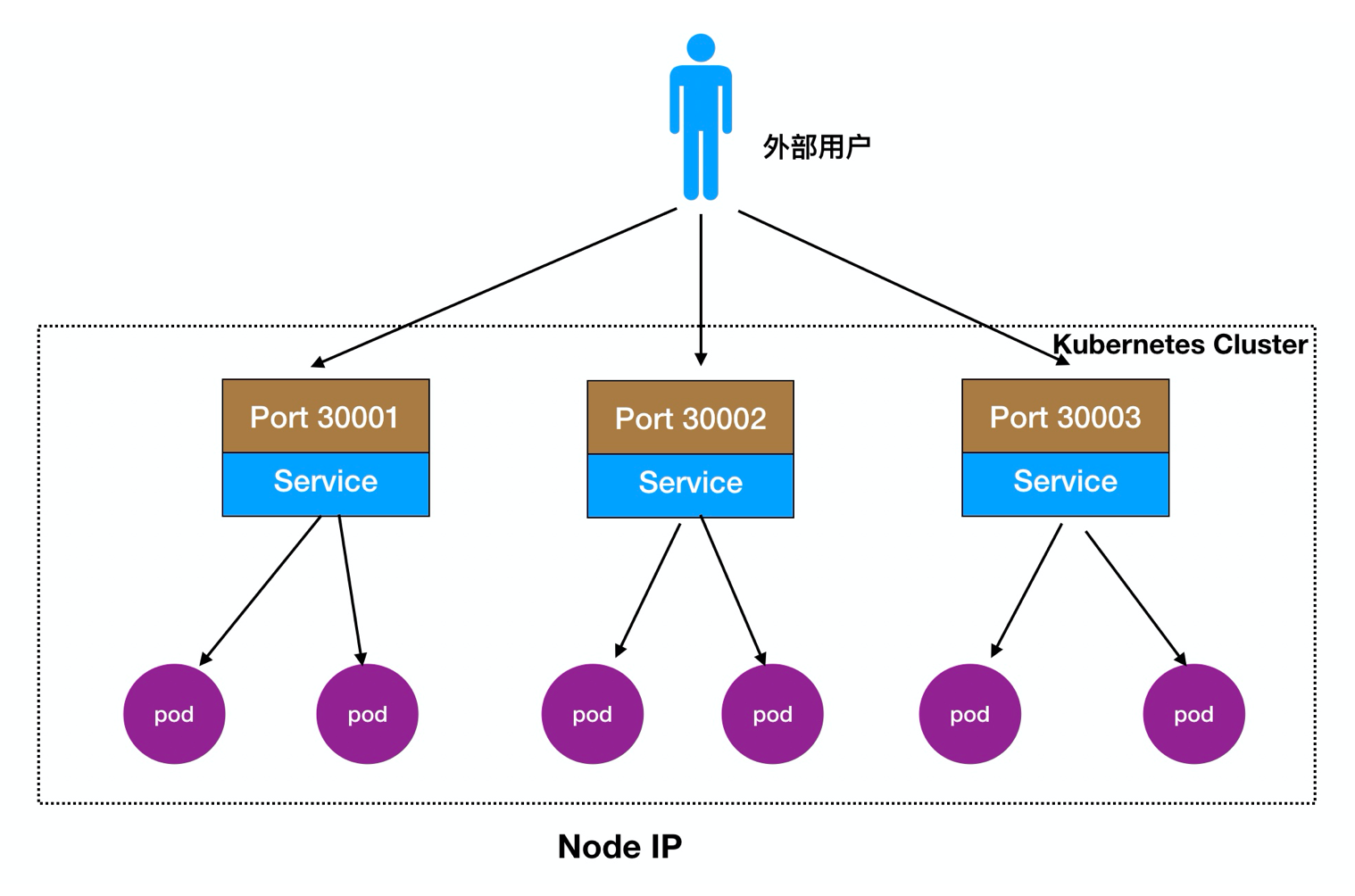
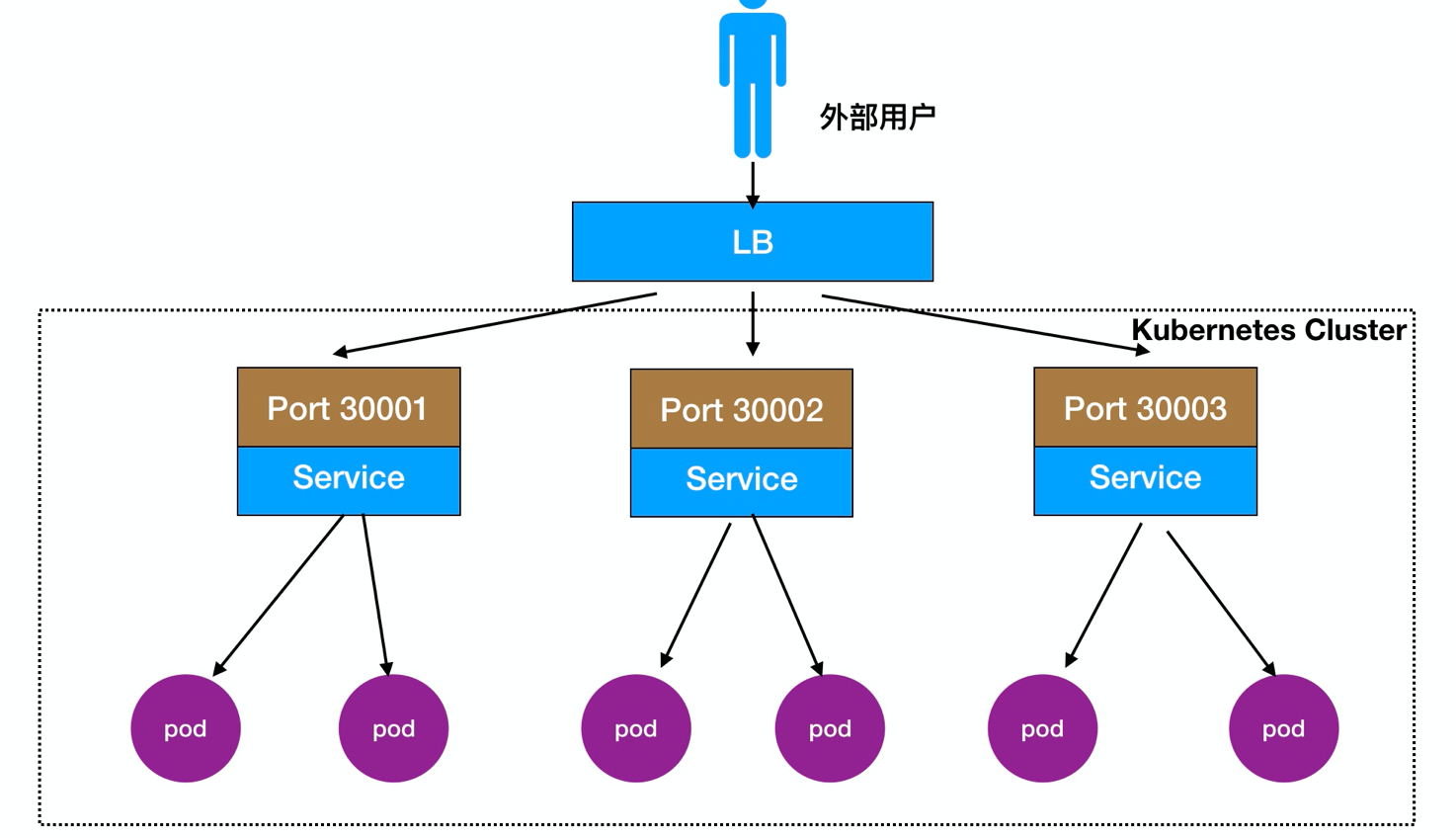
Detalhado 2.Node Porto:
Os usuários externos podem acessar nó implementado nó, nó Node vai fluir para a frente no seu interior Pod
Processo de acesso: Usuários -> Domínio -> Load Balancer -> NodeIP: Port -> PodIP: Porto
Ele também pode ser implantado em frente de um equilíbrio de carga Nó LB directamente, como mostrado:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30008
protocol: TCPparâmetro Descrição
spec.ports.port:vip端口(cluster ip)
spec.ports.nodePort:映射到宿主机的端口,即提供外部访问的端口
spec.ports.targetPort:pod 端口
spec.selector: 标签选择器Criando tipo nodePort de tempo será atribuído um IP de cluster, proporcionando acesso conveniente para entre Pod
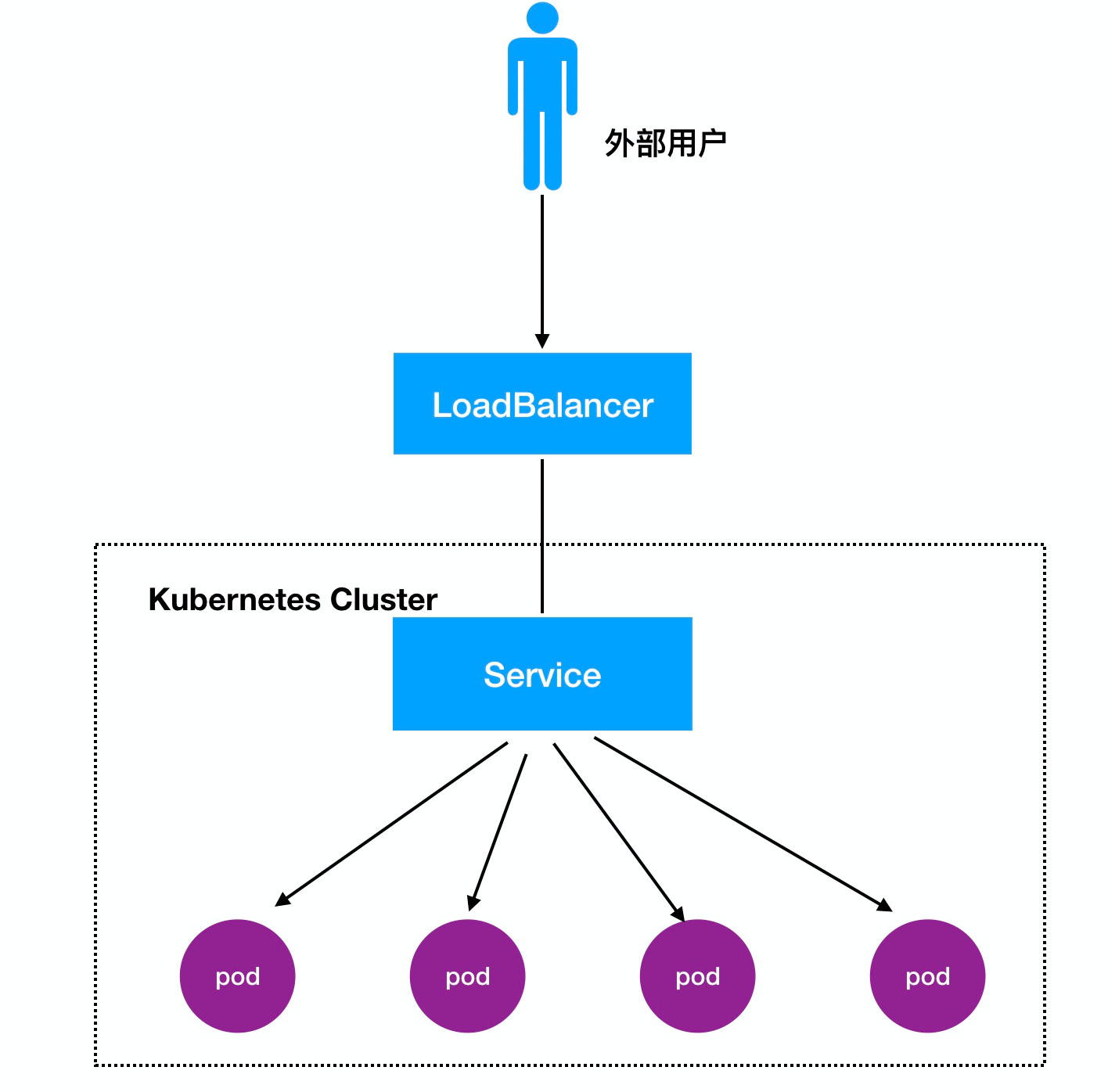
3, LoadBalancer Comentários:
Processo de Acesso: Usuários -> Domínio -> Load Balancer -> NodeIP: Port -> PodIP : Porto
cenários de mapeamento janela de encaixe convencionais:
Acesso -> nó IP: 10.0.0.12 -> recipiente janela de encaixe: 172.16.48.2
Se desligou quando janela de encaixe, uma janela de encaixe, recipiente mudança de endereço IP ocorre no reinício, antes de fazer isso e mapeamento nó janela de encaixe é inválido, é necessário modificar manualmente o mapa, por isso é muito problemático
assim, adicionar em K8S no IP cluster, 10.254.0.0/16,series segmento rede criará automaticamente o IP do cluster, também conhecido como vip, quando o pod é criado automaticamente registrado no serviço, e balanceamento de carga (a regra padrão como rr), se um pod desligou, ele será automaticamente rejeitado
Acesso -> nó IP: 10.0.0.13 -> Conjunto de IP: 10.254.0.0/16 (serviço) -> pod IP: 172.16.48.2
Criar um serviço
apiVersion: v1
kind: Service
metadata:
name: myweb
spec:
type: NodePort
ports:
- port: 80
nodePort: 30000
targetPort: 80
selector:
app: myweb
// 启动
kubectl create -f nginx-svc.yamlServiços para assumir o pod para ver se os serviços de rede normais:
[root@k8s-master01 svc]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 10.0.0.31:6443 2d
myweb 172.16.12.2:80,172.16.15.4:80 2mipvs e iptables obras
serviço subjacente encaminhamento de tráfego e balanceamento de carga para alcançar:
- iptables
- ipvs
1, um serviço vai criar um monte de regras de iptables (atualização, não-incrementais)
2, iptables regras são combinados um a um de cima para baixo (grande atraso).
Salvador: IPVS (modo kernel)
carga LVS equilibrar módulo de planejador IPVS do kernel implementada como: Ali nuvem do SLB, com base em quatro LVS alcançar balanceamento de carga.
iptables:
- Flexível, poderosa (o pacote pode operar em diferentes fases do pacote)
- E atualização travessia regras de jogo, um atraso linear
IPVS:
- Trabalhando no modo kernel, melhor desempenho
- algoritmos de escalonamento de rico: rr, WRR, lc, wlc, de hash ip ....