Postei alguns vídeos antes para simplesmente demonstrar o efeito da interpretação simultânea (a placa gráfica é Tesla P40, o efeito é relativamente ruim, mas a função está ok)
Vrchat tenta tradução em tempo real e saída de voz_bilibili_bilibili
Anote as ideias de implementação e configurações relacionadas (você pode usar outro software ou sites com base nas ideias)
Claro, este conjunto também pode ser usado em outro software ou em VR.

Pré-ambiente
A placa gráfica usada localmente é a Tesla P40.
Ubuntu 22.04.3LTS
gerenciamento de condomínio,
python3.9.16,
Um proxy está configurado no servidor
Como o streaming contínuo usa ws, https é necessário para acesso remoto, então você precisa usar o certificado autoassinado openssl e, em seguida, abrir um proxy reverso. (A implantação de streaming contínuo não é descrita nesta nota. Aqui descrevemos principalmente as ideias e métodos de aplicação prática)
software crítico
1. Voice Meeter (microfone de conversão de voz)
2. O método de entrada Sogou Pinyin (eu não esperava) traduz línguas estrangeiras para chinês em tempo real
3. Streaming contínuo, você precisa construí-lo sozinho ou usar outros serviços TTS em tempo real (whisper desktop + NetEase Monster ou latido, etc., mas acho que basicamente não há conversão contínua de websocket, você precisa falar e clicar no microfone você mesmo) ou pague para usar o Microsoft O tipo de tradução (ainda não estudei)
4. (Opcional) Trocador de voz, usei o trocador de voz que requer modelo sovits
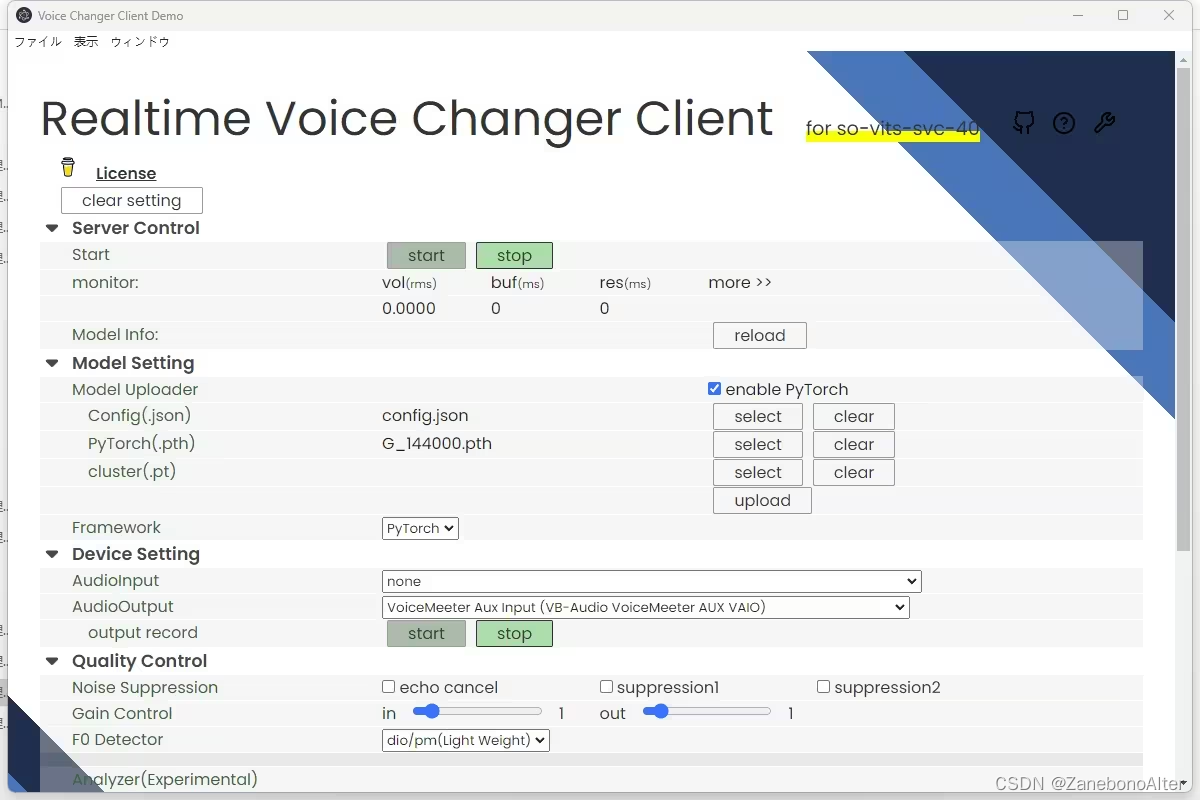
5.
Se precisar de um trocador de voz, você pode procurá-lo no site B. Existem muitos tutoriais.
Entrada (Tradução de Língua Estrangeira Chinês)

O processo de conversão de entrada
é simplesmente vrchat-> voice meeter-> método de entrada Sogou Pinyin entrada de voz-> arquivo txt
O foco está na configuração do voice meeter e vrchat
configuração de som vrchat
Configuração de som 1.vrchat
Esta configuração de som está em Sistema-> Som-> Sintetizador de Volume

2. configuração do encontro de voz
Se quiser mudar sua voz, use a versão fotográfica (três placas de som virtuais), caso contrário, banana serve, 2 placas de som virtuais

Para a configuração do voice meeter,
basta olhar o primeiro.
Marcar A2 indica que o som deve ser enviado para a placa de som física, que é a placa de som configurada com A2 à direita. Escolhi fones de ouvido aqui porque quero ouvir o som original.
Marcar B1 significa que o Voice Meeter converte o som para o Voice Meeter VAIO OUTPUT, o driver do microfone virtual. A propósito, B2 corresponde à SAÍDA AUX do microfone virtual e B3 corresponde à SAÍDA VAIO3.
Referência de depuração de configuração
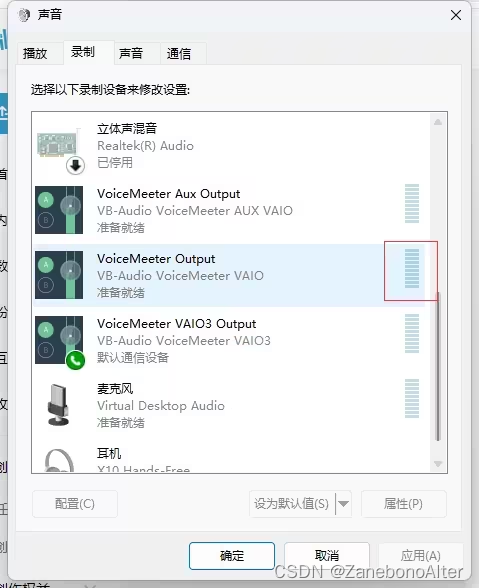
Após a configuração ser bem-sucedida, se o volume flutuar, haverá uma saída correspondente.
3. Configure a entrada do Sogou

Dessa forma, o som é transmitido para Sogou (na verdade, você mesmo pode tentar. Gravei o vídeo originalmente, mas depois de pensar nisso resolvi digitá-lo)
Saída (fale chinês para inglês, com base em streaming contínuo)
Processo de implementação
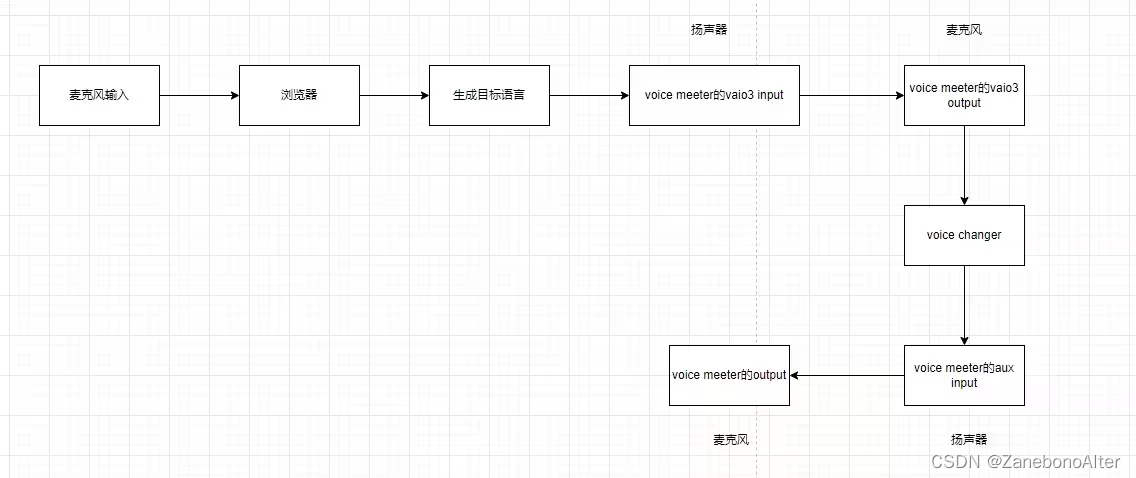

Em relação à instalação do streaming contínuo, basta seguir o leia-me oficial do meta, e então você só precisa saber um pouco de python.
O endereço é https://huggingface.co/spaces/facebook/seamless-streaming/tree/main.O
projeto vem com um arquivo leia-me.
A propósito, esse streaming contínuo pode realmente traduzir emoções (mas você precisa solicitar um modelo), e o latido alternativo também está disponível.
Depois, há a configuração de som do navegador ( se você estiver usando VR, basta alterar a entrada externa para o desktop virtual ou fone de ouvido Oculus )

Mostrar a configuração do Vocie Meeter novamente
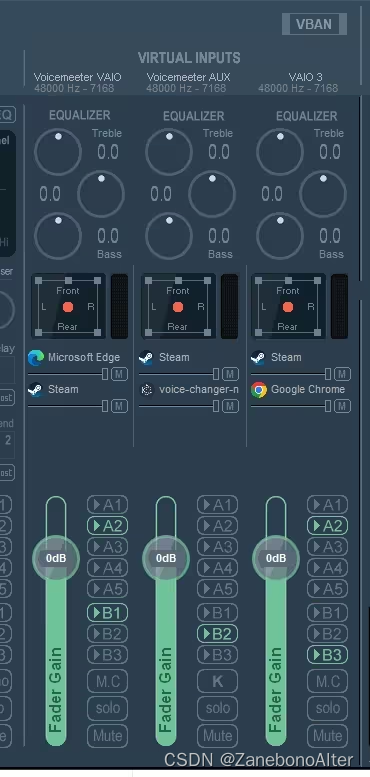
A configuração do Voice Meeter
está basicamente concluída aqui. Você pode ir diretamente para configurar o microfone no vrchat.

Claro, ao usar o VAIO3
, um homem como eu vai acrescentar mais uma coisa, que é a configuração do trocador de voz.

Configuração do cliente de troca de voz
Claro, o microfone no vrchat também deve ser alterado

Use o
efeito auxiliar para experimentar você mesmo! (É que a voz está um pouco demente)