Artigo Diretório
1. Introdução ao NoSQL
1.1 O que é NoSQL
NoSQL: não apenas SQL, banco de dados não relacional
NoSQL é um termo geral
- Refere-se a bancos de dados que não seguem o modelo RDBMS tradicional
- Os dados são não relacionais e não usam SQL como a linguagem de consulta principal
- Resolva problemas de escalabilidade e disponibilidade do banco de dados
- Não aborda questões de atomicidade ou consistência

1.2 Por que usar NoSQL
Com o desenvolvimento da Internet, os bancos de dados relacionais tradicionais têm gargalos
- Leitura e escrita simultâneas altas
- Alta capacidade de armazenamento
- Alta disponibilidade
- Alta escalabilidade
- baixo custo
Comparação de NoSQL e bancos de dados relacionais
Existem principalmente as seguintes diferenças
| Comparado | NoSQL | Banco de Dados Relacional |
|---|---|---|
| Banco de dados comum | HBase 、 MongoDB 、 Redis | Oracle 、 DB2 、 MySQL |
| Formato de armazenamento | Documentos, pares de valores-chave, estrutura gráfica | Formato da tabela, linhas e colunas |
| Especificação de armazenamento | Incentive a redundância | Normativo, evite duplicação |
| Expansão de armazenamento | Expansão, distribuído | Expansão vertical (expansão horizontal limitada) |
| modo de inquérito | Linguagem de consulta estruturada SQL | Consulta não estruturada |
| romances | Não suporta consistência de transação | Assuntos de suporte |
| desempenho | Alto desempenho de leitura e gravação | Baixo desempenho de leitura e gravação |
| custo | Simples e fácil de implantar, código aberto, baixo custo | alto custo |
1.3 Recursos do NoSQL
-
Consistência final
-
O aplicativo aumentou as responsabilidades de manter a consistência e lidar com as transações
-
Armazenamento de dados redundante
-
NoSQL! = Big data
- Os produtos NoSQL são para ajudar a resolver problemas de armazenamento de big data
- Big data inclui mais do que apenas problemas de armazenamento de dados
- Hadoop
- Kafka
- Spark, etc
1.4 Conceitos básicos de NoSQL
- Três pilares
- CAP, BASE, consistência final
- Indexação (índice), consulta (consulta)
- MapReduce
- Sharding
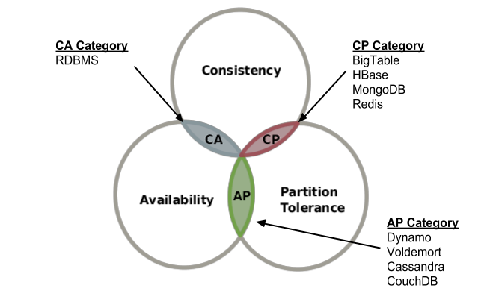
- Teoria CAP
- O banco de dados suporta até 2 de 3
- Consistência
- Disponibilidade
- Tolerância de partição (tolerância a falhas de partição)
- NoSQL não garante "ACID"
- Fornece "consistência eventual"
- BASE
- Basicamente disponível (basicamente disponível)
- Certifique-se de que o núcleo está disponível
- Soft-state
- O estado pode ficar fora de sincronia por um tempo
- Consistência eventual (consistência eventual)
- Após um certo período de tempo, os dados podem finalmente atingir um estado consistente
- A ideia central é que mesmo que a consistência forte não possa ser alcançada, o aplicativo pode escolher uma maneira adequada de atingir a consistência final
- Consistência final
- O resultado final é consistente, nem sempre consistente
- Dados como saldo da conta e estoque devem ser fortemente consistentes
- Informações como catálogo não exigem consistência forte
- Consistência causal (consistência causal)
- Consistência de ler suas gravações
- Consistência da sessão
Índice e consulta
- Indexação (Indexação)
A maior parte do NoSQL é indexada por chave.
Parte do NoSQL permite que o índice secundário
HBase use HDFS, anexar somente
gravação em lote Registrado
para recriar e classificar arquivos - Query (query)
não tem uma linguagem de consulta especial, geralmente usa linguagem de script para consulta,
alguns começam a suportar consulta SQL,
alguns podem usar consulta de código MapReduce
MapReduce 、 Fragmentação
- MapReduce
não é o MapReduce do Hadoop, e o conceito está relacionado
ao processamento de dados e consulta - Sharding (fragmentação)
um modo de particionamento que
pode replicar fragmentos, o que
é bom para recuperação de desastres
1.5 Classificação NoSQL
Principalmente dividido nas seguintes quatro categorias
| classificação | Por exemplo | Cenários de aplicação típicos |
|---|---|---|
| Banco de dados de armazenamento de valor-chave (valor-chave) | Redis, MemcacheDB, Voldemort | Cache de conteúdo, etc. |
| Banco de dados de armazenamento de coluna (WIDE COLUMN STORE) | Cassandra, HBase | Responda aos dados massivos de armazenamento distribuído |
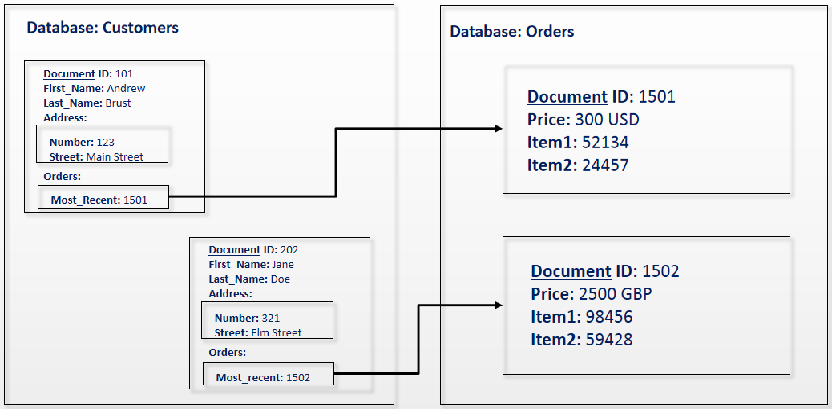
| Banco de dados de documentos (DOCUMENT STORE) | CouchDB, MongoDB | Aplicativo da Web (pode ser considerado uma versão atualizada do banco de dados de valores-chave) |
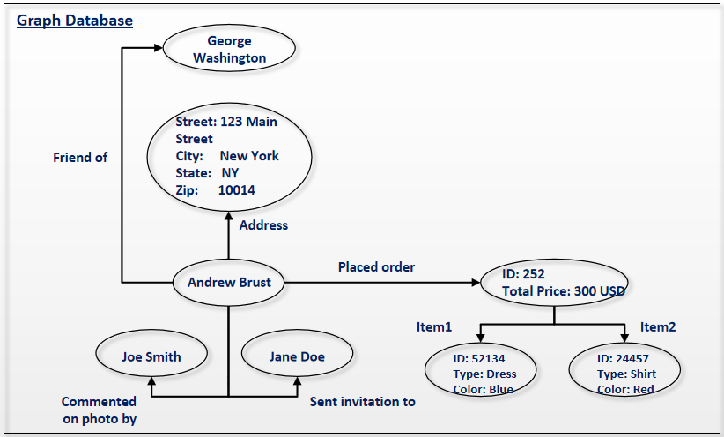
| GRAPH DB | Neo4J, InfoGrid, Infinite Graph | Redes sociais, sistemas de recomendação, etc., com foco na construção de um gráfico de relacionamento |
Banco de dados de armazenamento de valor-chave (valor-chave)
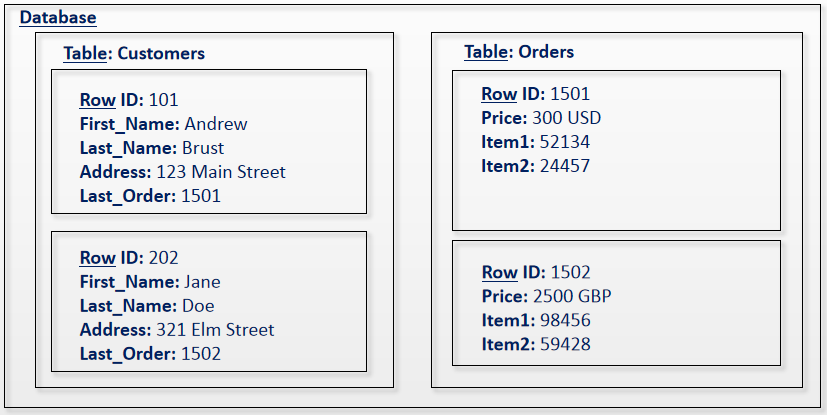
Banco de dados de armazenamento de colunas (amplo armazenamento de colunas)

Loja de Documentos
Bancos de dados gráficos
1.6 A relação entre NoSQL, BI e big data
- BI (Business Intelligence): Business Intelligence
É um conjunto completo de soluções.
As aplicações de BI envolvem modelos que dependem do modelo. O
BI suporta principalmente SQL padrão, e o suporte NoSQL é mais fraco do que os bancos de dados relacionais. - NoSQL tem uma alta correlação com big data.
Geralmente, os bancos de dados de armazenamento em coluna são usados em cenários de big data,
como HBase e Hadoop.
2. Introdução ao HBase
2.1 Visão geral do HBase
- HBase é um banco de dados NoSQL líder. É
um banco de dados de armazenamento orientado a colunas. É
um mapa de hash distribuído com
base no documento Google Big Table. Ele
usa HDFS como armazenamento e usa sua confiabilidade. - Recursos do HBase:
Velocidade rápida de acesso a dados, tempo de resposta de cerca de 2 a 20 milissegundos
Suporte de leitura e gravação aleatória
, escalabilidade de cada nó 20k ~ 100k + ops / s , pode ser expandido para mais de 20.000 nós
2.2 Histórico de desenvolvimento de HBase
| Tempo | evento |
|---|---|
| ano 2006 | O Google publicou um artigo sobre Big Table |
| 2007 | A primeira versão do HBase e Hadoop 0.15.0 são lançadas juntas |
| Ano 2008 | HBase torna-se um subprojeto do Hadoop |
| ano 2010 | HBase torna-se o principal projeto Apache |
| ano 2011 | Cloudera lança CDH3 baseado em HBase0.90.1 |
| 2012 | HBase lançou a versão 0.94 |
| 2013-2014 | HBase lançou versão 0.96 / versão 0.98 |
| 2015-2016 | HBase lançou a versão 1.0, versão 1.1 e versão 1.2.4 |
| 2017 | HBase lançou a versão 1.3 |
| 2018 | HBase lançou a versão 1.4 e a versão 2.0 |
2.3 Grupos de usuários HBase

2.4 Cenários de aplicação HBase
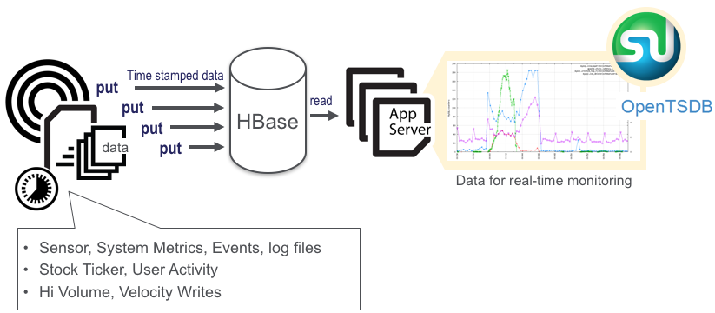
- Cenário de aplicação-1
Dados incrementais de série temporal
Gravação de alta capacidade e alta velocidade
- Cenário de aplicação-2
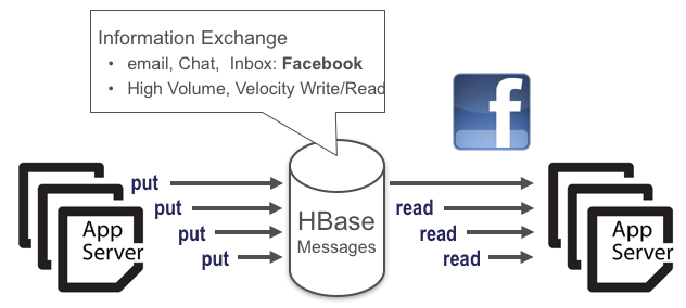
Troca de informações - mensagens
Leitura e escrita de alta capacidade e alta velocidade
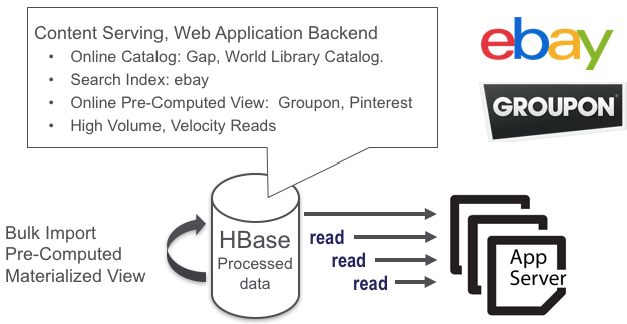
- Cenário de aplicação-3
Aplicativo de back-end do serviço de conteúdo da web
Leitura e escrita de alta capacidade e alta velocidade
2.5 Ecossistema Apache HBase
HBase Ecosystem Technology
Lily - CRM
OpenTSDB baseado em HBase - Gerenciamento de dados de séries temporais orientado a HBase
Kylin - OLAP
Phoenix
em HBase - operação SQL Ferramenta HBase Splice Machine - OLTP baseado em HBase
Apache Tephra - Suporte a transações HBase
TiDB - SQL DB
Apache Gerenciamento de transações do Omid-Optimize
Servidor de linha do tempo do aplicativo Yarn v.2 Migrar para o
armazenamento de metadados HBase Hive pode ser migrado para o HBase
Ambari Metrics Server usará o HBase para armazenamento de dados
Arquitetura 2.6HBase
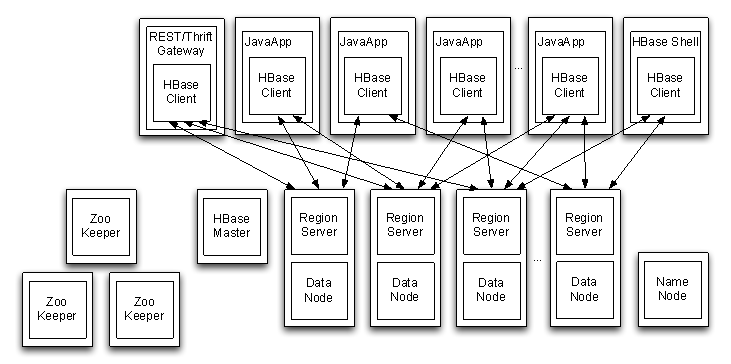
1. Arquitetura física
HBase adota arquitetura Master / Slave
-
A função
do HMaster é o nó mestre do cluster HBase, que pode ser configurado com vários nós para obter
gerenciamento e distribuição de HA . A região
é responsável pelo balanceamento de carga dos RegionServers.
Encontra os RegionServers com falha e redistribui as regiões neles. -
RegionServer
RegionServer é responsável pelo gerenciamento e manutenção da região.
Um RegionServer contém um WAL, um BlockCache (cache de leitura) e várias regiões.
Uma região contém várias áreas de armazenamento, e cada área de armazenamento corresponde a um grupo de colunas.
Uma área de armazenamento é composta por vários StoreFiles e MemStores.
Um StoreFile corresponde a Um HFile e uma família de colunas
HFile e WAL são armazenados como arquivos de sequência no HDFS
Client interage com RegionServer
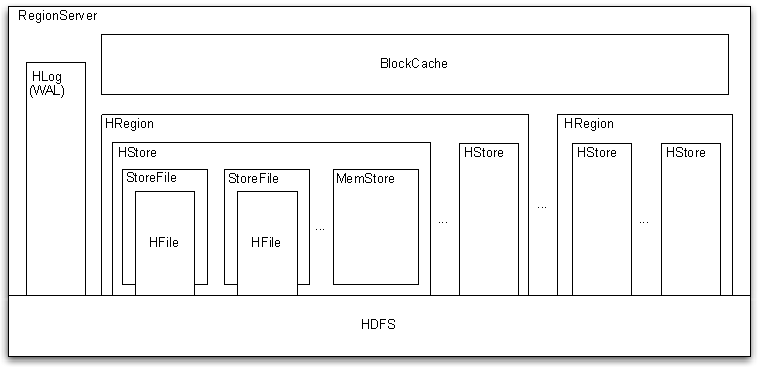
- Região 和 Tabela
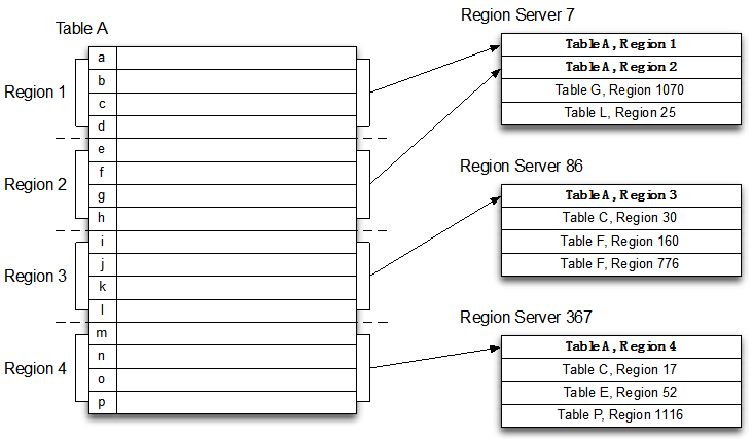
2. Linha de Arquitetura Lógica
- Rowkey (chave de linha) é única e classificada
- O esquema pode definir quando inserir registros
- Cada linha pode definir sua própria coluna, mesmo se outras linhas não forem usadas
- As colunas relacionadas são definidas como famílias de colunas
- Manter várias versões de linha com carimbos de data / hora exclusivos
- O tipo de valor pode ser diferente em diferentes versões
- Os dados do HBase são todos armazenados em bytes
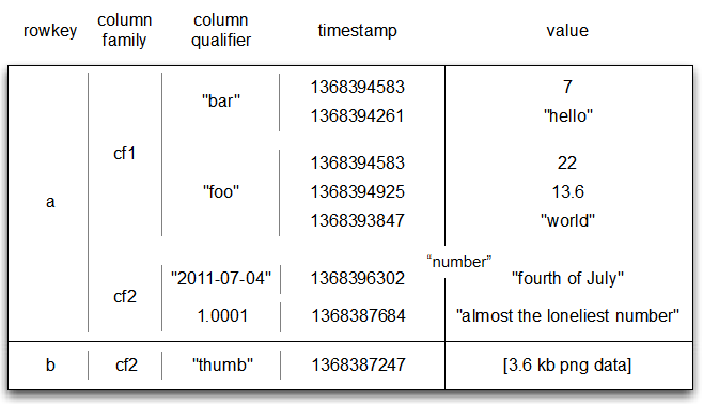
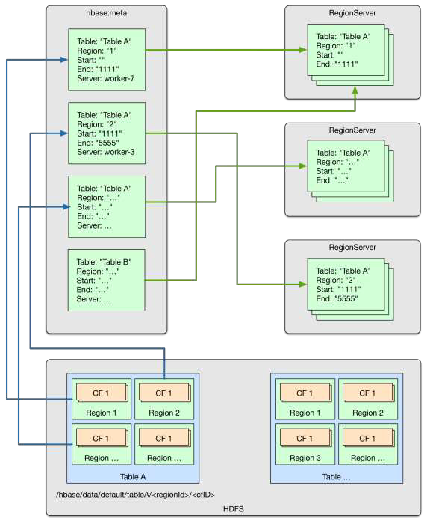
2.7 Gerenciamento de dados HBase
- Data Management Directory
- Tabela de catálogo do sistema hbase: meta
- Armazenar metadados, etc.
- Arquivos no diretório HDFS
- Instância de região em servidores
- Tabela de catálogo do sistema hbase: meta
- Dados HBase em HDFS
- Pode ser reparado por meio do arquivo HDFS
- Caminho de reparo
- RegionServer-> Table-> Region-> RowKey-> 列 族
Recursos da arquitetura 2.8HBase
- Consistência forte
- Expansão automática
- Dividir automaticamente quando a região se torna grande
- Use HDFS para expandir dados e gerenciar espaço
- Recuperação de gravação
- 使用 WAL (registro de gravação antecipada)
- Integração com Hadoop