

Autor | Algum dia
Introdução
Este artigo apresenta principalmente os conceitos e aplicações de business intelligence (BI) e Turing Data Analysis (TDA). O BI ajuda as empresas a tomar melhores decisões e planejamento estratégico, coletando, organizando, analisando e apresentando dados. No entanto, existem problemas com as ideias tradicionais de construção de BI, como a necessidade de redesenvolvimento quando o negócio altera os requisitos de dados e a baixa eficiência da análise dos dados subjacentes. Portanto, o TDA surgiu como uma plataforma de análise de autoatendimento completa. Ele constrói conjuntos de dados públicos de acordo com temas de análise com base em dados detalhados. Os usuários podem arrastar e soltar livremente a análise e salvar os resultados com um clique, e também podem compartilhá-los. outros para visualização. No entanto, a construção de TDA também enfrenta desafios como indicadores de dimensão de análise abrangente, calibre preciso de dados e desempenho de consulta. Em resposta a estes desafios, apresentamos os objetivos de integridade, precisão, eficiência e velocidade, e atingimos esses objetivos através de mecanismos de processo e construção de funções, bem como do motor de dados MPP.
O texto completo tem 4.766 palavras e o tempo estimado de leitura é de 15 minutos.
01 Contexto e Objetivos
BI significa Business Intelligence, que ajuda as empresas a ficarem à frente dos seus concorrentes e a tomarem melhores decisões de negócios e planeamento estratégico através da recolha, organização, análise e apresentação de dados. O processo de coleta e organização é a construção de um data warehouse, e a análise e apresentação dos dados é a construção de uma plataforma de análise visual.
Uma ideia comum de construção de BI na indústria: se a empresa quiser ver as alterações nos dados de um determinado indicador, ela solicita ao middle office que os dados RD sejam modelados camada por camada de ODS>DWD>DWS>ADS e depois customizados. A tabela de resultados ADS é desenvolvida e implementada em Palo/Mysql e, por fim, configura vários gráficos e os salva em relatórios para visualização do negócio. Embora esta ideia de construção atenda às necessidades de análise de dados do negócio, ela enfrenta dois problemas: 1. Quando o negócio altera os requisitos de dados, a tabela de resultados ADS precisa ser customizada e desenvolvida novamente, o que ocupará repetidamente mão de obra de P&D 2. Ela apenas resolve o problema; problema de análise de negócios. Se você quiser aprofundar e analisar os motivos das flutuações, será difícil porque a tabela subjacente é uma tabela agregada que contém apenas os dados do gráfico atual. os dados detalhados e depois analisá-los através do Excel ou outros métodos, o que é relativamente ineficiente.
TDA (Turing Data Analysis) é uma plataforma de análise de autoatendimento completa construída para resolver o problema mencionado acima de longos links de análise em BI.
A ideia de construção do TDA: Com base na ampla tabela detalhada do DWD, os conjuntos de dados públicos são construídos de acordo com o tema de análise (os dados de um dia são dezenas de milhões + Os usuários podem arrastar e soltar a análise com base nos conjuntos de dados públicos). gratuitamente, e os resultados da análise podem ser salvos em painéis pessoais ou publicados com um clique. Crie um painel público e compartilhe-o com outras pessoas que podem verificar a tendência de flutuação no painel público, detalhar a página de análise visual para continuar explorando o; causas das flutuações e conclua a análise completa de "ver tendências, quebrar dimensões e descobrir detalhes" Três eixos.
A figura a seguir mostra o processo geral de ideias de construção de TDA:
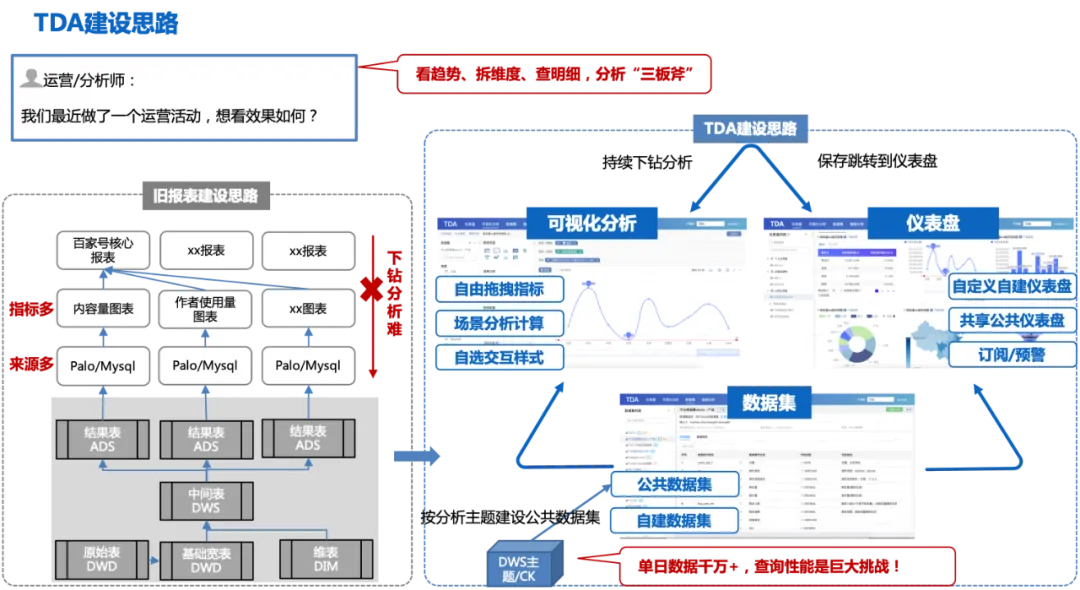
Esta ideia de construção também enfrentará alguns desafios:
1. Os indicadores da dimensão de análise devem ser completos, caso contrário, será necessário construir vários conjuntos de dados, resultando em muitos e dispersos conjuntos de dados, o mesmo problema da construção do relatório anterior;
2. O calibre dos dados deve ser preciso e confiável;
3. Com dezenas de milhões de dados em um único dia, o desempenho das consultas é um enorme desafio.
Em resposta aos desafios acima, também formulamos metas correspondentes para atender às necessidades de uma análise de negócios eficiente:
1. Completo (os indicadores da dimensão de análise devem ser completos, abrangendo mais de 80% das necessidades do negócio);
2. Preciso (calibre uniforme, dados precisos);
3. Pontualidade (a pontualidade da saída dos dados é T+10h);
4. Rápido (consulta de dados de nível de 1 bilhão em 10 segundos).
A plataforma TDA garantirá a construção de conjuntos de dados completos, precisos e eficientes do ponto de vista do mecanismo de processo e construção de funções, combinada com o mecanismo de dados MPP para garantir o desempenho da consulta e melhorar a eficiência da análise dos usuários por meio de arrastar e soltar visual do BI, análise de cena, modelagem de autoatendimento e outros recursos.
02 Solução técnica
Com base na análise acima, o posicionamento do produto da TDA é uma plataforma de BI que permite aos usuários obter consultas de autoatendimento completas.Os usuários podem arrastar e soltar livremente conjuntos de dados, realizar análises visuais de dados e construir painéis principais. Ajude os usuários a obter uma experiência completa de análise de consultas nas seguintes perspectivas:
Iteração Kanban de negócios e melhoria de eficiência (autoatendimento) : O modo de iteração do relatório de dados mudou, do modo de agendamento RD de solicitação PM para gradualmente convertido para operação de autoatendimento PM/operação (fazendo Kanban/analisando dados).
Melhoria da eficiência da análise de insights de dados (extremamente rápida) : uma única consulta de dados é reduzida de minutos para segundos, a eficiência da análise de flutuação do indicador é aumentada em 20 vezes e a análise ponta a ponta da atribuição de flutuação de indicador único ocorre dentro de 2 horas -> 5 minutos.
Análise de negócios de autoatendimento completa (one-stop) : realiza observação de tendências de dados, análise detalhada dimensional, exportação detalhada e outras funções, realizando uma experiência integrada de monitoramento e análise de dados.
A matriz de funções deste produto é a seguinte:
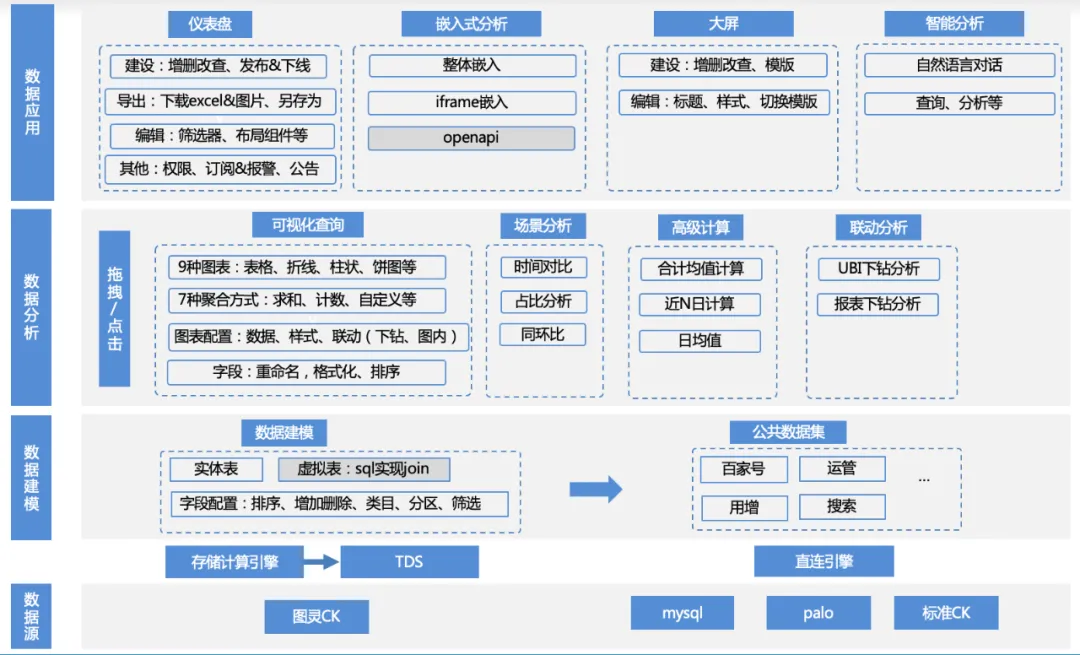
1. Acesso à fonte de dados : a empresa usa TDS para calcular os dados da tabela Turing upstream por meio do mecanismo de cálculo e, em seguida, grava os dados em mecanismos como clickhouse/mysql/palo e os acessa por meio de conexão direta; ou a empresa fornece seu próprio palo / acesso à fonte de dados mysql.
a. Gerenciamento de fonte de dados: adição, exclusão, modificação e consulta de fonte de dados, clickhouse/mysql/palo e outras adaptações de driver de mecanismo
2. Modelagem de dados : Após conectar-se à fonte de dados, os dados podem ser carregados no produto escrevendo SQL e diretamente da tabela original. Mas essas tabelas geralmente requerem algum processamento secundário simples para transformá-las em conjuntos de dados que possam ser analisados.
a. Gerenciamento de conjunto de dados: funções como adição, exclusão, modificação, visualização de dados, visualização de esquema, análise visual com um clique, etc.
b. Gerenciamento de campos do conjunto de dados: adição, exclusão, modificação, classificação de campos, campos personalizados, etc.
c. Gerenciamento de categorias de conjuntos de dados: adição, exclusão, modificação e classificação personalizada das categorias às quais os campos pertencem, etc.
d. Gerenciamento do diretório do conjunto de dados: adição, exclusão, modificação e classificação personalizada do diretório do conjunto de dados, etc.
3. Análise de dados : com base no conjunto de dados, os usuários podem arrastar e soltar livremente indicadores, dimensões, filtros, selecionar tipos de gráficos e métodos de análise de cenário apropriados e realizar análises e cálculos.
a. Configuração de dados: alterne conjuntos de dados, adicione campos personalizados
b. Configuração do gráfico: tabela, gráfico de linhas, gráfico de barras, gráfico de pizza e outras configurações de tipo de gráfico, configurações de cores de legenda, configurações de formato de dados, etc.
c. Análise de cenário: suporte para vários recursos de análise de cenário, como valor médio diário, comparação ano a ano, proporção, total, etc.
d. Análise de atribuição: recursos de análise de atribuição de autoatendimento
e. Análise interativa: análise detalhada, etc.
4. Aplicativo de dados : os usuários podem salvar os resultados da análise no painel, incorporá-los em uma plataforma de terceiros, salvá-los na tela grande ou usá-los diretamente para análises inteligentes, etc.
a. Gerenciamento de painel: adição, exclusão, modificação de painel, classificação personalizada, publicação e off-line, exportação de dados, alertas de assinatura, etc.
b. Análise incorporada: iframe incorporado, SDK incorporado e outros modos incorporados
c. Tela grande: tela grande em tempo real
d. Análise inteligente: análise conversacional LUI
2.1 Projeto geral
A arquitetura geral do TDA é mostrada na figura abaixo:
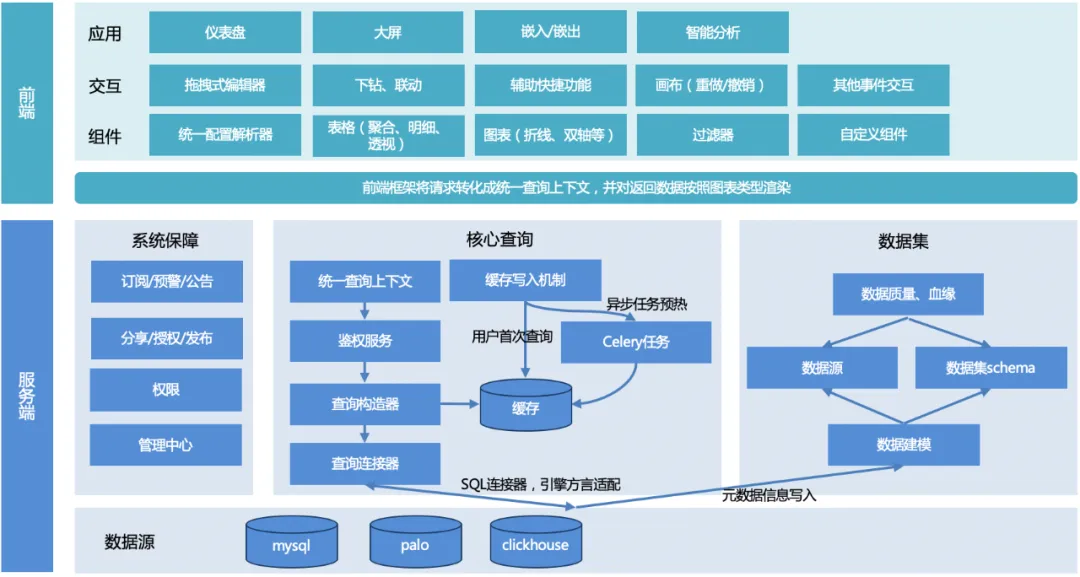
O processo geral: o usuário inicia uma consulta, o servidor unifica o contexto da consulta, constrói o objeto de consulta, adapta o dialeto do mecanismo subjacente, retorna um formato de dados unificado e, em seguida, a estrutura de renderização front-end se adapta e renderiza de acordo com o tipo de gráfico .
Servidor:
1. Contexto de consulta unificado : Para facilitar a reutilização de funções comuns ao expandir outras funções do gráfico posteriormente, um contexto de consulta unificado é projetado.
2. Construtor de consulta : Construa um objeto de consulta (pode ser múltiplo, por exemplo, para paginar uma tabela, você precisa construir dois objetos de consulta, um é um objeto de consulta de paginação e o outro é um objeto de consulta de contagem) de acordo com a solicitação parâmetros passados do front-end.
3. Conector de consulta :
a. Atualmente existe apenas um conector SQL, que é usado para satisfazer o mecanismo de consulta SQL (mysql, palo, clickhouse, etc.). Diferentes mecanismos, sintaxe ou algumas funções podem ser diferentes e devem ser adaptados através de diferentes mecanismos configurações de regras;
b. Outros conectores podem ser expandidos para satisfazer consultas não SQL no futuro.
4. Escrita de cache : Para garantir o desempenho da consulta, existem dois métodos de escrita: escrever quando o usuário acessa pela primeira vez ou pré-aquecer o cache por meio de tarefas agendadas de aipo.
5. Módulo de conjunto de dados : Fornece suporte de dados, estabelece links com fontes de dados subjacentes e garante a qualidade dos dados.
6. Módulo de garantia do sistema : Assinatura, alerta antecipado e anúncio realizam recursos de alerta antecipado de dados. O compartilhamento, a publicação e a autorização melhoram a eficiência da circulação de dados.
front-end:
1. Biblioteca de componentes : fornece análise de configuração, diferentes componentes de renderização de gráficos, componentes de filtro e recursos de componentes personalizados.
2. Interação : encapsula recursos de interação de página, incluindo editor de arrastar e soltar, link de detalhamento, funções de atalho auxiliares, recursos de tela e outras interações de eventos.
3. Aplicação : Implemente diferentes aplicações visuais para diferentes usuários e cenários de uso, como painéis, telas grandes, etc.
2.2 Projeto detalhado
2.2.1 Consulta principal
O BI de autoatendimento completo, por meio de ideias de modelagem de conjuntos de dados públicos, concretiza a ideia de análise de três pontos de "tendências, dimensões e detalhes", que enfrentará muitos desafios, incluindo:
-
Dados de várias fontes, apresentação de vários gráficos e análise e cálculos de vários cenários : há mais de um mecanismo de fonte de dados subjacente no sistema de BI. Para expandir de forma flexível as fontes de dados, o estilo de apresentação também requer suporte gráfico rico, e pelo menos. ao mesmo tempo, para atender à análise em diferentes cenários, o cálculo precisa oferecer suporte a recursos de análise comuns, como valores médios mensais e diários.
-
Consultar dezenas de milhões de dados em segundos : A ideia de construir conjuntos de dados públicos facilita a análise, mas também introduz novos desafios. A quantidade de dezenas de milhões de dados em um único dia representa um enorme desafio para o desempenho das consultas.
Em resposta aos problemas acima, foram formuladas soluções correspondentes:
-
Consulta unificada : unifique o contexto da consulta, construa o objeto de consulta, adapte o dialeto do mecanismo subjacente, retorne um formato de dados unificado e a estrutura de renderização front-end adapta a renderização de acordo com o tipo de gráfico.
-
Otimização de consultas : Ⅰ> Cache + rolagem automática, cobrindo 70% das solicitações do painel público; Ⅱ> Otimizando a construção de consultas SQL e fazendo uso total dos recursos de agregação do lado do mecanismo; III> Múltiplas solicitações simultâneas de nomes de domínio e processamento de respostas multi-rotinas .
Consulta unificada:
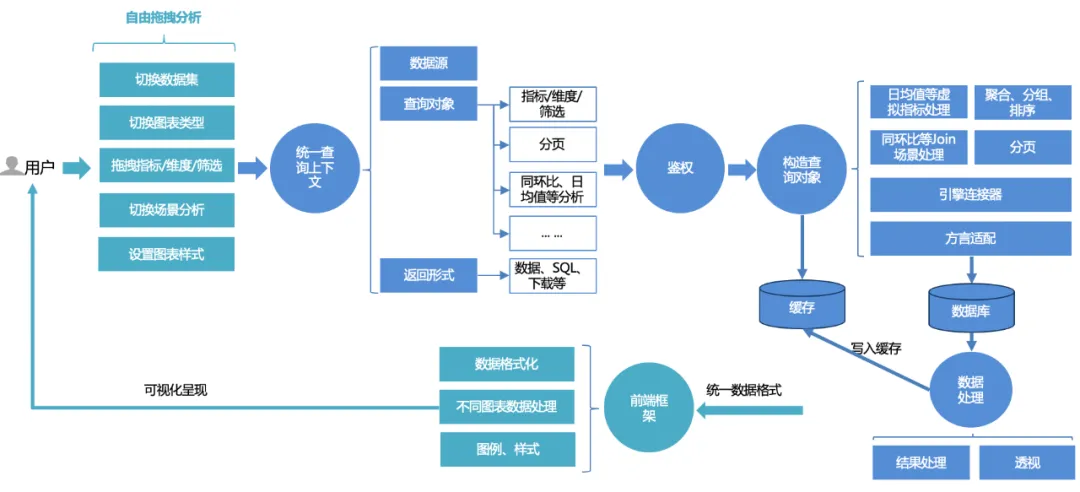
O processo de consulta unificado para usuários da plataforma é o seguinte:
1. Os usuários podem arrastar e soltar livremente a análise na página : alternar conjuntos de dados, alternar entre diferentes tipos de gráfico, arrastar e soltar indicadores, dimensões, filtros e consultas; ou, se quiserem usar alguns recursos avançados de análise de cena, podem alternar configurações com um clique.
2. A solicitação de front-end será processada em um contexto de consulta unificado : incluindo fonte de dados, objeto de consulta e formulário de retorno. O objeto de consulta encapsula indicadores básicos, dimensões, informações de filtragem e configurações de análise avançada, como ano a ano. comparação e valor médio diário.
3. Serviço de autenticação unificada : baseado no núcleo da autenticação dupla do painel e do conjunto de dados, ele também suporta controle de permissão mais refinado de permissões de linha e linha.
4. Construa o objeto de consulta : primeiro conclua a construção SQL básica (agregação, agrupamento, filtragem) com base em indicadores, dimensões e triplos de filtragem, depois monte a lógica de classificação de acordo com as regras de classificação e adicione algumas opções de análise avançada (como mês a mês, média diária, etc.) A lógica de montagem adicional e o processamento de paginação precisam ser combinados com a adaptação de dialeto. Ao consultar dados, consulte diferentes bancos de dados (como mysql, palo, clickhouse, etc.) de acordo com o mecanismo diferente. ligantes.
5. Consultar e processar dados : Após consultar os dados por meio do vinculador, processe os dados (processamento de formato de data, perspectiva de gráficos de linhas, etc.).
6. Cache : os dados processados são gravados no cache ou, se o cache for atingido diretamente durante a consulta, os dados armazenados em cache serão lidos e retornados diretamente.
7. Renderização unificada da estrutura de renderização de front-end : retorna um formato de dados unificado e o front-end completa a renderização adaptativa de gráficos, estilos, etc.
Otimização de consultas: Ⅰ>Cache + roll-up automático, cobrindo 70% das solicitações do painel público.
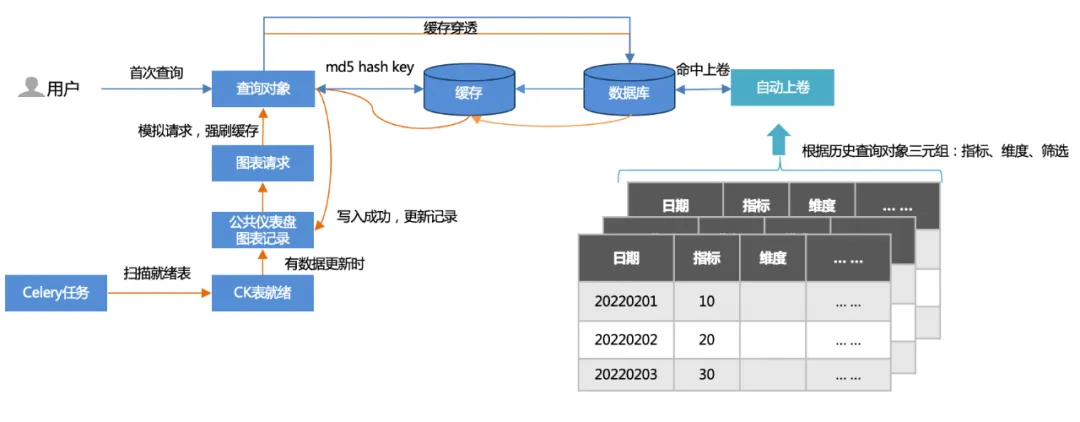
1. Dois métodos de cache :
Primeira consulta: o usuário primeiro acessa (penetração do cache), consulta o banco de dados e depois grava no cache.
Aquecimento de tarefas off-line: verifique os registros do gráfico do painel público e simule solicitações de gráfico (mais de 500 por atualização) para forçar a liberação do cache.
2. Enrolamento automático :
Com base nos triplos (indicadores, dimensões, filtragem) de consultas históricas, uma tabela roll-up é estabelecida e a consulta atinge a tabela roll-up. A quantidade de dados consultados é bastante reduzida e o desempenho é acelerado.
Otimização de consultas: Ⅱ> Otimize a construção de consultas SQL e aproveite ao máximo os recursos de agregação dos mecanismos de arquitetura MPP (como clickhouse/palo, etc.).

No cenário de análise de conjunto de dados públicos, após consultar os dados, é quase impossível agregá-los e calculá-los na memória (por exemplo, (a + b) / c precisa ser agregado e calculado com base nos dados detalhados a, b , c), e você precisa usar o MPP do lado do mecanismo. A capacidade de consulta da arquitetura refina o cálculo de agregação para o lado do mecanismo para execução, assim como a agregação mês a mês, o volume de dados envolve dezenas de bilhões, os dados o volume após o cálculo de agregação do lado do motor é reduzido dezenas de vezes, e o desempenho também é melhorado várias vezes.
Otimização de consulta: III> Solicitações simultâneas de vários nomes de domínio, processamento de resposta multi-rotina.
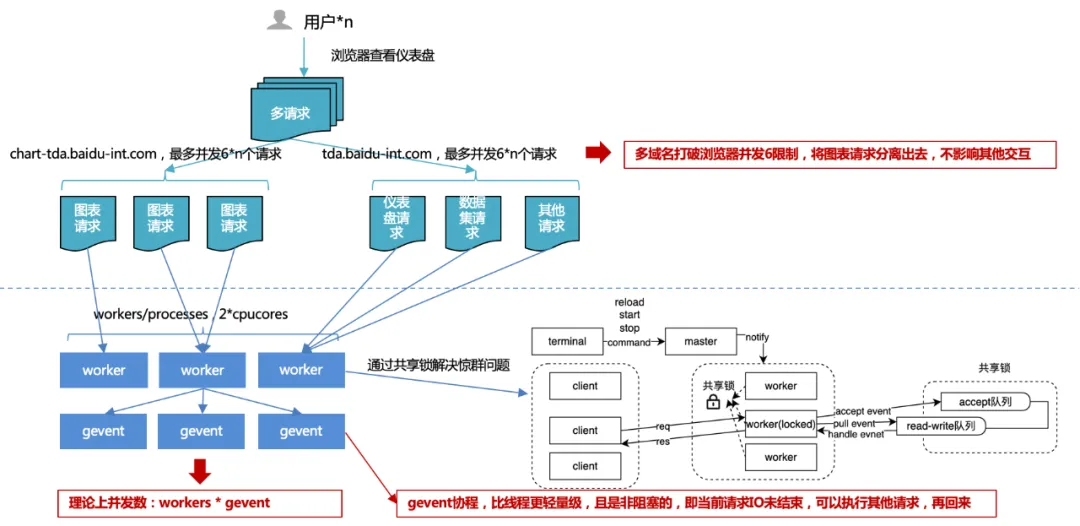
1. Limite de simultaneidade do navegador de 6 : Ao usar vários nomes de domínio, as solicitações de gráficos são descarregadas de outras solicitações para garantir uma interação suave com a plataforma e maior simultaneidade de solicitações de gráficos, melhorando assim o desempenho geral.
Considere os recursos de porta do sistema operacional: o número total de portas do PC é 65.536, portanto, um link TCP (http também é tcp) ocupa uma porta. O sistema operacional geralmente abre metade do total de portas para solicitações externas para evitar que o número de portas se esgote rapidamente.
A simultaneidade excessiva leva a problemas frequentes de comutação e desempenho: um thread lida com uma solicitação http, portanto, se o número de simultaneidades for enorme, ocorrerá troca frequente de threads. E a troca de contexto de thread às vezes não é um recurso leve. Isso resulta em mais perdas do que ganhos, portanto, um pool de conexões será gerado no controlador de solicitações para reutilizar conexões anteriores. Portanto, podemos pensar que o número máximo de pools de conexões sob o mesmo nome de domínio é de 4 a 8. Se todos os pools de conexões forem usados, as tarefas de solicitação subsequentes serão bloqueadas e as tarefas subsequentes serão executadas quando houver links livres.
Impedir que um grande número de solicitações simultâneas do mesmo cliente exceda o limite de simultaneidade do servidor: O servidor geralmente define um limite de simultaneidade para a mesma origem do cliente para evitar ataques maliciosos. Se o navegador não definir limites de simultaneidade para o mesmo nome de domínio, ele. pode fazer com que o limite de simultaneidade do servidor seja excedido. Foi banido.
Mecanismo de consciência do cliente: Para evitar que duas aplicações se apoderem de recursos, a parte mais forte obterá recursos sem restrições, fazendo com que a parte mais fraca seja permanentemente bloqueada.
2. Multiprocessos + simultaneidade de múltiplas rotinas no lado do servidor :
Ao desenvolver com vários processos, você pode encontrar o "problema do rebanho trovejante", onde vários processos aguardam pelo mesmo evento. Quando ocorre um evento, todos os processos serão despertados pelo kernel, mas após acordar, apenas um processo obtém o evento e o processa. Os outros processos continuam a entrar no estado de espera após descobrir que a aquisição do tempo falhou. Se você ouvir o mesmo evento, quanto mais processos houver, mais séria será a disputa pela CPU, resultando em sérios custos de contexto.
Portanto, em resposta a esta situação, o serviço uwsgi projetou e implementou um mecanismo de bloqueio compartilhado para garantir que apenas um processo monitore eventos ao mesmo tempo, resolvendo assim o problema do rebanho trovejante.
Mas mesmo assim, o número de processos não pode ser expandido sem limites. Geralmente é recomendado igualar 2 vezes o número de núcleos da CPU.
Então, como o número de processos é limitado, como melhorar o rendimento? Em circunstâncias normais, o IO é bloqueado Quando você está lendo um banco de dados ou arquivo, o processo ou thread atual aguardará até que a operação IO retorne o resultado antes de continuar a executar o código subsequente. Se aumentarmos o rendimento por meio de multithreading e encontrarmos bloqueio de IO, o thread ficará preso e outras solicitações simultâneas não serão processadas pelo thread. O IO assíncrono é implementado por meio de corrotinas, ou seja, para cada thread, quando é IO. Depois de esperar pelo resultado do IO, primeiro processamos a nova solicitação, esperamos até que o IO seja concluído e, em seguida, voltamos para o código que precisa aguardar o IO. Desta forma, aproveitamos ao máximo todos os threads do programa e sempre temos algo para fazer. Este método melhora o rendimento geral e reduz o tempo geral, sem afetar o tempo individual.
2.2.2 Garantia do sistema
Assine os alertas:
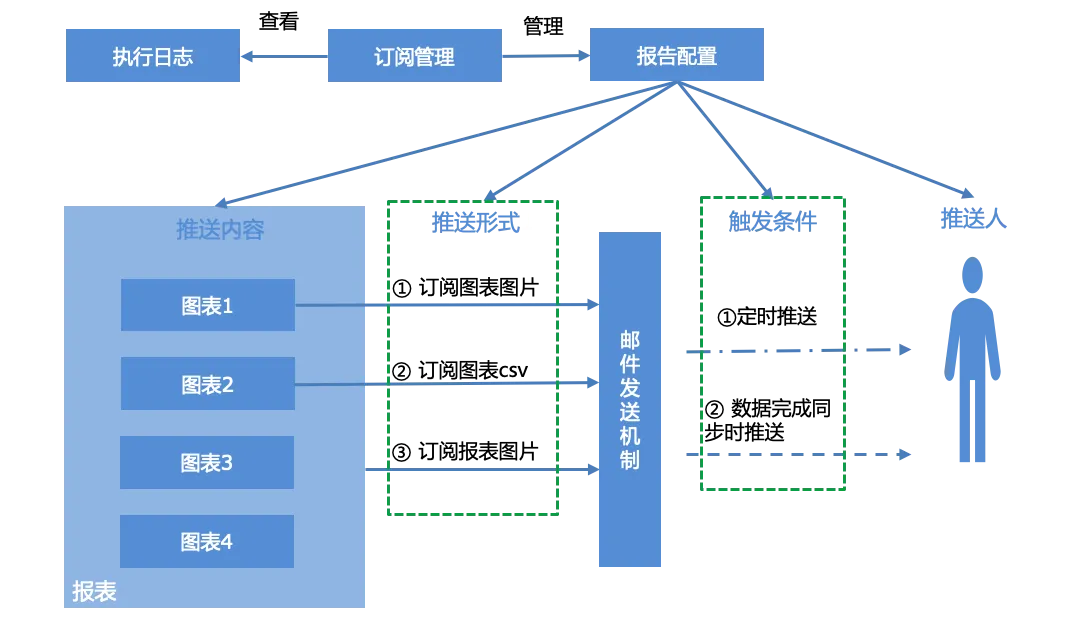
Os usuários podem configurar relatórios para relatórios, gerenciar relatórios de assinatura gerados de acordo com a interface de gerenciamento de assinaturas e visualizar o log de execução do sistema, ou seja, o status push dos relatórios.
A configuração do relatório inclui principalmente quatro partes: conteúdo push, formulário push, condições de disparo e pusher:
Conteúdo push : gráfico único, relatório inteiro
Formulário push : três formas de push
Captura de tela do gráfico
Anexo de e-mail de dados do gráfico csv
Captura de tela do relatório
Condições de desencadeamento :
Push agendado, push agendado com base na expressão cron.
Enviado quando a sincronização de dados é concluída. Quando os conjuntos de dados associados a todos os gráficos do relatório concluem a sincronização de dados, as condições de envio são acionadas e as notificações por e-mail são concluídas.
Pusher : Conta de e-mail, separada por "," se houver várias.
Permissões:

Gerenciamento e controle hierárquico de permissão de dados: com base no núcleo de autenticação de camada dupla do conjunto de dados e do painel, ele oferece suporte a permissões de linha e coluna para solicitar autorização de acordo com a granularidade da regra e controla de maneira flexível as permissões do usuário.
Colaboração eficiente: Abra o serviço de autoridade unificada MPS (sistema de gerenciamento de autoridade unificado), realize a aprovação de autoridade, recuperação de expiração, congelamento de demissões e outros recursos, abra um escritório tranquilo, acelere a circulação em alta velocidade da aprovação de autoridade.
03 Resumo e planejamento
3.1 Resumo
Após iteração contínua, a TDA desenvolveu basicamente capacidades de análise de autoatendimento completas e alcançou os seguintes indicadores:
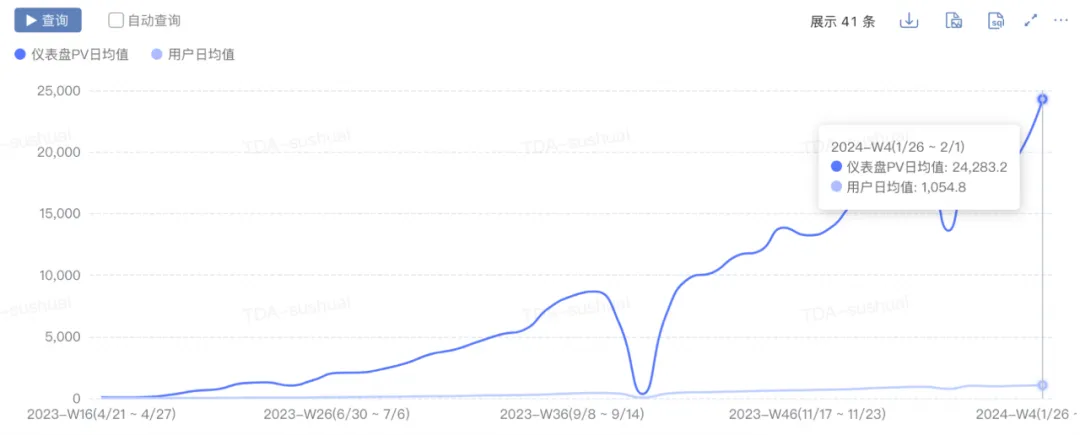
- Crescimento de escala: pv aumentou de 0 para 2w+, uv aumentou de 0 para 1000+ e novos gráficos diários aumentaram de 0 para 300+.
-
Melhoria de desempenho: O tempo necessário para atingir o percentil 90 da primeira tela do painel caiu de 10s+ para 5s.
-
Melhoria da eficiência empresarial: Promova uma taxa de autoatendimento de 80%+ do negócio principal, aumente a eficiência da análise de flutuação em 20 vezes e análise de atribuição ponta a ponta de flutuações de indicador único de 2 horas a 5 minutos.
3.2 Planejamento
Com a penetração da tecnologia nativa de IA em vários campos, a TDA também combinará a tecnologia de IA no futuro para aprimorar a experiência de análise inteligente da plataforma. Os pontos principais são os seguintes:
-
Acesso de autoatendimento aos dados: O acesso aos dados será liberalizado, os tipos de fontes de dados serão expandidos, etc.
-
AI+BI: recursos de BI, como análise de atribuição, análise incorporada e relatórios de análise, são combinados com IA de modelo grande para melhorar produtos de análise inteligente.
-
Cockpit de gerenciamento (Explorar): Painel de metas de OKR.
------FIM------
Leitura recomendada
Uma breve análise de como acelerar serviços comerciais em tempo real
Evolução do sistema de login, design e implementação de login conveniente
Este artigo lhe dará uma compreensão completa da biblioteca básica IO da linguagem Go
Reconciliação do sistema do Baidu Trading Center
Revelando o segredo do mecanismo de computação de fusão de data warehouse Baidu
A primeira grande atualização de versão do JetBrains 2024 (2024.1) é de código aberto. Até a Microsoft planeja pagar por isso. Por que ainda está sendo criticado por ser de código aberto? [Recuperado] O back-end do Tencent Cloud travou: um grande número de erros de serviço e nenhum dado após o login no console. A Alemanha também precisa ser "controlável de forma independente". O governo estadual migrou 30.000 PCs do Windows para o Linux deepin-IDE e finalmente conseguiu inicialização! O Visual Studio Code 1.88 foi lançado. Bom rapaz, a Tencent realmente transformou o Switch em uma "máquina de aprendizagem pensante". A área de trabalho remota RustDesk inicia e reconstrói o cliente Web. O banco de dados de terminal de código aberto do WeChat baseado em SQLite, WCDB, recebeu uma grande atualização.