
Spark é um mecanismo de computação de big data rápido, versátil e escalonável . Ele tem as vantagens de alto desempenho, facilidade de uso, tolerância a falhas, integração perfeita com o ecossistema Hadoop e alta atividade da comunidade. Em uso real, possui uma ampla variedade de cenários de aplicação:
· Limpeza e pré-processamento de dados: Em cenários de análise de big data, os dados geralmente precisam de operações de limpeza e pré-processamento para garantir a qualidade e a consistência dos dados. O Spark fornece uma API rica que pode limpar, filtrar, transformar e outras operações nos dados.
· Análise de processamento em lote: o Spark é adequado para tarefas de processamento em lote em vários cenários de aplicação, incluindo análise estatística, mineração de dados, extração de recursos, etc. Os usuários podem usar a poderosa API e bibliotecas integradas do Spark para realizar processamento e análise de dados complexos para extrair dados valor intrínseco em
· Consulta interativa: Spark fornece o módulo Spark SQL que suporta consulta SQL . Os usuários podem usar instruções SQL padrão para consulta interativa e análise de dados em grande escala.
O uso do Spark no Kangaroo Cloud
Na plataforma de desenvolvimento offline Kangaroo Cloud Stack , oferecemos três maneiras de usar o Spark:
● Criar tarefas do Spark SQL
Os usuários podem implementar sua própria lógica de negócios diretamente escrevendo SQL. Este método é atualmente a forma mais usada de usar o Spark na plataforma offline de pilha de dados e também é o método mais recomendado.
● Criar tarefa do Spark Jar
Os usuários precisam usar a linguagem Scala ou Java para implementar a lógica de negócios no IDEA, compilar e empacotar o projeto, fazer upload do pacote Jar resultante para a plataforma offline, referenciar esse pacote Jar ao criar uma tarefa Spark Jar e, finalmente, enviar a tarefa. vá para a execução agendada.
Para requisitos que são difíceis de alcançar ou expressar usando SQL, ou os usuários têm outros requisitos mais profundos, as tarefas do Spark Jar sem dúvida fornecem aos usuários uma maneira mais flexível de usar o Spark.
● Criar tarefas PySpark
Os usuários podem escrever diretamente o código Python correspondente . Entre nossa base de clientes, existem alguns clientes para os quais, além do SQL, o Python pode ser sua linguagem principal. Especialmente para usuários com certas análises de dados e fundamentos de algoritmos, eles geralmente realizam análises mais profundas dos dados processados. Neste momento, as tarefas do PySpark são naturalmente sua melhor escolha.
O Spark desempenha um papel importante na plataforma de desenvolvimento offline Kangaroo Cloud Data Stack . Portanto, fizemos muitas otimizações internas no Spark para tornar mais conveniente para os clientes enviar tarefas usando o Spark. Também criamos algumas ferramentas baseadas no Spark para aprimorar a funcionalidade de toda a plataforma de desenvolvimento offline da pilha de dados.
Além disso, o Spark também desempenha um papel muito importante no cenário de data lake. O módulo integrado de lago e armazém do Kangaroo Cloud já suporta dois grandes lagos de dados, Iceberg e Hudi. Os usuários podem usar o Spark para ler e escrever tabelas do lago. A camada inferior do gerenciamento de tabelas do lago também é implementada usando o Spark para chamar diferentes procedimentos armazenados.
A seguir será explicada a otimização feita dentro do Kangaroo Cloud tanto do lado do motor quanto do próprio Spark.
Otimização do lado do motor
As funções do mecanismo interno do Kangaroo Cloud são usadas principalmente para envio de tarefas, aquisição de status de tarefas, aquisição de log de tarefas, interrupção de tarefas, verificação de sintaxe, etc. Otimizamos cada ponto de função em vários graus. A seguir está uma breve introdução por meio de dois exemplos.
Velocidade de envio do Spark on Yarn melhorada
Com o desenvolvimento e melhoria contínua de novas funções no plug-in Spark do lado do motor, o tempo necessário para o lado do motor enviar tarefas do Spark também está aumentando de acordo. Portanto, o código relacionado ao envio de tarefas do Spark precisa ser otimizado para. reduza o tempo de envio de tarefas do Spark. Melhore a experiência do usuário.
Para esse fim, fizemos o seguinte trabalho. Para alguns arquivos de configuração comuns, como core-site.xml, yarn-site.xml, arquivo keytab, spark-sql-application.jar, etc., verifica-se que cada um deles. Ao enviar uma tarefa, você precisará baixá-la em O servidor baixa e envia esses arquivos de configuração. Agora, após a otimização, o arquivo acima só precisa ser baixado uma vez quando o cliente SparkYarnClient é inicializado e, em seguida, carregado no caminho HDFS especificado. O envio subsequente de tarefas Spark só precisa ser especificado para o caminho HDFS correspondente por meio de parâmetros. Dessa forma, o tempo de envio de cada tarefa do Spark é bastante reduzido.
Na nova versão da pilha de dados, para consultas temporárias , também julgaremos a complexidade do SQL a ser executado com base em regras customizadas e enviaremos o SQL menos complexo para o SparkSQLEngine iniciado no lado do motor para agilizar a operação. Este SparkSQLEngine interno era usado apenas para verificação de sintaxe no passado, mas agora também assume parte da função de execução SQL, e o SparkSQLEngine também pode expandir e contrair recursos dinamicamente de acordo com a situação geral de execução para obter uma utilização eficaz dos recursos.
Verificação de gramática
Em versões mais antigas da pilha de dados, para verificação da sintaxe do SQL, o mecanismo enviará primeiro o SQL para o Spark Thrift Server. Este Spark Thrift Server é implantado em modo local e não é usado apenas para verificação de sintaxe. Todos os metadados em outras plataformas são obtidos enviando SQL para este Spark Thrift Server para execução. Este método tem grandes desvantagens, por isso fizemos algumas otimizações. Uma tarefa Spark é iniciada no modo local no lado do mecanismo . Ao executar a verificação de sintaxe, o SQL não é mais enviado ao Spark Thrift Server. Em vez disso, uma SparkSession é mantida internamente para executar diretamente a verificação de sintaxe no SQL.
Embora este método não exija uma conexão forte com o servidor Spark Thrift externo, ele colocará uma certa pressão no componente de agendamento, e a complexidade geral dos Engine-Plugins também aumentará muito durante o processo de implementação.
Para otimizar os problemas acima, fizemos uma otimização adicional. Quando o componente de agendamento é iniciado, ele envia uma tarefa SparkSQLEngine para o Yarn. Pode ser entendido como um servidor Spark Thrift remoto em execução no Yarn. O lado do mecanismo monitora o status de integridade do SparkSQLEngine o tempo todo . Desta forma, toda vez que a verificação de sintaxe é realizada, o mecanismo envia SQL para SparkSQLEngine através do JDBC para verificação de sintaxe.
Através da otimização acima, a plataforma de desenvolvimento offline é desacoplada do Spark Thrift Server e não precisa implantar Spark Thrift Server adicional, tornando a implantação mais leve. Não há necessidade de manter um processo residente do Spark em modo local no lado do agendamento. Ele também abre caminho para o aprimoramento de consultas interativas de tarefas Spark SQL na plataforma de desenvolvimento offline.
A dissociação da plataforma de desenvolvimento offline do Spark Thrift Server implantado pelo EasyManager terá os seguintes benefícios:
· Capaz de realmente realizar a coexistência de vários clusters Spark e múltiplas versões
· A implantação padrão do EasyManager pode remover o Spark Thrift Server e reduzir a carga de operação e manutenção de linha de frente
· A verificação da sintaxe Spark SQL torna-se mais leve, sem necessidade de armazenar em cache o SparkContext, reduzindo o uso de recursos do mecanismo
Otimização da função Spark
À medida que o negócio se desenvolve, descobrimos que o Spark de código aberto não possui implementações funcionais correspondentes em alguns cenários. Portanto, desenvolvemos mais novos plug-ins baseados no Spark de código aberto para oferecer suporte a aplicações mais funcionais da pilha de dados.
Diagnóstico da missão
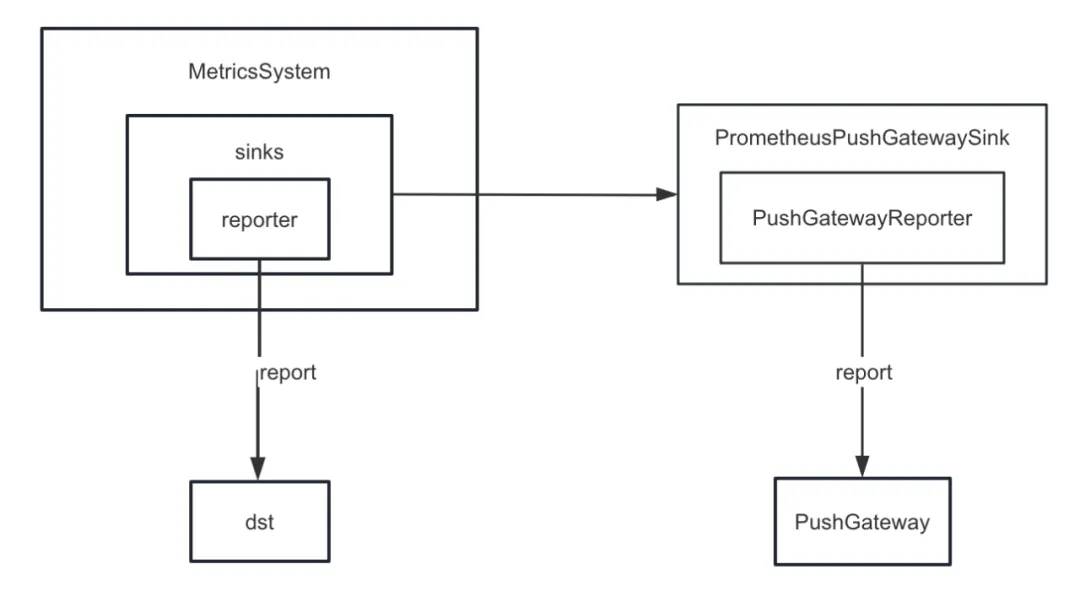
Primeiro, aprimoramos o coletor de métricas do Spark. O Spark fornece vários coletores internamente, além do ConsoleSink, também existem CSVSink, JmxSink, MetricsServlet, GraphiteSink, Slf4jSink, StatsdSink, etc. O PrometheusServlet também foi adicionado após o Spark3.0, mas não atende às nossas necessidades.
Ao desenvolver a função de diagnóstico de tarefas , precisamos enviar os indicadores internos do Spark para o PushGateway de maneira unificada, e o servidor Prometheus extrai periodicamente os indicadores do PushGateway. Finalmente, chamando a interface de consulta fornecida pelo Prometheus, podemos consultar o interno. indicadores do Spark em índice quase em tempo real.

Mas o Spark não implementa indicadores internos de queda no PushGateway. Portanto, adicionamos o plug-in spark-prometheus-sink e personalizamos o PrometheusPushGatewaySink para enviar indicadores internos do Spark para o PushGateway.
Além disso, também personalizamos um novo indicador para descrever o progresso da execução da tarefa de exibição de consulta temporária do Spark SQL. As etapas específicas são as seguintes:
· Adicione um indicador para descrever o progresso das tarefas offline personalizando JobProgressSource e registre o indicador no sistema de gerenciamento de indicadores no sistema de gerenciamento interno do Spark
· Personalize o JobProgressListener e registre o JobProgressListener no ListenerBus no sistema de gerenciamento interno Spark. Entre eles, a lógica do método onJobStart de JobProgressListener é calcular o número de todas as tarefas no trabalho atual; a lógica do método onTaskEnd é calcular e atualizar o progresso da tarefa offline atual após a conclusão de cada tarefa ; O método onJobEnd serve para calcular e atualizar o progresso da tarefa offline atual após a conclusão de cada trabalho. Atualizar o progresso da tarefa offline atual.
Conectando-se à versão comercial do cluster Hadoop
À medida que o número de clientes Kangaroo Cloud aumenta, seus ambientes também variam. Alguns clientes usam a versão de código aberto dos clusters Hadoop e um número considerável de clientes usa HDP, CDH, CDP, TDH, etc. Quando nos conectamos aos clusters desses clientes, o lado do desenvolvimento muitas vezes precisa fazer novas adaptações, e o lado da operação e manutenção também precisa configurar parâmetros adicionais ou realizar outras operações adicionais sempre que for implantado e atualizado.
Tomando o HDP como exemplo, ao conectar ao HDP, o Spark que usamos é o Spark2.3 que vem com o HDP, e também precisamos adicionar alguns parâmetros do lado de operação e manutenção e mover todos os pacotes Jar do Spark que vem com o HDP para especificar o diretório. Na verdade, essas operações trarão alguma confusão e problemas para operação e manutenção. Diferentes tipos de clusters precisam manter diferentes documentos de operação e manutenção, e o processo de implantação também é mais sujeito a erros. E, na verdade, fizemos melhorias funcionais e correções de bugs no código-fonte do Spark. Se você usar o Spark que vem com o HDP, não poderá aproveitar todos os benefícios do nosso Spark mantido internamente.
Para resolver os problemas acima, nosso Spark interno foi adaptado aos editores existentes e comuns no mercado existente. Em outras palavras, nosso Spark interno pode ser executado em todos os clusters Hadoop diferentes. Dessa forma, independentemente do tipo de cluster Hadoop conectado, a operação e manutenção só precisam implantar o mesmo Spark, o que reduz bastante a pressão de implantação de operação e manutenção. Mais importante ainda, os clientes podem usar diretamente nossa versão interna estável do Spark para aproveitar mais novos recursos e maiores melhorias de desempenho.
Novos recursos do Spark3.2 - AQE
Nas versões mais antigas do Data Stack, a versão padrão do Spark é 2.1.3. Posteriormente, atualizamos a versão do Spark para 2.4.8. A partir do Data Stack 6.0, o Spark 3.2 também pode ser usado. Aqui nos concentramos no AQE , que também é o novo recurso mais importante do Spark3.x.
Visão geral da AQE
Antes do Spark3.2, o AQE era desativado por padrão. Você precisa definir spark.sql.adaptive.enabled como true para ativar o AQE. Após o Spark3.2, o AQE é habilitado por padrão, desde que a tarefa atenda às condições de disparo do AQE durante a operação, você poderá aproveitar a otimização trazida pelo AQE.
Deve-se observar que a otimização do AQE ocorrerá apenas na fase de embaralhamento. Se a operação de embaralhamento não estiver envolvida no processo de execução do SQL, o AQE não desempenhará um papel, mesmo que o valor de spark.sql.adaptive.enabled seja. verdadeiro. Mais precisamente, o AQE só terá efeito se o plano de execução física contiver um nó de troca ou uma subconsulta.
Durante a operação, o AQE coleta as informações dos arquivos intermediários gerados no estágio do mapa aleatório, coleta estatísticas sobre essas informações e ajusta dinamicamente o Plano Lógico Otimizado e o Plano Spark que ainda não foram executados com base nas regras existentes, modificando assim o original Instrução SQL.
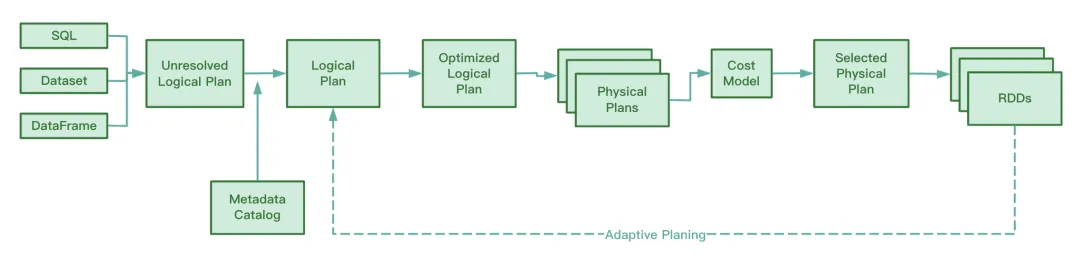
A julgar pelo código-fonte do Spark, o AQE envolve as quatro regras de otimização a seguir:

Sabemos que o RBO otimiza o SQL com base em uma série de regras, incluindo empilhamento de predicados, remoção de colunas, substituição constante, etc. Essas regras estáticas foram incorporadas ao Spark. Quando o Spark executa o SQL, essas regras serão aplicadas ao SQL uma por uma.
Vantagens da AQE
Este recurso do CBO só está disponível após o Spark2.2. Em comparação com o RBO, o CBO combinará as informações estatísticas da tabela e selecionará um plano de execução mais otimizado com base nessas informações estatísticas e no modelo de custo.
No entanto, o CBO oferece suporte apenas a tabelas registradas no Hive Metastore. O CBO não oferece suporte a arquivos como parquet e orc armazenados em sistemas de arquivos distribuídos. Além disso, se a tabela Hive não tiver informações de metadados, o CBO não poderá coletar estatísticas ao coletar estatísticas, o que pode causar falha no CBO.
Outra desvantagem do CBO é que o CBO precisa executar ANALYZE TABLE COMPUTE STATISTICS para coletar informações estatísticas antes da otimização. Se esta instrução encontrar uma tabela grande durante a execução, consumirá mais tempo e a eficiência da coleta será baixa.
Quer seja CBO ou RBO, são otimizações estáticas. Após o envio do plano de execução física, se o volume e a distribuição dos dados mudarem durante a execução da tarefa, o CBO não otimizará o plano de execução física existente.
Diferente de CBO e RBO, durante o processo de execução, o AQE analisará os arquivos intermediários gerados durante o processo de mapa aleatório e ajustará e otimizará dinamicamente o plano de execução lógica e o plano de execução física que ainda não iniciou a execução em comparação com o CBO estaticamente otimizado. , Comparado com RBO, o processamento AQE pode obter um plano de execução física mais otimizado .
AQE três recursos principais
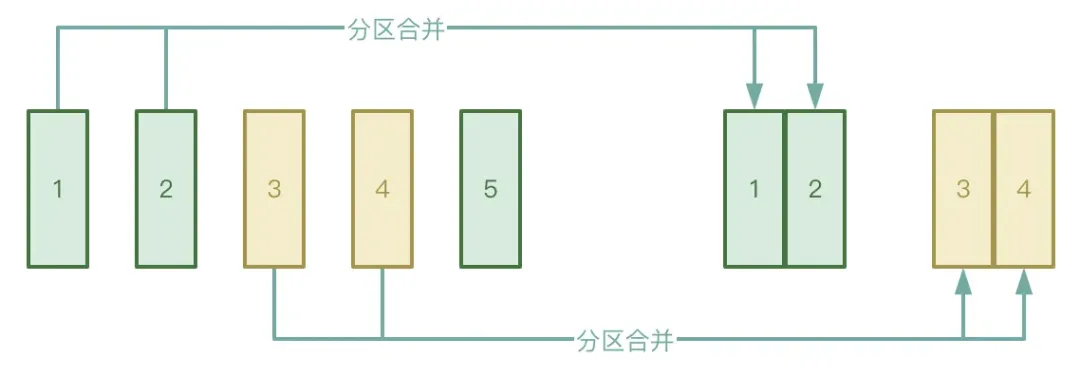
● Mesclagem automática de partições
O processo Shuffle é dividido em dois estágios: estágio Map e estágio Reduzir. O estágio Reduzir puxará os arquivos temporários intermediários gerados no estágio Map para o Executor correspondente. Se os dados processados pelo estágio Map estiverem distribuídos de forma muito desigual, há muitos. chaves. Na verdade, existem apenas algumas chaves de dados, os dados podem formar um grande número de pequenos arquivos após o processamento.
Para evitar a situação acima, você pode ativar a função de mesclagem automática de partições do AQE para evitar iniciar muitas tarefas de redução para extrair os pequenos arquivos gerados no estágio Map.
● Processamento automático de distorção de dados
O cenário do aplicativo é principalmente em junções de dados. Quando ocorre distorção de dados, o AQE pode detectar automaticamente a partição distorcida e dividi-la de acordo com certas regras. Atualmente, no Spark3.2, o processamento automático de distorção de dados é compatível com SortMergeJoin e ShuffleHashJoin.
● Junte-se ao ajuste da estratégia
AQE fará o downgrade dinamicamente de Hash Join e Sort Merge Join para Broadcast Join.
Sabemos que assim que uma tarefa Spark começa a ser executada, o grau de paralelismo é determinado. Por exemplo, no estágio de mapa aleatório , o paralelismo é o número de partições no estágio de redução aleatória, o paralelismo é o valor de spark.sql.shuffle.partitions, cujo padrão é 200. Se a quantidade de dados diminuir durante a execução da tarefa Spark, fazendo com que o tamanho da maioria das partições diminua, isso levará a um desperdício de recursos se tantos threads ainda forem iniciados para processar o pequeno conjunto de dados.
Durante o processo de execução, o AQE mesclará automaticamente as partições com base nos resultados temporários intermediários gerados após o embaralhamento e, sob certas condições, aplicando regras CoalesceShufflePartitions e combinando os parâmetros fornecidos pelo usuário, o que na verdade ajusta o número de redutores. Originalmente, um thread de redução extrairia apenas os dados de uma partição processada. Agora, um thread de redução extrairá os dados de mais partições de acordo com a situação real, o que pode reduzir o desperdício de recursos e melhorar a eficiência da execução da tarefa. Endereço para download do "White Paper do Sistema de Indicadores da Indústria": https://www.dtstack.com/resources/1057?src=szsm
Endereço de download do "White Paper do produto Dutstack": https://www.dtstack.com/resources/1004?src=szsm
Endereço para download do "White Paper sobre práticas da indústria de governança de dados": https://www.dtstack.com/resources/1001?src=szsm
Para quem deseja conhecer ou consultar mais sobre produtos de big data, soluções industriais e cases de clientes, visite o site oficial da Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Decidi desistir do código aberto Hongmeng Wang Chenglu, o pai do código aberto Hongmeng: Hongmeng de código aberto é o único evento de software industrial de inovação arquitetônica na área de software básico na China - o OGG 1.0 é lançado, a Huawei contribui com todo o código-fonte. Google Reader é morto pela "montanha de merda de código" Fedora Linux 40 é lançado oficialmente Ex-desenvolvedor da Microsoft: o desempenho do Windows 11 é "ridiculamente ruim" Ma Huateng e Zhou Hongyi apertam as mãos para "eliminar rancores" Empresas de jogos conhecidas emitiram novos regulamentos : os presentes de casamento dos funcionários não devem exceder 100.000 yuans Ubuntu 24.04 LTS lançado oficialmente Pinduoduo foi condenado por concorrência desleal Compensação de 5 milhões de yuans