
Compartilhador: Zeng Qingguo |Escola: Southern University of Science and Technology
breve introdução
A desaceleração da Lei de Moore promoveu o desenvolvimento de paradigmas de computação não tradicionais, como máquinas de Ising customizadas projetadas especificamente para resolver problemas de otimização combinatória. Esta sessão apresentará novas aplicações de máquinas Ising baseadas em P-bit para treinar redes neurais generativas profundas, usando máquinas Ising esparsas, assíncronas e altamente paralelas para treinar redes Boltzmann profundas em um ambiente misto de computação probabilística-clássica.
Artigos relacionados
标题: Treinamento de redes Boltzmann profundas com máquinas de ising esparsas
作宇:**Shaila Niazi, Navid Anjum Aadit, Masoud Mohseni, Shuvro Chowdhury, Yao Qin, Kerem Y. Camsari
01
Objetivo do artigo
Objetivo: Demonstrar como treinar com eficiência versões esparsas de redes profundas de Boltzmann usando sistemas de hardware especializados (por exemplo, P-bit) que fornecem aceleração de ordens de magnitude em relação a implementações de software comumente usadas em tarefas computacionais de amostragem probabilística difícil;
Objetivo de longo prazo: ajudar a facilitar o desenvolvimento de hardware probabilístico inspirado na física para reduzir o custo crescente do aprendizado profundo tradicional baseado em gráficos e unidades de processamento de tensores (GPU/TPU);
Dificuldades na implementação de hardware:
1. Os bits p conectados devem ser atualizados serialmente e as atualizações são proibidas em sistemas densos
2. Certifique-se de que o bit p receba todas as informações mais recentes de seus nós vizinhos antes de atualizar, caso contrário, a rede não receberá; Amostragem de uma verdadeira distribuição de Boltzmann.
02
conteúdo principal
O conteúdo do treinamento de redes profundas de Boltzmann usando máquinas de Ising esparsas é dividido principalmente em quatro partes:
1. Estrutura da rede
2. Função objetivo
3. Otimização de parâmetros
4. Inferência (classificação e geração de imagens)
1. Estrutura de rede
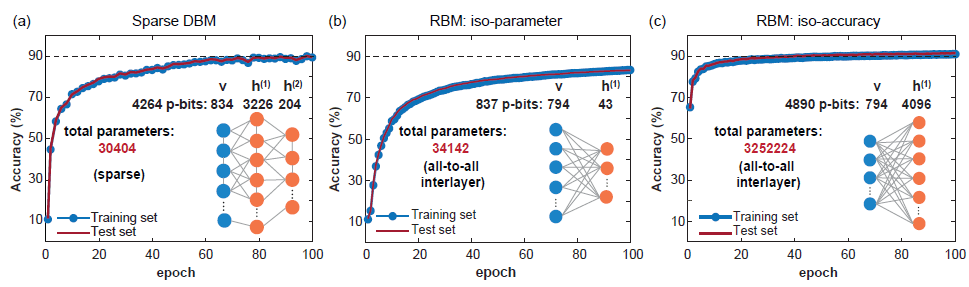
As topologias Pegasus e Zepyhr desenvolvidas pela D-Wave são usadas para treinar redes profundas esparsas com reconhecimento de hardware. Esta operação é inspirada em redes estendidas, mas com conexões restritas, como o cérebro humano e microprocessadores avançados. Apesar do uso onipresente da conectividade total em modelos de aprendizado de máquina, tanto os microprocessadores avançados quanto os cérebros humanos com bilhões de redes de transistores exibem um grande grau de dispersão. Na verdade, a maioria das implementações de hardware de RBM enfrentam problemas de escala devido à alta responsabilidade computacional exigida por cada nó, enquanto conexões esparsas em redes neurais de hardware geralmente apresentam vantagens. Além disso, a estrutura de rede esparsa resolve bem as dificuldades de implementação de hardware mencionadas acima.
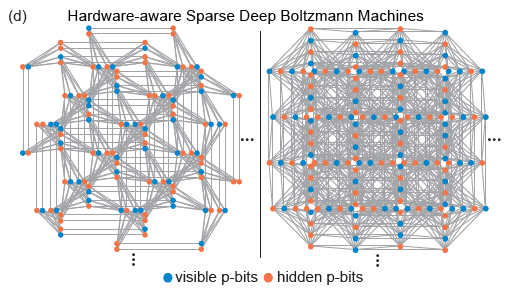
(Fonte da imagem: arXiv:2303.10728)
2. Função objetivo
Maximizar a função de verossimilhança equivale a minimizar a divergência KL entre a distribuição dos dados e a distribuição do modelo:
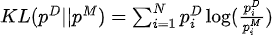
Entre eles, 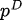 está a distribuição de dados e
está a distribuição de dados e 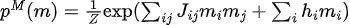 a distribuição do modelo.
a distribuição do modelo.
O gradiente de divergência KL em relação aos parâmetros do modelo ( 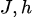 ) é:
) é:
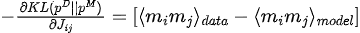
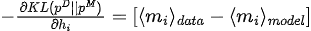
3. Otimização de parâmetros

(Fonte da imagem: arXiv:2303.10728)
Treine os parâmetros da rede de acordo com o Algoritmo 1, incluindo
-
Inicialização dos parâmetros de inicialização (
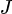 , );
, );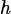
-
Use os dados de treinamento para atribuir valores aos p-bits da camada de entrada e, em seguida, execute a amostragem MC para obter amostras amostrais da distribuição de dados;
-
Realizar amostragem MC diretamente para obter amostras amostrais da distribuição do modelo;
-
O gradiente (chamado divergência contrastiva persistente) é estimado usando amostras amostradas em dois estágios, e os parâmetros são atualizados usando o método gradiente descendente.
Entre eles, a amostragem MC usa evolução iterativa de p-bits:

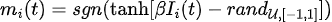
No processo de treinamento de redes esparsas de Boltzmann, há dois pontos a serem observados:
-
1) Índice de p-bits randomizado
Ao treinar um modelo de rede de Boltzmann em uma determinada rede esparsa, a distância do gráfico entre nós visíveis, ocultos e de rótulo é um conceito muito importante. Normalmente, se a camada estiver totalmente conectada, a distância do gráfico entre quaisquer dois nós é constante, mas este não é o caso para gráficos esparsos, então as posições dos bits p visíveis, ocultos e de rótulo parecem extraordinariamente importantes. Se os bits p visíveis, ocultos e de rótulo estiverem agrupados e muito próximos, a precisão da classificação será bastante afetada. Isto ocorre provavelmente porque se a distância gráfica entre os bits do rótulo e os bits visíveis for muito grande, a correlação entre eles se tornará mais fraca. Randomizar o índice de p-bits pode aliviar esse problema. -
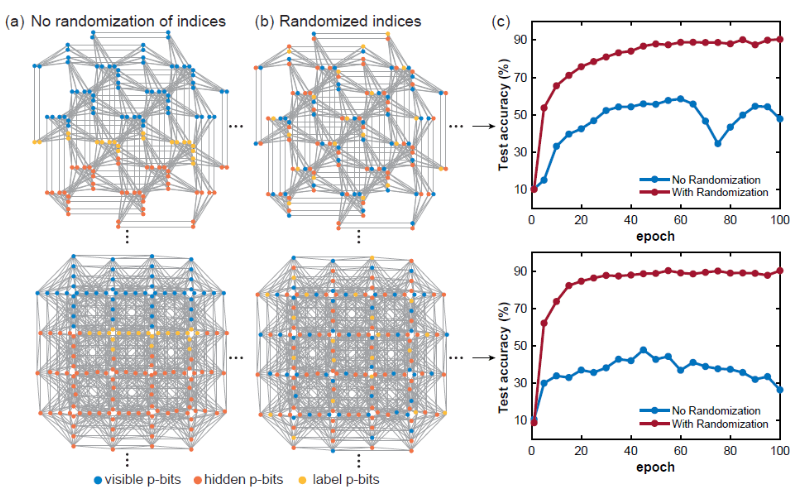
-
(Fonte da imagem: arXiv:2303.10728)
**2)大规模并行**
在稀疏深度玻尔兹曼网络上,我们使用启发式图着色算法DSatur对图着色,对于未连接p-bits进行并行更新。
-
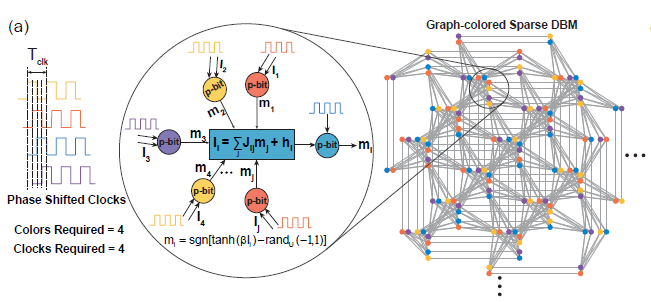
-
(Fonte da imagem: arXiv:2303.10728)
4. Inferência
Classificação: use dados de teste para fixar p-bits visíveis, em seguida, execute a amostragem MC e, em seguida, obtenha as expectativas para os pbits de rótulo obtidos e tome o rótulo com o maior valor esperado como o rótulo previsto
-
-
(Fonte da imagem: arXiv:2303.10728)
Geração de imagem: Fixe os p-bits do rótulo na codificação correspondente ao rótulo que deseja gerar, em seguida, execute a amostragem MC e recoze a rede durante o processo de amostragem (aumentando gradualmente de 0 a 5 em etapas de 0,125), e o obtido as amostras correspondem aos p-bits visíveis são as imagens geradas.
-

-
(Fonte da imagem: arXiv:2303.10728)
03
Resumir
O artigo usa uma máquina Ising esparsa com uma arquitetura massivamente paralela, que atinge velocidades de amostragem muito mais rápidas do que as CPUs tradicionais. O artigo estuda sistematicamente o tempo de mistura de topologias de rede com reconhecimento de hardware e mostra que a precisão da classificação do modelo não é limitada pela operabilidade computacional do algoritmo, mas pelo FPGA de tamanho moderado que pôde ser utilizado neste trabalho. Outras melhorias podem envolver o uso de arquiteturas de rede mais profundas, mais amplas e possivelmente "mais difíceis de misturar", que aproveitem ao máximo os amostradores probabilísticos ultrarrápidos. Além disso, combinar a tecnologia de treinamento camada por camada do DBM tradicional com o método do artigo pode trazer outras melhorias possíveis. A implementação de máquinas de Ising esparsas usando dispositivos em nanoescala, como junções de túneis magnéticos aleatórios, pode mudar o status atual das aplicações práticas das redes profundas de Boltzmann.
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Google confirmou demissões, envolvendo a "maldição de 35 anos" dos programadores chineses nas equipes Flutter, Dart e . Python Arc Browser para Windows 1.0 em 3 meses oficialmente GA A participação de mercado do Windows 10 atinge 70%, Windows 11 GitHub continua a diminuir a ferramenta de desenvolvimento nativa de IA GitHub Copilot Workspace JAVA. é a única consulta de tipo forte que pode lidar com OLTP + OLAP. Este é o melhor ORM. Nos encontramos tarde demais.