Este artigo descreve o python rastejar os dados da rede puxar gancho e visualização de dados, rastejando porta puxar gancho para python de dados relacionadas com o trabalho, e rastreamento em todos os tipos de dados ter sido arquivo CSV e, em seguida, relacionadas com arquivo CSV campos de dados, lavados e exibição de visualização de dados, incluindo a exibição gráfico de barras, uma visualização do histograma, pode referir-se a um amigo
prefácio
Rastejando porta de entrada para puxar os dados de posição gancho python informações e dados relacionados foi rastejando tipos arquivo CSV armazenado, e o arquivo CSV associada campo de dados é limpo, e a apresentação visual de dados, incluindo um gráfico de barras, histograma exibição FIG, exibir uma nuvem da palavra e similares, para posterior análise dos dados visuais, e exibir a análise restante pode jogar os seus leitores e expandido para incluir uma variedade de diferentes análise e armazenamento e similares. . . . .
Um rastreamento e dependências relacionados
versão Python: Python3.6
pedidos: página de download
de matemática: se arredondada
tempo: processo de parada
pandas: análise de dados e salvo como arquivo CSV
matplotlib: Desenho
pyecharts: Desenho
statsmodels: modelagem estatística
wordcloud, SciPy, jieba: Nuvem da palavra chinesa gerado
Pylab : conjunto de desenho para mostrar chineses
leitores podem encontrar problemas como a incapacidade de instalar ou importar mais do que a instalação ou usar seus próprios Baidu, selecione as dependências versão apropriada do
dois, análise de estrutura da página
pelo Chrome procurar 'engenheiro python', em seguida, clique com o botão direito no cheque ou F12, use a função de verificação para ver o código fonte da página, clique em Avançar quando observamos barra de pesquisa do navegador url não mudou, porque a rede fez mecanismo de gancho puxar anti-réptil, informações de posição não está no código fonte, e JSON é guardada no arquivo, para que JSON download direto, e ler os dados diretamente usando o método de dicionário para começar os trabalhos informações python relevantes que queremos.

a ser rastejando informações sobre o trabalho engenheiro de python é a seguinte: 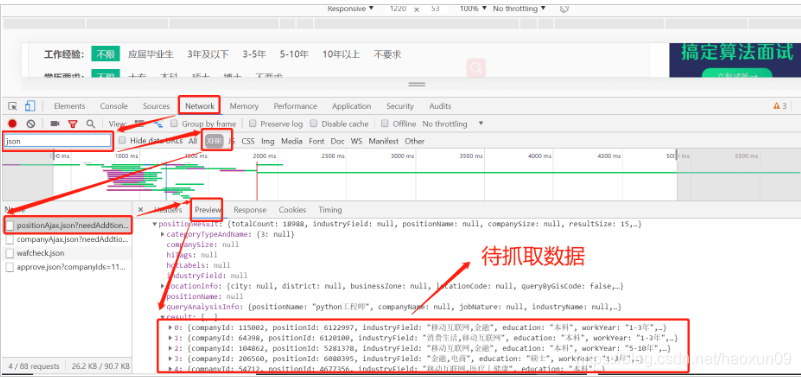
para ser capaz de subir queremos que os dados, usamos o programa de navegador simular a páginas da web vista, então eu No processo de rastreamento irá adicionar informações de cabeçalho, as informações do cabeçalho é a nossa adquirido por meio da análise de páginas web por web analytics sabemos cabeçalho do pedido, e como as informações solicitadas e a solicitação é uma solicitação POST, para que possamos a pedido de URL para obter os dados que queremos fazer mais processamento 
arrastou páginas de códigos de informação são os seguintes:
import requests
url = ' https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
def get_json(url, num):
"""
从指定的url中通过requests请求携带请求头和请求体获取网页中的信息,
:return:
"""
url1 = 'https://www.lagou.com/jobs/list_python%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'first': 'true',
'pn': num,
'kd': 'python工程师'}
s = requests.Session()
print('建立session:', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie:', cookie, '\n\n')
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('请求响应结果:', page_data, '\n\n')
return page_data
print(get_json(url, 1))
Sabemos que por pesquisar empregos por página 15, mostra até 30, analisando o código fonte da página web para saber o número total de mensagens podem ser lidas por JSON, através do número total de lugares eo número de postos de trabalho por página pode ser exibida. Podemos calcular o número total de páginas, e depois usar o ciclo de página rastreamento e, finalmente, a informação pós resumo é escrito para um arquivo no formato CSV.
Os resultados são mostrados em execução: 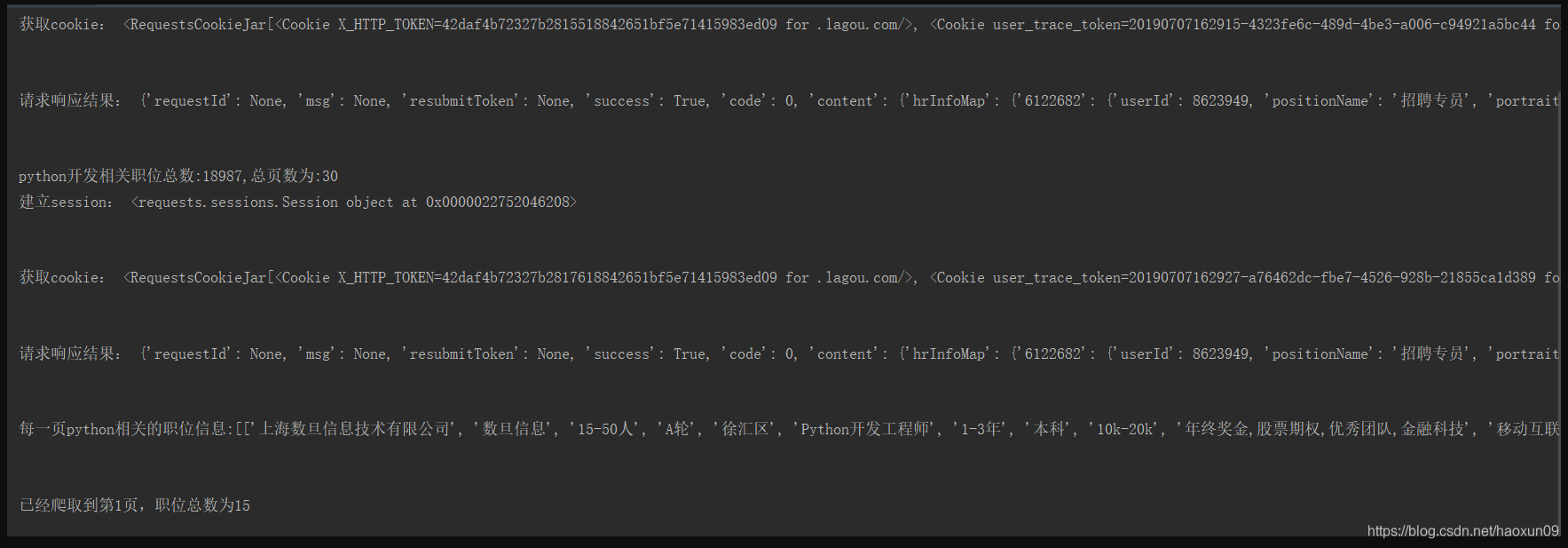
rastejando todos relacionados python empregos informação é a seguinte: 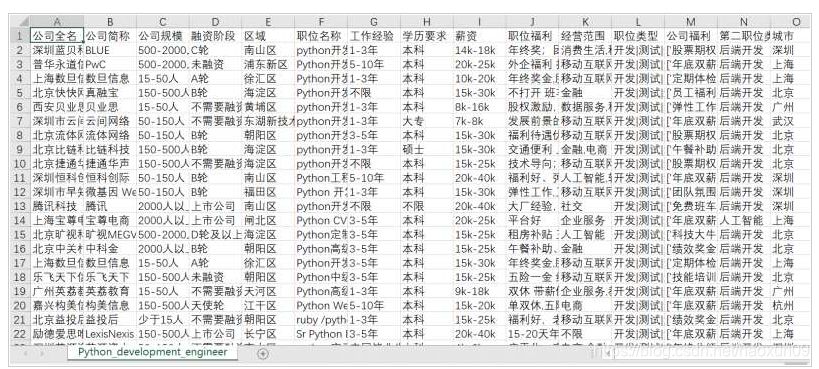
Em terceiro lugar, após a limpeza de armazenamento de dados
limpeza de dados vai realmente ocupam uma grande parte do trabalho que estamos aqui somente após algum armazenamento de análise de dados simples. No gancho puxar empregos relacionados com python entrada líquida será 18988. Você pode selecionar as necessidades de trabalho de campo para ser colocado no armazenamento, e alguns dos campos e não mais de triagem, por exemplo, nós podemos remover o nome correios como estagiários, pós área de campo de filtro especificado na nossa área designada, entrar em campo da folha de pagamento em média, um quarto do valor mínimo e que a diferença entre a média e por isso é livre para jogar em demanda
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from wordcloud import WordCloud
from scipy.misc import imread
from imageio import imread
import jieba
from pylab import mpl
# 使用matplotlib能够显示中文
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
df = pd.read_csv('Python_development_engineer.csv', encoding='utf-8')
# 进行数据清洗,过滤掉实习岗位
# df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True)
# print(df.describe())
# 由于csv文件中的字符是字符串形式,先用正则表达式将字符串转化为列表,在去区间的均值
pattern = '\d+'
# print(df['工作经验'], '\n\n\n')
# print(df['工作经验'].str.findall(pattern))
df['工作年限'] = df['工作经验'].str.findall(pattern)
print(type(df['工作年限']), '\n\n\n')
avg_work_year = []
count = 0
for i in df['工作年限']:
# print('每个职位对应的工作年限',i)
# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0
if len(i) == 0:
avg_work_year.append(0)
# print('nihao')
count += 1
# 如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
# print('hello world')
avg_work_year.append(int(''.join(i)))
count += 1
# 如果匹配为一个区间则取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list) / 2
avg_work_year.append(avg_year)
count += 1
print(count)
df['avg_work_year'] = avg_work_year
# 将字符串转化为列表,薪资取最低值加上区间值得25%,比较贴近现实
df['salary'] = df['薪资'].str.findall(pattern)
#
avg_salary_list = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_salary = int_list[0] + (int_list[1] - int_list[0]) / 4
avg_salary_list.append(avg_salary)
df['月薪'] = avg_salary_list
# df.to_csv('python.csv', index=False)
Em quarto lugar, espectáculos de visualização de dados
a seguir é uma apresentação visual dos dados, apenas uma visão parcial de alguma apresentação visual, se o leitor quer fazer algo para mostrar a outros campos e quer usar diferentes vista tipos em exposição, o seu próprio jogo, Nota: O código a seguir veja módulo introduzido última código completo
1, frequência histogramas desenhado python salário e salvo
se queremos ver na Internet empregos relacionados com a indústria engenheiro python salário era geralmente uma divisão do intervalo em que vão, a proporção representaram tanto quanto nós podemos ajudar biblioteca matplotlib para vamos salvar os dados na visualização do display arquivo CSV, e então podemos ver uma divisão mais intuitiva de dados de tendência
# 绘制python薪资的频率直方图并保存
plt.hist(df['月薪'],bins=8,facecolor='#ff6700',edgecolor='blue') # bins是默认的条形数目
plt.xlabel('薪资(单位/千元)')
plt.ylabel('频数/频率')
plt.title('python薪资直方图')
plt.savefig('python薪资分布.jpg')
plt.show()
Os resultados são os seguintes: 
2, desenhar posições relacionadas python geográficas gráficos de pizza
pela posição localização python geográfica da divisão podemos mais ou menos entender a indústria de TI está concentrada principalmente na divisão que as cidades, por isso optamos por ser mais propício ao emprego seletiva regionais você pode obter mais oportunidades de entrevista, os parâmetros podem depurar o seu próprio, ou adicionados, conforme necessário.
# 绘制饼状图并保存
city = df['城市'].value_counts()
print(type(city))
# print(len(city))
label = city.keys()
print(label)
city_list = []
count = 0
n = 1
distance = []
for i in city:
city_list.append(i)
print('列表长度', len(city_list))
count += 1
if count > 5:
n += 0.1
distance.append(n)
else:
distance.append(0)
plt.pie(city_list, labels=label, labeldistance=1.2, autopct='%2.1f%%', pctdistance=0.6, shadow=True, explode=distance)
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('python地理位置分布图.jpg')
plt.show()
Os resultados são os seguintes: 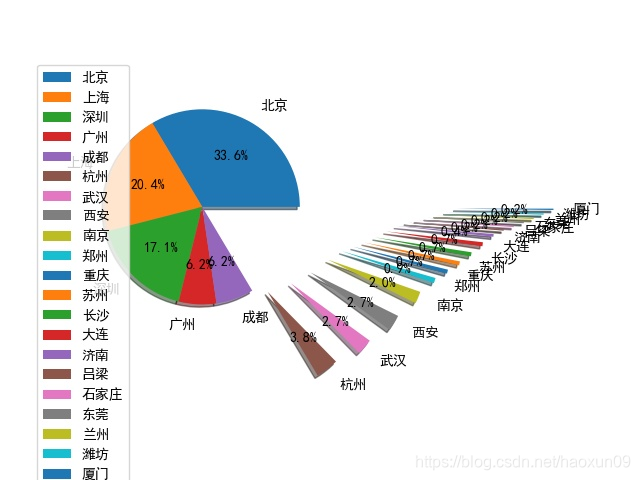
3, desenhados distribuição cidade pyechart histograma baseados
pycharts é js python Baidu chamada com base desenvolvido interface de echarts podem ser várias visualização de dados, mais representação gráfica de visualização de dados, echarts referência site oficial: https : //www.echartsjs.com/,echarts site oficial fornece vários exemplos para a nossa referência, tais como gráficos de linha, gráficos de barras, gráficos circulares, o roteiro, árvore e assim por diante, com base em pyecharts documentos referem-se a seguinte site oficial: https: //pyecharts.org/#/, Baidu também pode usar mais recursos de rede por conta própria
city = df['城市'].value_counts()
print(type(city))
print(city)
# print(len(city))
keys = city.index # 等价于keys = city.keys()
values = city.values
from pyecharts import Bar
bar = Bar("python职位的城市分布图")
bar.add("城市", keys, values)
bar.print_echarts_options() # 该行只为了打印配置项,方便调试时使用
bar.render(path='a.html')
Os resultados são os seguintes: 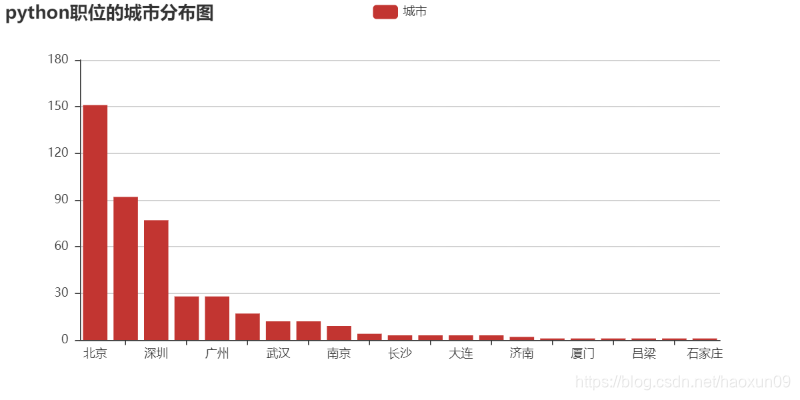
4, desenhar python bem-estar relacionada com a nuvem da palavra
palavra palavra nuvem em nuvem chamado, é uma alta freqüência de palavras-chave em dados de texto parecem ser proeminente forma visual "rendering palavra-chave" na mesma nuvem-como fotos coloridas, para filtrar um monte de informações de texto ,, pessoas pode-se apreciar o significado principal dos dados de texto expressão. Use palavra jieba e nuvem gerada WorldCloud (fundo customizável) palavra, o seguinte é a empregos python bem-estar relacionada fez uma nuvem da palavra do display, pode ser mais intuitivo para ver os benefícios para a maioria das empresas se concentrar em áreas em que para extrair o bem-estar # tratamento nuvem de palavras
text = ''
for line in df['公司福利']:
if len(eval(line)) == 0:
continue
else:
for word in eval(line):
# print(word)
text += word
cut_word = ','.join(jieba.cut(text))
word_background = imread('公主.jpg')
cloud = WordCloud(
font_path=r'C:\Windows\Fonts\simfang.ttf',
background_color='black',
mask=word_background,
max_words=500,
max_font_size=100,
width=400,
height=800
)
word_cloud = cloud.generate(cut_word)
word_cloud.to_file('福利待遇词云.png')
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
Os resultados são os seguintes:

quinto, répteis e visualização do código completo
código completo no código a seguir são de teste pode ser executado corretamente, sócio minoritário interessado em ir para tentar entender onde usar, como a execução ou falha de instalação do módulo pode ser realizada na seção de comentários comentários, vamos resolvê-lo
Se você acha que pode ajudar a apontar um louvor Oh, conteúdo original para ser reproduzida indicar a fonte! ! !
1, répteis código completo
A fim de evitar a solicitação freqüente de nosso site é restrito ip, escolhemos para dormir depois de um período de tempo rastejando em cada página, é claro, você também pode usar outros meios, tais como agentes auto-realização
import requests
import math
import time
import pandas as pd
def get_json(url, num):
"""
从指定的url中通过requests请求携带请求头和请求体获取网页中的信息,
:return:
"""
url1 = 'https://www.lagou.com/jobs/list_python%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'first': 'true',
'pn': num,
'kd': 'python工程师'}
s = requests.Session()
print('建立session:', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie:', cookie, '\n\n')
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('请求响应结果:', page_data, '\n\n')
return page_data
def get_page_num(count):
"""
计算要抓取的页数,通过在拉勾网输入关键字信息,可以发现最多显示30页信息,每页最多显示15个职位信息
:return:
"""
page_num = math.ceil(count / 15)
if page_num > 30:
return 30
else:
return page_num
def get_page_info(jobs_list):
"""
获取职位
:param jobs_list:
:return:
"""
page_info_list = []
for i in jobs_list: # 循环每一页所有职位信息
job_info = []
job_info.append(i['companyFullName'])
job_info.append(i['companyShortName'])
job_info.append(i['companySize'])
job_info.append(i['financeStage'])
job_info.append(i['district'])
job_info.append(i['positionName'])
job_info.append(i['workYear'])
job_info.append(i['education'])
job_info.append(i['salary'])
job_info.append(i['positionAdvantage'])
job_info.append(i['industryField'])
job_info.append(i['firstType'])
job_info.append(i['companyLabelList'])
job_info.append(i['secondType'])
job_info.append(i['city'])
page_info_list.append(job_info)
return page_info_list
def main():
url = ' https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
first_page = get_json(url, 1)
total_page_count = first_page['content']['positionResult']['totalCount']
num = get_page_num(total_page_count)
total_info = []
time.sleep(10)
print("python开发相关职位总数:{},总页数为:{}".format(total_page_count, num))
for num in range(1, num + 1):
# 获取每一页的职位相关的信息
page_data = get_json(url, num) # 获取响应json
jobs_list = page_data['content']['positionResult']['result'] # 获取每页的所有python相关的职位信息
page_info = get_page_info(jobs_list)
print("每一页python相关的职位信息:%s" % page_info, '\n\n')
total_info += page_info
print('已经爬取到第{}页,职位总数为{}'.format(num, len(total_info)))
time.sleep(20)
# 将总数据转化为data frame再输出,然后在写入到csv各式的文件中
df = pd.DataFrame(data=total_info,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '薪资', '职位福利', '经营范围',
'职位类型', '公司福利', '第二职位类型', '城市'])
# df.to_csv('Python_development_engineer.csv', index=False)
print('python相关职位信息已保存')
if __name__ == '__main__':
main()
2, a visualização de código completo
Envolve o uso de matplotlib visualização de dados, jieba, wordcloud, pyecharts, Pylab, scipy como módulo, o leitor pode compreender o uso dos próprios módulos individuais, e que se relacionam com vários parâmetros
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from wordcloud import WordCloud
from scipy.misc import imread
# from imageio import imread
import jieba
from pylab import mpl
# 使用matplotlib能够显示中文
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
df = pd.read_csv('Python_development_engineer.csv', encoding='utf-8')
# 进行数据清洗,过滤掉实习岗位
# df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True)
# print(df.describe())
# 由于csv文件中的字符是字符串形式,先用正则表达式将字符串转化为列表,在去区间的均值
pattern = '\d+'
# print(df['工作经验'], '\n\n\n')
# print(df['工作经验'].str.findall(pattern))
df['工作年限'] = df['工作经验'].str.findall(pattern)
print(type(df['工作年限']), '\n\n\n')
avg_work_year = []
count = 0
for i in df['工作年限']:
# print('每个职位对应的工作年限',i)
# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0
if len(i) == 0:
avg_work_year.append(0)
# print('nihao')
count += 1
# 如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
# print('hello world')
avg_work_year.append(int(''.join(i)))
count += 1
# 如果匹配为一个区间则取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list) / 2
avg_work_year.append(avg_year)
count += 1
print(count)
df['avg_work_year'] = avg_work_year
# 将字符串转化为列表,薪资取最低值加上区间值得25%,比较贴近现实
df['salary'] = df['薪资'].str.findall(pattern)
#
avg_salary_list = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_salary = int_list[0] + (int_list[1] - int_list[0]) / 4
avg_salary_list.append(avg_salary)
df['月薪'] = avg_salary_list
# df.to_csv('python.csv', index=False)
"""1、绘制python薪资的频率直方图并保存"""
plt.hist(df['月薪'], bins=8, facecolor='#ff6700', edgecolor='blue') # bins是默认的条形数目
plt.xlabel('薪资(单位/千元)')
plt.ylabel('频数/频率')
plt.title('python薪资直方图')
plt.savefig('python薪资分布.jpg')
plt.show()
"""2、绘制饼状图并保存"""
city = df['城市'].value_counts()
print(type(city))
# print(len(city))
label = city.keys()
print(label)
city_list = []
count = 0
n = 1
distance = []
for i in city:
city_list.append(i)
print('列表长度', len(city_list))
count += 1
if count > 5:
n += 0.1
distance.append(n)
else:
distance.append(0)
plt.pie(city_list, labels=label, labeldistance=1.2, autopct='%2.1f%%', pctdistance=0.6, shadow=True, explode=distance)
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('python地理位置分布图.jpg')
plt.show()
"""3、绘制福利待遇的词云"""
text = ''
for line in df['公司福利']:
if len(eval(line)) == 0:
continue
else:
for word in eval(line):
# print(word)
text += word
cut_word = ','.join(jieba.cut(text))
word_background = imread('公主.jpg')
cloud = WordCloud(
font_path=r'C:\Windows\Fonts\simfang.ttf',
background_color='black',
mask=word_background,
max_words=500,
max_font_size=100,
width=400,
height=800
)
word_cloud = cloud.generate(cut_word)
word_cloud.to_file('福利待遇词云.png')
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
"""4、基于pyechart的柱状图"""
city = df['城市'].value_counts()
print(type(city))
print(city)
# print(len(city))
keys = city.index # 等价于keys = city.keys()
values = city.values
from pyecharts import Bar
bar = Bar("python职位的城市分布图")
bar.add("城市", keys, values)
bar.print_echarts_options() # 该行只为了打印配置项,方便调试时使用
bar.render(path='a.html')
Recomendamos aprender Python fivela Qun: 913066266, olhar em como os idosos estão aprendendo! Do roteiro básico python desenvolvimento web para, répteis, django, mineração de dados, etc. [PDF, o código fonte real], projectos de dados de combate baseado em zero estão terminando. Dada a cada pequeno parceiro python! Todos os dias, Daniel explicar a tecnologia Python tempo, para compartilhar alguns métodos de aprendizagem ea necessidade de prestar atenção aos pequenos detalhes, clique Junte nossa alunos python encontro
é mais do que todo o conteúdo deste artigo, queremos aprendizagem ajuda
