

▐ Lista negra de URL (filtro Bloom)
10 bilhões de URLs de lista negra, cada 64B, como salvar essa lista negra? Determine se um URL está na lista negra
Tabela hash:
Se considerarmos a lista negra como um conjunto e armazená-la em um hashmap, ela parece ser muito grande, exigindo 640G, o que obviamente não é científico.
Filtro de flor:
Na verdade, é um longo vetor binário e uma série de funções de mapeamento aleatório.
Pode ser usado para determinar se um elemento está em um conjunto . Sua vantagem é que ocupa apenas uma pequena quantidade de espaço de memória e possui alta eficiência de consulta. Para um filtro Bloom, sua essência é uma matriz de bits : uma matriz de bits significa que cada elemento da matriz ocupa apenas 1 bit e cada elemento pode ser apenas 0 ou 1.
Cada bit na matriz é um bit binário. Além de uma matriz de bits, o filtro Bloom também possui K funções hash. Quando um elemento é adicionado ao filtro Bloom, as seguintes operações serão realizadas:
Use K funções hash para realizar K cálculos no valor do elemento para obter K valores hash.
De acordo com o valor hash obtido, o valor do subscrito correspondente é definido como 1 na matriz de bits.
▐Estatísticas de frequência de palavras (divididas em arquivos)
2 GB de memória para encontrar o número mais frequente entre 2 bilhões de números inteiros
A abordagem usual é usar uma tabela hash para fazer estatísticas de frequência de palavras para cada número que aparece. A chave da tabela hash é um número inteiro e o valor registra o número de vezes que o número inteiro aparece. A quantidade de dados nesta questão é de 2 bilhões. É possível que um número apareça 2 bilhões de vezes. Para evitar overflow, a chave da tabela hash é de 32 bits (4B) e o valor também é de 32 bits (4B). ). Então, um registro de uma tabela hash precisa ocupar 8B.
Quando o número de registros da tabela hash é de 200 milhões, são necessários 1,6 bilhão de bytes (8 * 200 milhões) e pelo menos 1,6 GB de memória (1,6 bilhão/2 ^ 30,1 GB == 2 ^ 30 bytes == 1000000000 ). Então, 2 bilhões de registros requerem pelo menos 16 GB de memória, o que não atende aos requisitos da pergunta.
A solução é usar a função hash para dividir o arquivo grande com 2 bilhões de números em 16 arquivos pequenos. De acordo com a função hash, os 2 bilhões de dados podem ser distribuídos uniformemente pelos 16 arquivos. a função hash Em diferentes arquivos pequenos, assumindo que a função hash é boa o suficiente. Em seguida, use uma função hash para cada arquivo pequeno para contar o número de ocorrências de cada número, de modo que obtenhamos o número com mais ocorrências entre os 16 arquivos e, em seguida, selecione a chave com maior ocorrência entre os 16 números.
▐Número que não aparece (matriz de bits)
Encontre o número que não aparece entre 4 bilhões de inteiros não negativos
Para o problema original, se uma tabela hash for usada para salvar os números que apareceram, então, na pior das hipóteses, 4 bilhões de números são diferentes, então a tabela hash precisa salvar 4 bilhões de dados e um número inteiro de 32 bits requer 4B, então 4 bilhões * 4B = 16 bilhões de bytes Geralmente, cerca de 1 bilhão de bytes de dados requer 1G de espaço, portanto, requer cerca de 16G de espaço, o que não atende aos requisitos.
Vamos mudar a forma e solicitar uma matriz de bits. O tamanho da matriz é 4294967295, que é cerca de 4 bilhões de bits 4 bilhões/8 = 500 milhões de bytes, portanto, cada posição da matriz de bits tem dois estados: 0 e 1. Então, como usar essa matriz de bits? Haha, o comprimento da matriz atende apenas ao intervalo numérico de nossos números inteiros, então cada valor subscrito da matriz corresponde a um número em 4294967295 e percorre 4 bilhões de números sem sinal, um por um. Por exemplo, se 20 for encontrado, então bitArray. [20]= 1; quando 666 for encontrado, bitArray[666]=1, após percorrer todos os números, altere a posição correspondente do array para 1.
Encontre um número que não apareça entre 4 bilhões de números inteiros não negativos. O limite de memória é de 10 MB.
Um bilhão de bytes de dados requer cerca de 1 GB de espaço para processamento, portanto, 10 MB de memória podem processar 10 milhões de bytes de dados, o que equivale a 80 milhões de bits. Para 4 bilhões de números inteiros não negativos, se você solicitar uma matriz de bits, 4 bilhões de bits. /080 milhões de bits=50, então isso custará pelo menos 50 blocos para processar. Vamos analisar e responder usando 64 blocos.
Resuma as soluções avançadas
De acordo com o limite de memória de 10 MB, determine o tamanho do intervalo estatístico, que é o tamanho do bitArr durante a segunda travessia.
Use a contagem por intervalo para encontrar o intervalo com contagens insuficientes. Deve haver números neste intervalo que não aparecem.
Faça um mapeamento de mapa de bits dos números nesse intervalo e, em seguida, percorra o mapa de bits para encontrar um número que não apareça.
Minha própria opinião
Se você estiver apenas procurando um número, poderá realizar operações de módulo de bits altos, gravá-lo em 64 arquivos diferentes e, em seguida, processar tudo de uma vez por meio do bitArray no menor arquivo.
4 bilhões de inteiros sem sinal, 1 GB de memória, encontre todos os números que aparecem duas vezes
Para o problema original, o mapa de bits pode ser usado para representar a ocorrência de números. Especificamente, é para aplicar uma matriz de tipo de bit bitArr com comprimento de 4294967295×2. Duas posições são usadas para representar a frequência da palavra de um número 1B, portanto, a matriz de tipo de bit com comprimento de 4294967295×2. ocupa 1 GB de espaço. Como usar esse array bitArr? Percorra esses 4 bilhões de números não assinados. Se num for encontrado pela primeira vez, defina bitArr[num 2+1] e bitArr[num 2] como 01. Se num for encontrado pela segunda vez, defina bitArr[num 2+1 ] e bitArr[num 2] são definidos como 10. Se num for encontrado pela terceira vez, bitArr[num 2+1] e bitArr[num 2] são definidos como 11. Quando encontrar num novamente no futuro, descubro que bitArr[num 2+1] e bitArr[num 2] foram definidos como 11 neste momento, portanto, nenhuma configuração adicional será feita. Após a conclusão da travessia, percorra bitArr em sequência. Se for descoberto que bitArr[i 2+1] e bitArr[i 2] estão definidos como 10, então i é o número que aparece duas vezes.
▐URL duplicado (por máquina)
Encontre URLs duplicados entre 10 bilhões de URLs
A solução para o problema original usa um método convencional para resolver problemas de big data: atribuir arquivos grandes às máquinas por meio de uma função hash ou dividir arquivos grandes em arquivos pequenos por meio de uma função hash. Esta divisão é realizada até que o resultado da divisão atenda às restrições de recursos. Primeiro, você precisa perguntar ao entrevistador quais são as restrições de recursos, incluindo requisitos de memória, tempo de computação, etc. Depois de esclarecer os requisitos de restrição, cada URL pode ser alocado para várias máquinas por meio de uma função hash ou dividido em vários arquivos pequenos. O número exato de “vários” aqui é calculado com base em restrições de recursos específicas.
Por exemplo, um arquivo grande de 10 bilhões de bytes é distribuído para 100 máquinas por meio de uma função hash e, em seguida , cada máquina conta se há URLs duplicados nos URLs atribuídos a ela. o mesmo URL é É impossível distribuir o URL para máquinas diferentes ou dividir o arquivo grande em 1000 arquivos pequenos por meio da função hash em uma única máquina e, em seguida, usar a travessia da tabela hash para cada arquivo pequeno para encontrar URLs duplicados; distribua-o para a máquina ou após dividir os arquivos, classifique-os e verifique se há URLs duplicados após a classificação. Resumindo, lembre-se de que muitos problemas de big data são inseparáveis do descarregamento. A função hash distribui o conteúdo do arquivo grande para diferentes máquinas ou a função hash divide o arquivo grande em arquivos pequenos e, em seguida, processa cada pequeno número da coleção. .
▐ Pesquisa TOPK (pequena pilha de raízes)
Pesquise um grande número de palavras e encontre as 100 palavras mais populares.
No início, usamos a ideia de desvio de hash para desviar arquivos de vocabulário contendo dezenas de bilhões de dados para máquinas diferentes. O número específico de máquinas foi determinado pelo entrevistador ou por mais restrições. Para cada máquina, se a quantidade de dados distribuídos ainda for grande, por exemplo, devido a memória insuficiente ou outros problemas, a função hash pode ser usada para dividir os arquivos distribuídos de cada máquina em arquivos menores para processamento.
Ao processar cada arquivo pequeno, a tabela hash conta cada palavra e sua frequência de palavras. Depois que o registro da tabela hash é estabelecido, a tabela hash é percorrida. Durante a travessia da tabela hash, um pequeno heap raiz de tamanho 100 é usado para selecionar Obter o. top100 de cada arquivo pequeno (o top100 geral não classificado). Cada arquivo pequeno tem seu próprio heap raiz pequeno de frequência de palavras (o top100 geral não classificado). Ao classificar as palavras no heap raiz pequeno de acordo com a frequência de palavras, o top100 classificado de cada arquivo pequeno é obtido. Em seguida, classifique externamente os 100 primeiros de cada arquivo pequeno ou continue a usar o heap raiz pequeno para selecionar os 100 primeiros em cada máquina. Os 100 primeiros entre diferentes máquinas são então classificados externamente ou continuam a usar o pequeno heap raiz e, finalmente, os 100 primeiros de todas as dezenas de bilhões de dados são obtidos. Para o problema K superior, além do desvio de função hash e estatísticas de frequência de palavras usando tabelas hash, estruturas de heap e classificação externa são frequentemente usadas para lidar com isso.
▐Mediana (pesquisa binária unidirecional)
10 MB de memória, encontre a mediana de 10 bilhões de números inteiros
Memória suficiente: se você tiver memória suficiente, por que se preocupar? Basta classificar todos os 10 bilhões de itens. Você pode usar o borbulhamento... e então encontrar aquele que está no meio. Mas você acha que o entrevistador vai te dar memória? ?
Memória insuficiente: A pergunta diz que é um número inteiro, mas achamos que é um int assinado, portanto tem 4 bytes e ocupa 32 bits.
Suponha que 10 bilhões de números sejam armazenados em um arquivo grande, leia parte do arquivo na memória em sequência (sem exceder o limite de memória), represente cada número em binário e compare o bit mais alto do binário (bit 32, bit de sinal, 0 é positivo, 1 é negativo), se o bit mais alto do número for 0, o número será gravado no arquivo file_0; se o bit mais alto for 1, o número será gravado no arquivo file_1.
Assim, 10 bilhões de números são divididos em dois arquivos. Suponha que existam 6 bilhões de números no arquivo file_0 e 4 bilhões de números no arquivo file_1. Então a mediana está no arquivo file_0 e é o bilionésimo número após classificar todos os números no arquivo file_0. (Os números no arquivo_1 são todos números negativos e os números no arquivo_0 são todos números positivos. Ou seja, existem apenas 4 bilhões de números negativos no total, então o 5 bilionésimo número após a classificação deve estar localizado no arquivo_0)
Agora, só precisamos processar o arquivo file_0 (não há mais necessidade de considerar o arquivo file_1). Para o arquivo file_0, tome as mesmas medidas acima: leia parte do arquivo file_0 na memória em sequência (não excedendo o limite de memória), represente cada número em binário, compare o segundo bit mais alto do binário (o 31º bit), se o segundo bit mais alto do número for 0, grave-o no arquivo file_0_0; se o segundo bit mais alto for 1, grave-o no arquivo file_0_1.
Agora, supondo que existam 3 bilhões de números no arquivo_0_0 e 3 bilhões de números no arquivo_0_1, a mediana é: o bilionésimo número após os números no arquivo_0_0 serem classificados de pequeno para grande.
Abandone o arquivo file_0_1 e continue a dividir o arquivo file_0_0 de acordo com o próximo dígito mais alto (a 30ª posição). Suponha que os dois arquivos divididos desta vez sejam: há 500 milhões de números no arquivo_0_0_0 e 2,5 bilhões de números no arquivo_0_0_1. é o 500 milionésimo número após classificar todos os números no arquivo file_0_0_1.
De acordo com a ideia acima, até que o arquivo dividido possa ser carregado diretamente na memória, os números podem ser classificados rapidamente e diretamente para encontrar a mediana.
▐Sistema de nomes de domínio curtos (cache)
Projete um sistema de nomes de domínio curtos para converter URLs longos em URLs curtos.
Usando o atribuidor de número, o valor inicial é 0. Para cada solicitação de geração de link curto, o valor do atribuidor de número é incrementado e, em seguida, esse valor é convertido em 62 hexadecimais (a-zA-Z0-9), como o primeiro solicitação No momento da solicitação, o valor do atribuidor de número é 0, correspondendo ao hexadecimal a. Na segunda solicitação, o valor do atribuidor de número é 1, correspondendo ao hexadecimal b. o atribuidor de número é 10.000, correspondendo a A notação hexadecimal é sBc.
Concatene o nome de domínio do servidor de link curto com o valor hexadecimal 62 do atribuidor como uma string, que é a URL do link curto, por exemplo: t.cn/sBc.
Processo de redirecionamento: Após gerar um link curto, é necessário armazenar o relacionamento de mapeamento entre o link curto e o link longo, ou seja, sBc -> URL. Quando o navegador acessa o servidor do link curto, ele obtém o link original de acordo com o. Caminho do URL e, em seguida, executa um redirecionamento 302. Os relacionamentos de mapeamento podem ser armazenados usando KV, como Redis ou Memcache.
▐ Armazenamento massivo de comentários (fila de mensagens)
Suponha que exista tal cenário. Há uma notícia. O número de comentários nas notícias pode ser grande.
A página front-end é exibida diretamente ao usuário e armazenada no banco de dados de forma assíncrona por meio da fila de mensagens.
▐Número de usuários online/simultâneos (Redis)
-
Ideias de soluções para exibir o número de usuários online em um site
-
Manter tabela de usuários online -
Usando estatísticas do Redis
-
Exibir o número de usuários simultâneos do site
-
Sempre que um usuário acessa o serviço, o ID do usuário é gravado na fila ZSORT e o peso é o horário atual; -
Calcule o número de usuários da organização Zrange em um minuto com base no peso (ou seja, tempo); -
Excluir usuários Zrem que expiraram há mais de um minuto;
▐Strings populares (árvore de prefixos)
Método HashMap
Embora o número total de strings seja relativamente grande, ele não excede 300w após a desduplicação. Portanto, você pode considerar salvar todas as strings e seus tempos de ocorrência em um HashMap. O espaço ocupado é 300w*(255+4)≈777M (dos quais). 4 Representa os 4 bytes ocupados pelo inteiro). Pode-se observar que 1G de espaço de memória é totalmente suficiente.
A ideia é a seguinte
Primeiro, percorra a string. Se não estiver no mapa, armazene-a diretamente no mapa e o valor será registrado como 1, se estiver no mapa, adicione 1 ao valor correspondente O(N).
Em seguida, percorra o mapa para construir um pequeno heap superior de 10 elementos. Se o número de ocorrências da string percorrida for maior que o número de ocorrências da string no topo do heap, substitua-o e ajuste o heap para um pequeno topo. pilha.
Após a conclusão da travessia, as 10 strings no heap são as que mais aparecem. A complexidade de tempo desta etapa O(Nlog10).
método de árvore de prefixo
Quando essas strings têm um grande número dos mesmos prefixos, você pode considerar o uso de uma árvore de prefixos para contar o número de ocorrências da string. Os nós da árvore salvam o número de ocorrências da string e 0 significa nenhuma ocorrência.
A ideia é a seguinte
Ao percorrer a string, pesquise na árvore de prefixos. Se encontrado, adicione 1 ao número de strings armazenadas no nó. Caso contrário, construa um novo nó para esta string. nó folha. O número de vezes é definido como 1.
Finalmente, o pequeno heap superior ainda é usado para classificar o número de ocorrências da string.
▐Algoritmo de envelope vermelho
Método de corte linear, cortando facas N-1 em um intervalo. Quanto antes melhor
Método de média dupla, aleatório em [0~quantidade restante/número restante de pessoas*2], relativamente uniforme

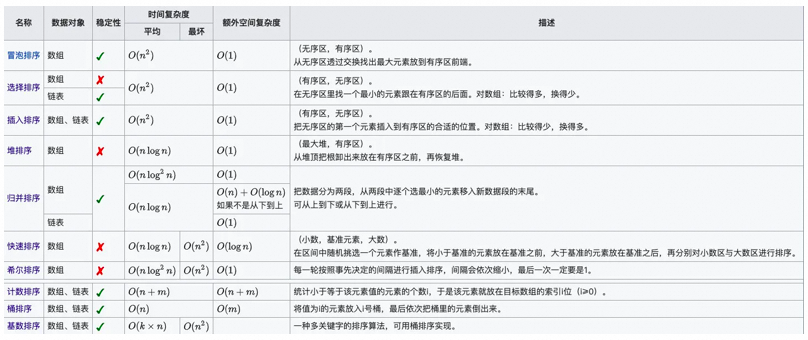
▐Classificação rápida de manuscrito
public class QuickSort {public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}/* 常规快排 */public static void quickSort1(int[] arr, int L , int R) {if (L > R) return;int M = partition(arr, L, R);quickSort1(arr, L, M - 1);quickSort1(arr, M + 1, R);}public static int partition(int[] arr, int L, int R) {if (L > R) return -1;if (L == R) return L;int lessEqual = L - 1;int index = L;while (index < R) {if (arr[index] <= arr[R])swap(arr, index, ++lessEqual);index++;}swap(arr, ++lessEqual, R);return lessEqual;}/* 荷兰国旗 */public static void quickSort2(int[] arr, int L, int R) {if (L > R) return;int[] equalArea = netherlandsFlag(arr, L, R);quickSort2(arr, L, equalArea[0] - 1);quickSort2(arr, equalArea[1] + 1, R);}public static int[] netherlandsFlag(int[] arr, int L, int R) {if (L > R) return new int[] { -1, -1 };if (L == R) return new int[] { L, R };int less = L - 1;int more = R;int index = L;while (index < more) {if (arr[index] == arr[R]) {index++;} else if (arr[index] < arr[R]) {swap(arr, index++, ++less);} else {swap(arr, index, --more);}}swap(arr, more, R);return new int[] { less + 1, more };}// for testpublic static void main(String[] args) {int testTime = 1;int maxSize = 10000000;int maxValue = 100000;boolean succeed = true;long T1=0,T2=0;for (int i = 0; i < testTime; i++) {int[] arr1 = generateRandomArray(maxSize, maxValue);int[] arr2 = copyArray(arr1);int[] arr3 = copyArray(arr1);// int[] arr1 = {9,8,7,6,5,4,3,2,1};long t1 = System.currentTimeMillis();quickSort1(arr1,0,arr1.length-1);long t2 = System.currentTimeMillis();quickSort2(arr2,0,arr2.length-1);long t3 = System.currentTimeMillis();T1 += (t2-t1);T2 += (t3-t2);if (!isEqual(arr1, arr2) || !isEqual(arr2, arr3)) {succeed = false;break;}}System.out.println(T1+" "+T2);// System.out.println(succeed ? "Nice!" : "Oops!");}private static int[] generateRandomArray(int maxSize, int maxValue) {int[] arr = new int[(int) ((maxSize + 1) * Math.random())];for (int i = 0; i < arr.length; i++) {arr[i] = (int) ((maxValue + 1) * Math.random())- (int) (maxValue * Math.random());}return arr;}private static int[] copyArray(int[] arr) {if (arr == null) return null;int[] res = new int[arr.length];for (int i = 0; i < arr.length; i++) {res[i] = arr[i];}return res;}private static boolean isEqual(int[] arr1, int[] arr2) {if ((arr1 == null && arr2 != null) || (arr1 != null && arr2 == null))return false;if (arr1 == null && arr2 == null)return true;if (arr1.length != arr2.length)return false;for (int i = 0; i < arr1.length; i++)if (arr1[i] != arr2[i])return false;return true;}private static void printArray(int[] arr) {if (arr == null)return;for (int i = 0; i < arr.length; i++)System.out.print(arr[i] + " ");System.out.println();}}
▐ Mesclagem de manuscrito
public static void merge(int[] arr, int L, int M, int R) {int[] help = new int[R - L + 1];int i = 0;int p1 = L;int p2 = M + 1;while (p1 <= M && p2 <= R)help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];while (p1 <= M)help[i++] = arr[p1++];while (p2 <= R)help[i++] = arr[p2++];for (i = 0; i < help.length; i++)arr[L + i] = help[i];}public static void mergeSort(int[] arr, int L, int R) {if (L == R)return;int mid = L + ((R - L) >> 1);process(arr, L, mid);process(arr, mid + 1, R);merge(arr, L, mid, R);}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};mergeSort(arr, 0, arr.length - 1);printArray(arr);}
▐ Pilhas manuscritas
// 堆排序额外空间复杂度O(1)public static void heapSort(int[] arr) {if (arr == null || arr.length < 2)return;for (int i = arr.length - 1; i >= 0; i--)heapify(arr, i, arr.length);int heapSize = arr.length;swap(arr, 0, --heapSize);// O(N*logN)while (heapSize > 0) { // O(N)heapify(arr, 0, heapSize); // O(logN)swap(arr, 0, --heapSize); // O(1)}}// arr[index]刚来的数,往上public static void heapInsert(int[] arr, int index) {while (arr[index] > arr[(index - 1) / 2]) {swap(arr, index, (index - 1) / 2);index = (index - 1) / 2;}}// arr[index]位置的数,能否往下移动public static void heapify(int[] arr, int index, int heapSize) {int left = index * 2 + 1; // 左孩子的下标while (left < heapSize) { // 下方还有孩子的时候// 两个孩子中,谁的值大,把下标给largest// 1)只有左孩子,left -> largest// 2) 同时有左孩子和右孩子,右孩子的值<= 左孩子的值,left -> largest// 3) 同时有左孩子和右孩子并且右孩子的值> 左孩子的值, right -> largestint largest = left+1 < heapSize && arr[left+1]> arr[left] ? left+1 : left;// 父和较大的孩子之间,谁的值大,把下标给largestlargest = arr[largest] > arr[index] ? largest : index;if (largest == index)break;swap(arr, largest, index);index = largest;left = index * 2 + 1;}}public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};heapSort(arr1);printArray(arr1);}
▐Singleton manuscrito
public class Singleton {private volatile static Singleton singleton;private Singleton() {}public static Singleton getSingleton() {if (singleton == null) {synchronized (Singleton.class) {if (singleton == null) {singleton = new Singleton();}}}return singleton;}}
▐ LRUcache manuscrito
// 基于linkedHashMappublic class LRUCache {private LinkedHashMap<Integer,Integer> cache;private int capacity; //容量大小public LRUCache(int capacity) {cache = new LinkedHashMap<>(capacity);this.capacity = capacity;}public int get(int key) {//缓存中不存在此key,直接返回if(!cache.containsKey(key)) {return -1;}int res = cache.get(key);cache.remove(key); //先从链表中删除cache.put(key,res); //再把该节点放到链表末尾处return res;}public void put(int key,int value) {if(cache.containsKey(key)) {cache.remove(key); //已经存在,在当前链表移除}if(capacity == cache.size()) {//cache已满,删除链表头位置Set<Integer> keySet = cache.keySet();Iterator<Integer> iterator = keySet.iterator();cache.remove(iterator.next());}cache.put(key,value); //插入到链表末尾}}
//手写双向链表class LRUCache {class DNode {DNode prev;DNode next;int val;int key;}Map<Integer, DNode> map = new HashMap<>();DNode head, tail;int cap;public LRUCache(int capacity) {head = new DNode();tail = new DNode();head.next = tail;tail.prev = head;cap = capacity;}public int get(int key) {if (map.containsKey(key)) {DNode node = map.get(key);removeNode(node);addToHead(node);return node.val;} else {return -1;}}public void put(int key, int value) {if (map.containsKey(key)) {DNode node = map.get(key);node.val = value;removeNode(node);addToHead(node);} else {DNode newNode = new DNode();newNode.val = value;newNode.key = key;addToHead(newNode);map.put(key, newNode);if (map.size() > cap) {map.remove(tail.prev.key);removeNode(tail.prev);}}}public void removeNode(DNode node) {DNode prevNode = node.prev;DNode nextNode = node.next;prevNode.next = nextNode;nextNode.prev = prevNode;}public void addToHead(DNode node) {DNode firstNode = head.next;head.next = node;node.prev = head;node.next = firstNode;firstNode.prev = node;}}
▐ Conjunto de tópicos de escrita manual
package com.concurrent.pool;import java.util.HashSet;import java.util.Set;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.BlockingQueue;public class MySelfThreadPool {//默认线程池中的线程的数量private static final int WORK_NUM = 5;//默认处理任务的数量private static final int TASK_NUM = 100;private int workNum;//线程数量private int taskNum;//任务数量private final Set<WorkThread> workThreads;//保存线程的集合private final BlockingQueue<Runnable> taskQueue;//阻塞有序队列存放任务public MySelfThreadPool() {this(WORK_NUM, TASK_NUM);}public MySelfThreadPool(int workNum, int taskNum) {if (workNum <= 0) workNum = WORK_NUM;if (taskNum <= 0) taskNum = TASK_NUM;taskQueue = new ArrayBlockingQueue<>(taskNum);this.workNum = workNum;this.taskNum = taskNum;workThreads = new HashSet<>();//启动一定数量的线程数,从队列中获取任务处理for (int i=0;i<workNum;i++) {WorkThread workThread = new WorkThread("thead_"+i);workThread.start();workThreads.add(workThread);}}public void execute(Runnable task) {try {taskQueue.put(task);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}public void destroy() {System.out.println("ready close thread pool...");if (workThreads == null || workThreads.isEmpty()) return ;for (WorkThread workThread : workThreads) {workThread.stopWork();workThread = null;//help gc}workThreads.clear();}private class WorkThread extends Thread{public WorkThread(String name) {super();setName(name);}@Overridepublic void run() {while (!interrupted()) {try {Runnable runnable = taskQueue.take();//获取任务if (runnable !=null) {System.out.println(getName()+" readyexecute:"+runnable.toString());runnable.run();//执行任务}runnable = null;//help gc} catch (Exception e) {interrupt();e.printStackTrace();}}}public void stopWork() {interrupt();}}}package com.concurrent.pool;public class TestMySelfThreadPool {private static final int TASK_NUM = 50;//任务的个数public static void main(String[] args) {MySelfThreadPool myPool = new MySelfThreadPool(3,50);for (int i=0;i<TASK_NUM;i++) {myPool.execute(new MyTask("task_"+i));}}static class MyTask implements Runnable{private String name;public MyTask(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}System.out.println("task :"+name+" end...");}@Overridepublic String toString() {// TODO Auto-generated method stubreturn "name = "+name;}}}
▐Padrão de produtor consumidor manuscrito
public class Storage {private static int MAX_VALUE = 100;private List<Object> list = new ArrayList<>();public void produce(int num) {synchronized (list) {while (list.size() + num > MAX_VALUE) {System.out.println("暂时不能执行生产任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.add(new Object());}System.out.println("已生产产品数"+num+" 仓库容量"+list.size());list.notifyAll();}}public void consume(int num) {synchronized (list) {while (list.size() < num) {System.out.println("暂时不能执行消费任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.remove(0);}System.out.println("已消费产品数"+num+" 仓库容量" + list.size());list.notifyAll();}}}public class Producer extends Thread {private int num;private Storage storage;public Producer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.produce(this.num);}}public class Customer extends Thread {private int num;private Storage storage;public Customer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.consume(this.num);}}public class Test {public static void main(String[] args) {Storage storage = new Storage();Producer p1 = new Producer(storage);Producer p2 = new Producer(storage);Producer p3 = new Producer(storage);Producer p4 = new Producer(storage);Customer c1 = new Customer(storage);Customer c2 = new Customer(storage);Customer c3 = new Customer(storage);p1.setNum(10);p2.setNum(20);p3.setNum(80);c1.setNum(50);c2.setNum(20);c3.setNum(20);c1.start();c2.start();c3.start();p1.start();p2.start();p3.start();}}
▐Fila de bloqueio de manuscrito
public class blockQueue {private List<Integer> container = new ArrayList<>();private volatile int size;private volatile int capacity;private Lock lock = new ReentrantLock();private final Condition isNull = lock.newCondition();private final Condition isFull = lock.newCondition();blockQueue(int capacity) {this.capacity = capacity;}public void add(int data) {try {lock.lock();try {while (size >= capacity) {System.out.println("阻塞队列满了");isFull.await();}} catch (Exception e) {isFull.signal();e.printStackTrace();}++size;container.add(data);isNull.signal();} finally {lock.unlock();}}public int take() {try {lock.lock();try {while (size == 0) {System.out.println("阻塞队列空了");isNull.await();}} catch (Exception e) {isNull.signal();e.printStackTrace();}--size;int res = container.get(0);container.remove(0);isFull.signal();return res;} finally {lock.unlock();}}}public static void main(String[] args) {AxinBlockQueue queue = new AxinBlockQueue(5);Thread t1 = new Thread(() -> {for (int i = 0; i < 100; i++) {queue.add(i);System.out.println("塞入" + i);try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}}});Thread t2 = new Thread(() -> {for (; ; ) {System.out.println("消费"+queue.take());try {Thread.sleep(800);} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();t2.start();}
▐ Impressão alternativa multithread manuscrita ABC
package com.demo.test;import java.util.concurrent.locks.Condition;import java.util.concurrent.locks.ReentrantLock;public class syncPrinter implements Runnable{// 打印次数private static final int PRINT_COUNT = 10;private final ReentrantLock reentrantLock;private final Condition thisCondtion;private final Condition nextCondtion;private final char printChar;public syncPrinter(ReentrantLock reentrantLock, Condition thisCondtion, Condition nextCondition, char printChar) {this.reentrantLock = reentrantLock;this.nextCondtion = nextCondition;this.thisCondtion = thisCondtion;this.printChar = printChar;}@Overridepublic void run() {// 获取打印锁 进入临界区reentrantLock.lock();try {// 连续打印PRINT_COUNT次for (int i = 0; i < PRINT_COUNT; i++) {//打印字符System.out.print(printChar);// 使用nextCondition唤醒下一个线程// 因为只有一个线程在等待,所以signal或者signalAll都可以nextCondtion.signal();// 不是最后一次则通过thisCondtion等待被唤醒// 必须要加判断,不然虽然能够打印10次,但10次后就会直接死锁if (i < PRINT_COUNT - 1) {try {// 本线程让出锁并等待唤醒thisCondtion.await();} catch (InterruptedException e) {e.printStackTrace();}}}} finally {reentrantLock.unlock();}}public static void main(String[] args) throws InterruptedException {ReentrantLock lock = new ReentrantLock();Condition conditionA = lock.newCondition();Condition conditionB = lock.newCondition();Condition conditionC = lock.newCondition();Thread printA = new Thread(new syncPrinter(lock, conditionA, conditionB,'A'));Thread printB = new Thread(new syncPrinter(lock, conditionB, conditionC,'B'));Thread printC = new Thread(new syncPrinter(lock, conditionC, conditionA,'C'));printA.start();Thread.sleep(100);printB.start();Thread.sleep(100);printC.start();}}
▐Imprima FooBar alternadamente
//手太阴肺经 BLOCKING Queuepublic class FooBar {private int n;private BlockingQueue<Integer> bar = new LinkedBlockingQueue<>(1);private BlockingQueue<Integer> foo = new LinkedBlockingQueue<>(1);public FooBar(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.put(i);printFoo.run();bar.put(i);}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.take();printBar.run();foo.take();}}}//手阳明大肠经CyclicBarrier 控制先后class FooBar6 {private int n;public FooBar6(int n) {this.n = n;}CyclicBarrier cb = new CyclicBarrier(2);volatile boolean fin = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {while(!fin);printFoo.run();fin = false;try {cb.await();} catch (BrokenBarrierException e) {}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {try {cb.await();} catch (BrokenBarrierException e) {}printBar.run();fin = true;}}}//手少阴心经 自旋 + 让出CPUclass FooBar5 {private int n;public FooBar5(int n) {this.n = n;}volatile boolean permitFoo = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; ) {if(permitFoo) {printFoo.run();i++;permitFoo = false;}else{Thread.yield();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; ) {if(!permitFoo) {printBar.run();i++;permitFoo = true;}else{Thread.yield();}}}}//手少阳三焦经 可重入锁 + Conditionclass FooBar4 {private int n;public FooBar4(int n) {this.n = n;}Lock lock = new ReentrantLock(true);private final Condition foo = lock.newCondition();volatile boolean flag = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {lock.lock();try {while(!flag) {foo.await();}printFoo.run();flag = false;foo.signal();}finally {lock.unlock();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n;i++) {lock.lock();try {while(flag) {foo.await();}printBar.run();flag = true;foo.signal();}finally {lock.unlock();}}}}//手厥阴心包经 synchronized + 标志位 + 唤醒class FooBar3 {private int n;// 标志位,控制执行顺序,true执行printFoo,false执行printBarprivate volatile boolean type = true;private final Object foo= new Object(); // 锁标志public FooBar3(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(!type){foo.wait();}printFoo.run();type = false;foo.notifyAll();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(type){foo.wait();}printBar.run();type = true;foo.notifyAll();}}}}//手太阳小肠经 信号量 适合控制顺序class FooBar2 {private int n;private Semaphore foo = new Semaphore(1);private Semaphore bar = new Semaphore(0);public FooBar2(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.acquire();printFoo.run();bar.release();}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.acquire();printBar.run();foo.release();}}}
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。