Aqui dar uma simples Liezi, para capturar a imagem do título em casa!

O primeiro passo é a necessidade de fazer primeiro réptil camuflagem UA, UA inicia uma solicitação para o site fazendo-se passar disfarçado como um navegador, existe um parâmetro de cabeçalhos quando o pedido de solicitação de envio, podemos colocar este parâmetro em User-Agent cabeçalhos este parâmetro
cabeçalhos = { ' User-Agent ' : ' Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit / 537,36 (KHTML, como gecko) Cromo / 80.0.3987.149 Safari / 537,36 ' }
Você pode encontrar este parâmetro no navegador a ferramenta de captura de pacotes
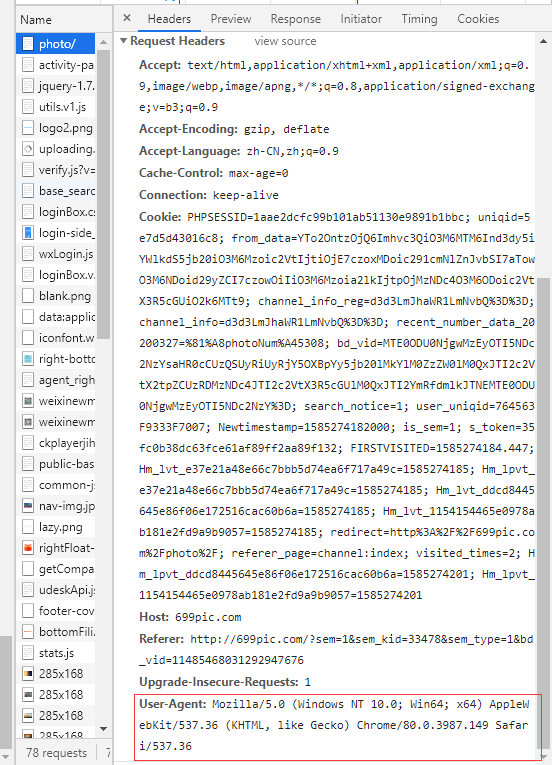
Bem, então podemos enviar uma solicitação para uma página para obter as páginas de dados!
importação pedidos de lxml importação etree cabeçalhos = { ' User-Agent ' : ' Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit / 537,36 (KHTML, como gecko) Cromo / 80.0.3987.149 Safari / 537,36 ' } url = ' http://699pic.com/photo/ ' Resposta = requests.get (url = url, headers = cabeçalhos) .text # neste momento para obter a página de dados
Em seguida, precisamos chegar ao etree alvo página propagação gerado
árvore = etree.HTML (resposta)
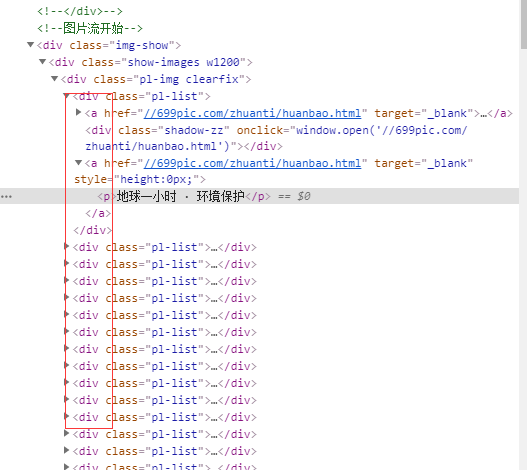
A partir deste gráfico, podemos ver que esta é uma imagem de cada div e estão na mesma div, o título está no interior de cada div tags p, div, então, podemos colocar isso em um só lugar, circulação foram para obtê-lo?
O resultado é óbvio, é claro que você pode
div_list = tree.xpath ( ' // div [@ class = "img-show"] / div / div / div ' ) print (div_list) para div em div_list: nome = div.xpath ( ' ./a [2] / p / text () ' ) [0] print (nome)
A primeira delas é uma coleção div imagem div_list, armazenado na impressão olhou para uma lista de

Esta lista é então reciclado, pode ser levado para fora dos elementos correspondentes no valor de p lista.
O efeito líquido:
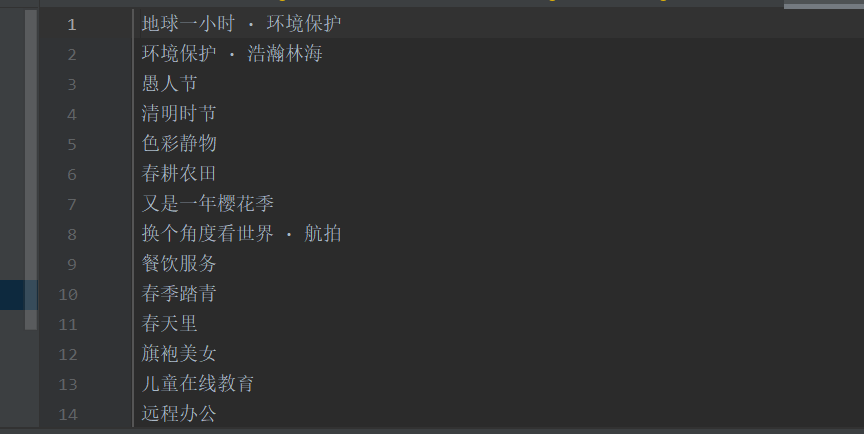
Todo o código é mostrado abaixo:
importação pedidos de lxml importação etree cabeçalhos = { ' User-Agent ' : ' Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit / 537,36 (KHTML, como gecko) Cromo / 80.0.3987.149 Safari / 537,36 ' } url = ' http://699pic.com/photo/ ' resposta = requests.get (URL = URL, cabeçalhos = cabeçalhos) .text árvore = etree.HTML (resposta) div_list = tree.xpath ( ' // div [@ class = "img-show"] / div / div / div ' ) print (div_list) f = aberto ( ' name.txt ' , ' w ' , que codifica = ' utf-8 ' ) para div em div_list: Nome = div.xpath ( ' ./a [2] / p / texto () ' ) [0] f.write (nome + ' \ n ' )