Fonte do código do artigo: "aprendizado profundo em keras", um livro muito bom. Se você é bom em inglês, é recomendável ler o livro diretamente. Se você tiver pouco tempo, pode ler esta série de artigos.
Neste capítulo, estudaremos redes neurais convolucionais, um tipo de modelo de aprendizado profundo comumente usado em visão computacional, e você aprenderá a aplicá-las a problemas de classificação.
Apresentaremos primeiro algumas das teorias por trás das redes neurais convolucionais, especificamente:
- O que são convolução e pooling máximo?
- O que é uma rede convolucional?
- O que a rede convolucional aprendeu?
A seguir generalizaremos o problema de classificação de imagens usando um pequeno conjunto de dados:
- Treine sua pequena rede convolucional do zero
- Use o aumento de dados para evitar overfitting
- Use redes convolucionais pré-treinadas para extração de recursos
- Ajuste os parâmetros da rede convolucional pré-treinada
Por fim, descreveremos várias técnicas de visualização para aprender como classificar.
A seguir está nossa primeira seção, uma introdução às redes neurais convolucionais
Mergulhamos na teoria das redes neurais convolucionais e exploramos por que elas são tão bem-sucedidas em tarefas de visão computacional. Primeiro, vejamos um exemplo simples de rede convolucional em ação. Usaremos uma rede convolucional para classificar os dígitos MNIST. Anteriormente, atingíamos uma taxa de reconhecimento de 97,8% usando redes totalmente conectadas. Embora nossa rede convolucional seja muito básica, sua taxa de precisão ainda é melhor do que a rede original totalmente conectada.
As próximas 6 linhas de código mostrarão como é a rede convolucional mais básica, que na verdade é uma pilha de algumas camadas de convolução bidimensional e de pooling máximo bidimensional. Veremos o que eles fazem a seguir: A forma do tensor tomada por uma convolução: (comprimento, largura, número de canais) não inclui a dimensão do lote. Em nosso exemplo, estaremos processando dados de entrada no formato (28,28,1), que é o formato dos dados no MNIST.
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
A seguir, vejamos a estrutura da rede convolucional:
>>> model.summary()
________________________________________________________________
Layer (type) Output Shape Param #
================================================================
conv2d_1 (Conv2D) (None, 26, 26, 32) 320
________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 13, 13, 32) 0
________________________________________________________________
conv2d_2 (Conv2D) (None, 11, 11, 64) 18496
________________________________________________________________
maxpooling2d_2 (MaxPooling2D) (None, 5, 5, 64) 0
________________________________________________________________
conv2d_3 (Conv2D) (None, 3, 3, 64) 36928
================================================================
Total params: 55,744
Trainable params: 55,744
Non-trainable params: 0
Podemos ver que a saída de cada camada de convolução e camada de pooling é um tensor tridimensional. A largura e a altura começam a diminuir à medida que a rede se aprofunda. O número de canais é controlado pelo primeiro parâmetro passado para a camada convolucional.
A próxima etapa é alimentar nosso tensor de saída em uma rede de classificação totalmente conectada. O classificador processa um vetor unidimensional, e nossa saída é um tensor tridimensional, então precisamos compactar nossa saída tridimensional em uma unidimensional. Em seguida, adicionamos uma camada de densidade:
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
A seguir faremos uma classificação de classe 10. Escolhemos softmax como função de ativação e a dimensão de saída é 10. Nossa rede agora se parece com isto:
>>> model.summary()
Layer (type) Output Shape Param #
================================================================
conv2d_1 (Conv2D) (None, 26, 26, 32) 320
________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 13, 13, 32) 0
________________________________________________________________
conv2d_2 (Conv2D) (None, 11, 11, 64) 18496
________________________________________________________________
maxpooling2d_2 (MaxPooling2D) (None, 5, 5, 64) 0
________________________________________________________________
conv2d_3 (Conv2D) (None, 3, 3, 64) 36928
________________________________________________________________
flatten_1 (Flatten) (None, 576) 0
________________________________________________________________
dense_1 (Dense) (None, 64) 36928
________________________________________________________________
dense_2 (Dense) (None, 10) 650
================================================================
Total params: 93,322
Trainable params: 93,322
Non-trainable params: 0
Finalmente usaremos o código que usamos antes para treinar:
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
Em seguida, avalie os resultados finais
>>> test_loss, test_acc = model.evaluate(test_images, test_labels)
>>> test_acc
0.99080000000000001
Por que uma rede neural convolucional simples pode funcionar muito melhor do que um modelo totalmente conectado?Precisamos continuar mergulhando na camada convolucional e na camada de pooling máximo para entender esse assunto.
operador de convolução
Camadas totalmente conectadas aprendem padrões globais, enquanto camadas convolucionais aprendem padrões locais.

As imagens podem ser divididas em padrões locais, como bordas, texturas, etc.
Este recurso principal dá às redes convolucionais duas propriedades interessantes:
-
Os padrões aprendidos são invariantes à tradução e os padrões aprendidos em redes totalmente conectadas dependem da posição, enquanto as redes convolucionais têm maior eficiência de dados.
-
Ele pode aprender a hierarquia espacial dos padrões, conforme mostrado abaixo: a primeira camada aprende pequenos padrões locais, como bordas, mas a segunda camada convolucional aprenderá recursos maiores com base na primeira camada. Isso permitirá que a rede convolucional aprenda a abstrair recursos complexos de maneira mais eficaz.
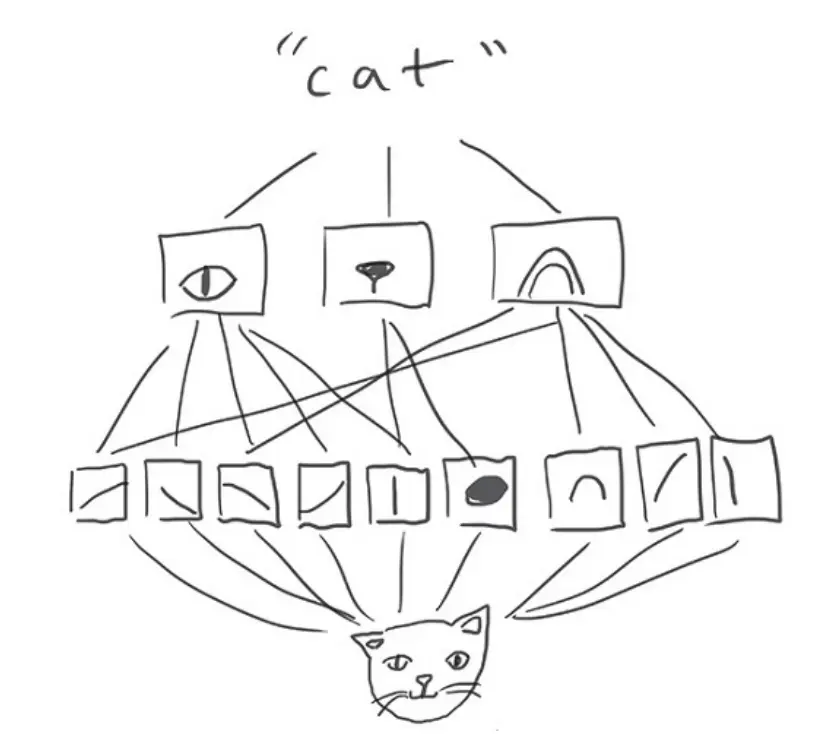
O mundo visual forma uma hierarquia espacial de módulos visuais: bordas hiperlocais combinam-se em objetos locais, como olhos ou ouvidos, que se combinam em conceitos de alto nível, como “gato”.
A operação de convolução em um tensor tridimensional é chamada de "mapa de características", que possui duas coordenadas espaciais (largura e altura) e uma coordenada de profundidade (também chamada de número de canais). Para imagens RGB, a dimensão da profundidade coordenada é 3. Para o MNIST, a profundidade das imagens em preto e branco é 1. O operador de convolução extrai patches do mapa de recursos de entrada e faz algumas transformações em todos os patches e, em seguida, produz nosso mapa de recursos de saída. O mapa de recursos de saída ainda é um tensor tridimensional, mas a profundidade aqui não representa mais uma cor específica, mas algo que chamamos de filtro. Os filtros codificam um aspecto específico dos dados de entrada. Em alto nível, um filtro simples pode codificar a presença de um rosto na entrada.
A convolução é definida pelos dois parâmetros principais a seguir: -
O tamanho dos pedaços de patch extraídos da entrada. No nosso caso geralmente é

de.
- A profundidade do mapa de recursos de saída, ou seja, o número de filtros. No nosso exemplo, começamos com uma profundidade de 32 e terminamos com uma profundidade de 64.
Na camada convolucional de keras, o primeiro parâmetro passado é Conv2D(output_profundidade, (window_height, window_width)).
Uma convolução funciona deslizando, parando em todas as posições possíveis e extraindo patches 3D dos recursos circundantes.
O diagrama esquemático é o seguinte:
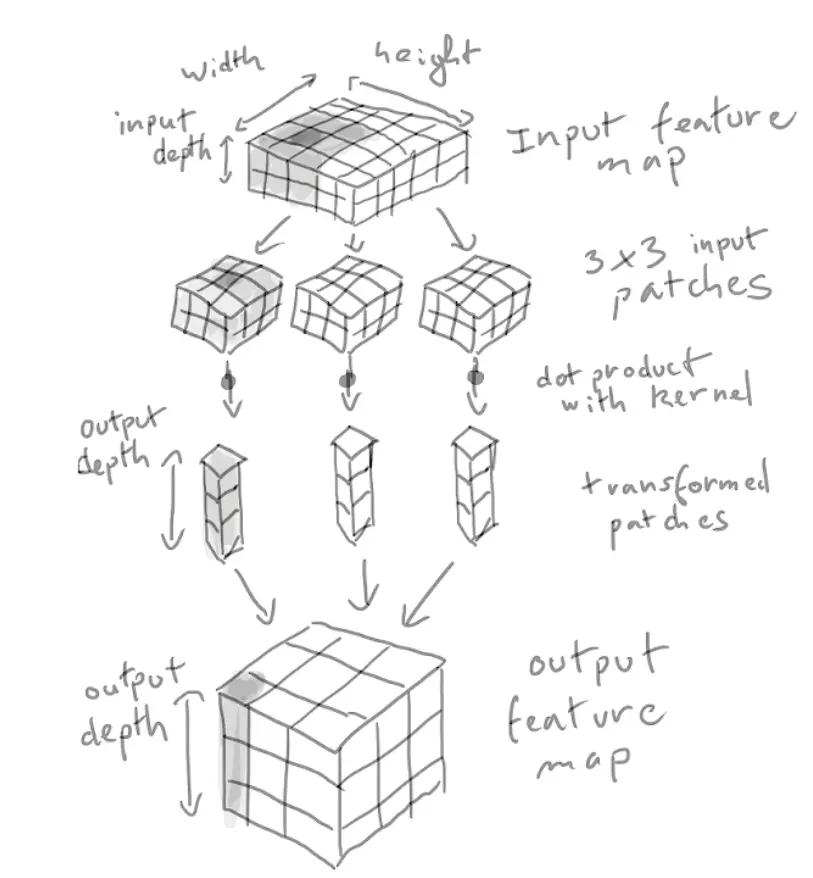
Como funciona a convolução
Observe que a largura e a altura de saída que obtemos podem ser diferentes da largura e altura de entrada. Há duas razões para isso:
- Efeitos de borda, causados pelo preenchimento do mapa de recursos de entrada.
- O uso do deslizamento, definiremos mais adiante.
Vamos dar uma olhada nessas advertências.
Noções básicas sobre efeitos de borda e preenchimento
considere um

mapa de recursos, um total de 25 pequenos blocos. Mas existem apenas 9 pequenas peças diferentes, o que significa que você pode se concentrar em

na pequena janela. Portanto, o mapa de recursos de saída será

: Isso reduz bastante, em dois pequenos blocos em cada dimensão, e você verá o "efeito de limite" no exemplo anterior.
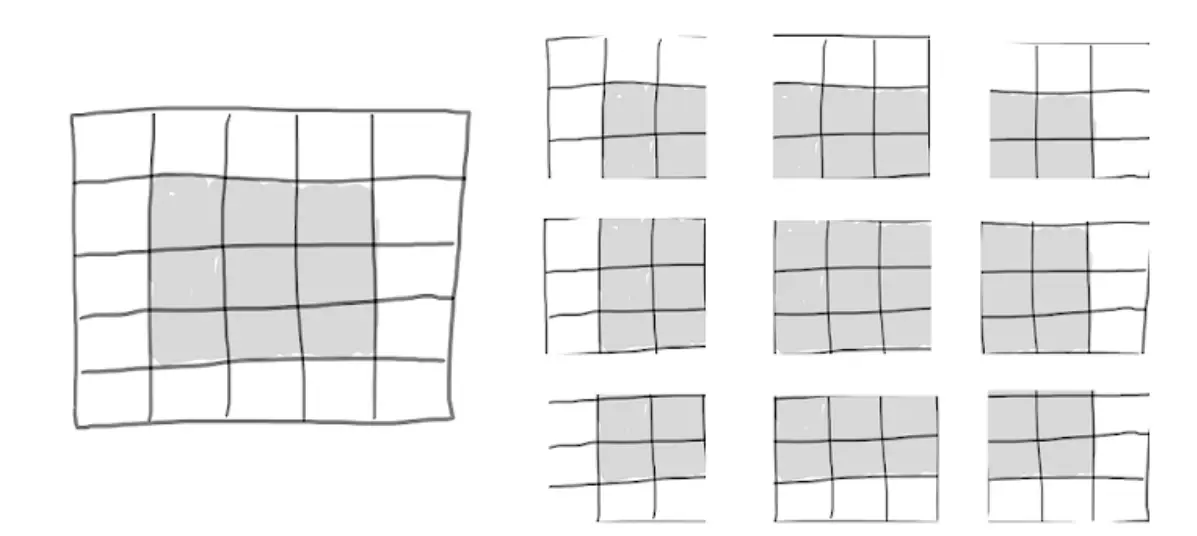
Locais válidos de patches 3x3 em um mapa de recursos de entrada 5x5
Se desejar obter um mapa de recursos de saída idêntico à entrada original, você pode optar por usar preenchimento. Preencha adicionando o número apropriado de vetores de linha e coluna, para
Janela, você pode optar por adicionar uma coluna nos lados esquerdo e direito e adicionar uma linha na parte superior e inferior. para

A janela possui apenas duas linhas.
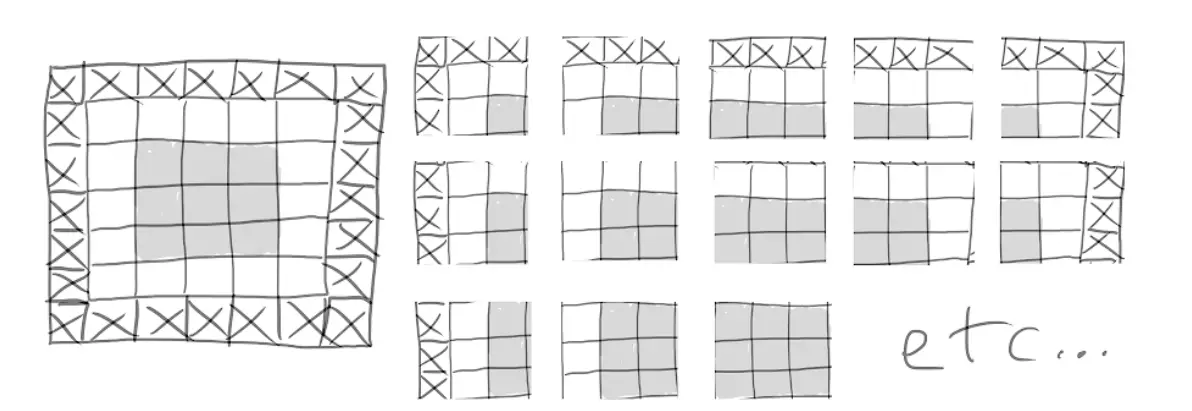
Preenchendo uma entrada 5x5 para poder extrair 25 patches 3x3
Na camada convolucional, o preenchimento pode ser configurado através do parâmetro "padding". O parâmetro "padding" contém dois valores: "válido" e "mesmo". O primeiro significa sem preenchimento, e o último significa fazer com que a entrada e a saída tenham o mesma largura e altura, e o valor padrão do parâmetro de preenchimento é "válido".
Compreendendo o deslizamento de convolução
Outro fator que afeta o tamanho da saída é o “passo”. Em nossa descrição da convolução até agora, assumimos que o bloco central da janela de convolução está configurado. No entanto, na verdade existe um parâmetro de convolução entre duas janelas consecutivas, denominado "stride", com valor padrão de 1. Na próxima foto você pode ver a passada definida como 2.
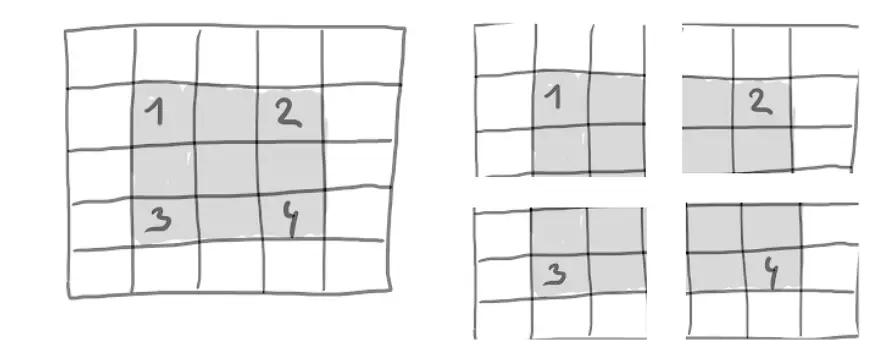
Patches de convolução 3x3 com avanços 2x2
Usar uma passada de 2 significa que a largura e a altura serão reduzidas por um fator de 2. As convoluções deslizantes raramente são usadas na prática, embora possam ser úteis em vários modelos, e é sempre bom estar familiarizado com elas.
Para reduzir a resolução dos recursos, além do deslizamento, isso também pode ser feito por meio do operador max pooling.
operador de pooling máximo
Em nosso exemplo de convolução, você notou que o número de mapas de recursos é reduzido pela metade após o pooling máximo, o que, como a convolução deslizante, é muito agressivo na redução da resolução.
O pooling máximo consiste em extrair uma janela dos recursos de entrada e gerar o valor máximo de cada canal. Isso é muito semelhante à convolução.
Por que fazemos pooling? O que aconteceria se a etapa de pooling fosse removida?
model_no_max_pool = models.Sequential()
model_no_max_pool.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model_no_max_pool.add(layers.Conv2D(64, (3, 3), activation='relu'))
model_no_max_pool.add(layers.Conv2D(64, (3, 3), activation='relu'))
Estrutura de saída:
>>> model_no_max_pool.summary()
Layer (type) Output Shape Param #
================================================================
conv2d_4 (Conv2D) (None, 26, 26, 32) 320
________________________________________________________________
conv2d_5 (Conv2D) (None, 24, 24, 64) 18496
________________________________________________________________
conv2d_6 (Conv2D) (None, 22, 22, 64) 36928
================================================================
Total params: 55,744
Trainable params: 55,744
Non-trainable params: 0
Há algo de errado com essa configuração? Existem dois pontos:
- Isso não conduz ao aprendizado de recursos de nível espacial.

A janela na camada 3 conterá apenas a entrada

Informação. Os recursos de alto nível que as redes convolucionais podem aprender ainda são muito pequenos. Precisamos que a última camada convolucional contenha todas as informações de entrada.
- O recurso final tem muitos coeficientes.
Resumidamente, a redução da resolução é usada para reduzir o número de coeficientes de características, ao mesmo tempo que permite que camadas convolucionais sucessivas processem janelas maiores para reduzir o número de filtros espaciais.
Observe que o pool máximo não é a única maneira de obter redução da resolução. Você também sabe que a passada também pode ser usada e também pode usar o agrupamento médio. No entanto, o pooling máximo geralmente tem um desempenho melhor do que essas alternativas.